-
-
-
-
-
-
-
Walkthrough - Building a Splunk Search
-
-
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Walkthrough: Building a Splunk Search
The following walkthroughs illustrate how to build a Splunk search from scratch.
Scenario: we want to identify users who launch a specific executable more often than n times in a given time range.
Splunk SPL Search
Let’s build the Splunk SPL search step by step.
Step 1
We start with all events from uberAgent’s index.
Note: to facilitate changing the index name used by uberAgent, all our dashboards make use of the uberAgent_index macro which contains the actual index name. The macro is defined in macros.conf of the uberAgent searchhead app.
index=`uberAgent_index`
<!--NeedCopy-->
Step 2
We filter for the process startup sourcetype which contains one event per started process.
Note: The documentation of uberAgent’s sourcetypes and fields can be found here.
index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup
<!--NeedCopy-->
Step 3
We ignore processes started by SYSTEM, LOCAL SERVICE and NETWORK SERVICE.
Note: The pseudo-users sys, lvc and nvc are defined in the lookup table systemusers.csv of the uberAgent searchhead app. They are auto-expanded to the proper user names SYSTEM, LOCAL SERVICE and NETWORK SERVICE in uberAgent’s data model.
index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup ProcUser!=sys ProcUser!=lvc ProcUser!=nvc
<!--NeedCopy-->
Step 4
We add a filter for the name of the process we are interested in, Winword.exe in this example.
index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup ProcUser!=sys ProcUser!=lvc ProcUser!=nvc ProcName=Winword.exe
<!--NeedCopy-->
Step 5
We count the number of (start) events per user.
Note: The only purpose of adding the field ProcName to the stats command is to make it part of the results table, too.
index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup ProcUser!=sys ProcUser!=lvc ProcUser!=nvc ProcName=Winword.exe
| stats count as Starts by ProcName ProcUser
<!--NeedCopy-->
Step 6
We only keep users with more than five starts in the results list.
index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup ProcUser!=sys ProcUser!=lvc ProcUser!=nvc ProcName=Winword.exe
| stats count as Starts by ProcName ProcUser
| where Starts > 5
<!--NeedCopy-->
Step 7
We rename fields to make them look nicer.
index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup ProcUser!=sys ProcUser!=lvc ProcUser!=nvc ProcName=Winword.exe
| stats count as Starts by ProcName ProcUser
| where Starts > 5
| rename ProcUser as User ProcName as Process
<!--NeedCopy-->
Step 8
We sort the results so that the user with the highest number of starts is listed first. The 0 in the sort command ensures that the output is not truncated after the 10,000th result.
index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup ProcUser!=sys ProcUser!=lvc ProcUser!=nvc ProcName=Winword.exe
| stats count as Starts by ProcName ProcUser
| where Starts > 5
| rename ProcUser as User ProcName as Process
| sort 0 -Starts
<!--NeedCopy-->
The Result
This is what the final Splunk SPL search for users with more than five starts of Winword.exe looks like. The screenshot below shows the search being run over the past 30 days. In practice, you would adjust the time range to any relevant time interval.
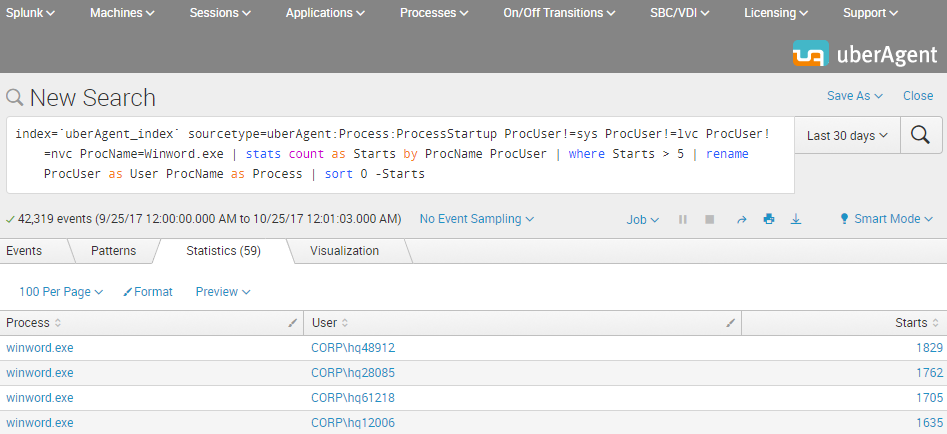
Accelerated Data Model Search
uberAgent comes with an accelerated data model. Searching an accelerated data model is a lot faster than searching the underlying index (by "a lot" we mean at least 50x), but requires a different search syntax based on the pivot or tstats commands. We are using pivot because of the easier syntax compared to tstats.
In this second example, we demonstrate how to search for starts of a "modern" UWP app, specifically the weather app that is part of Windows. Most UWP apps cannot be identified by process name - which is simply backgroundTaskHost.exe. Luckily uberAgent determines the real app name automatically.
Step 1
We start with a count of all process starts.
Note: The documentation for the Splunk pivot command can be found here.
Note: the macro uA_DM_Process_ProcessStartup resolves to the name of the data model containing the Process_ProcessStartup dataset. We use this technique to facilitate moving datasets between data models.
| pivot `uA_DM_Process_ProcessStartup` Process_ProcessStartup count(Process_ProcessStartup) as Starts
<!--NeedCopy-->
Step 2
We filter for the weather app.
Note: An easy way to identify the name of the weather app is to dig around with a search like the following: index=`uberAgent_index` sourcetype=uberAgent:Process:ProcessStartup AppName=*Weather*
| pivot `uA_DM_Process_ProcessStartup` Process_ProcessStartup count(Process_ProcessStartup) as Starts
filter AppName is "Microsoft.BingWeather"
<!--NeedCopy-->
Step 3
We split by user so that we get a count of process starts per user (renaming the ProcUser field to User in the process).
| pivot `uA_DM_Process_ProcessStartup` Process_ProcessStartup count(Process_ProcessStartup) as Starts
filter AppName is "Microsoft.BingWeather"
splitrow ProcUser as User
<!--NeedCopy-->
Step 4
We only keep users with more than five starts in the results list. We also sort the results so that the user with the highest number of starts is listed first. The 0 in the sort command ensures that the output is not truncated after the 10,000th result.
| pivot `uA_DM_Process_ProcessStartup` Process_ProcessStartup count(Process_ProcessStartup) as Starts
filter AppName is "Microsoft.BingWeather"
splitrow ProcUser as User
| where Starts > 5
| sort 0 -Starts
<!--NeedCopy-->
Step 5
We add the application name as a row to the results table.
| pivot `uA_DM_Process_ProcessStartup` Process_ProcessStartup count(Process_ProcessStartup) as Starts latest(AppName) as Application
filter AppName is "Microsoft.BingWeather"
splitrow ProcUser as User
| where Starts > 5
| sort 0 -Starts
| table Application User Starts
<!--NeedCopy-->
The Result
The resulting output is very similar to the first example above: a table with the application, the users and the number of starts that can easily be exported to CSV or otherwise be processed further.
Share
Share
In this article
This Preview product documentation is Citrix Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Citrix Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Citrix product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.