-
-
Solución nativa en la nube de NetScaler
-
Utilice NetScaler ADM para solucionar problemas de redes nativas en la nube de NetScaler
-
Implementar una instancia de NetScaler VPX
-
Optimice el rendimiento de NetScaler VPX en VMware ESX, Linux KVM y Citrix Hypervisors
-
Mejore el rendimiento de SSL-TPS en plataformas de nube pública
-
Configurar subprocesos múltiples simultáneos para NetScaler VPX en nubes públicas
-
Instalar una instancia de NetScaler VPX en un servidor desnudo
-
Instalar una instancia de NetScaler VPX en Citrix Hypervisor
-
Instalación de una instancia de NetScaler VPX en VMware ESX
-
Configurar NetScaler VPX para usar la interfaz de red VMXNET3
-
Configurar NetScaler VPX para usar la interfaz de red SR-IOV
-
Configurar NetScaler VPX para usar Intel QAT para la aceleración de SSL en modo SR-IOV
-
Migración de NetScaler VPX de E1000 a interfaces de red SR-IOV o VMXNET3
-
Configurar NetScaler VPX para usar la interfaz de red de acceso directo PCI
-
-
Instalación de una instancia NetScaler VPX en la nube de VMware en AWS
-
Instalación de una instancia NetScaler VPX en servidores Microsoft Hyper-V
-
Instalar una instancia de NetScaler VPX en la plataforma Linux-KVM
-
Requisitos previos para instalar dispositivos virtuales NetScaler VPX en la plataforma Linux-KVM
-
Aprovisionamiento del dispositivo virtual NetScaler mediante OpenStack
-
Aprovisionamiento del dispositivo virtual NetScaler mediante Virtual Machine Manager
-
Configuración de dispositivos virtuales NetScaler para que usen la interfaz de red SR-IOV
-
Configuración de dispositivos virtuales NetScaler para que usen la interfaz de red PCI Passthrough
-
Aprovisionamiento del dispositivo virtual NetScaler mediante el programa virsh
-
Administración de las máquinas virtuales invitadas de NetScaler
-
Aprovisionamiento del dispositivo virtual NetScaler con SR-IOV en OpenStack
-
-
Implementar una instancia de NetScaler VPX en AWS
-
Configurar las funciones de IAM de AWS en la instancia de NetScaler VPX
-
Implementación de una instancia independiente NetScaler VPX en AWS
-
Servidores de equilibrio de carga en diferentes zonas de disponibilidad
-
Implementar un par de alta disponibilidad de VPX en la misma zona de disponibilidad de AWS
-
Alta disponibilidad en diferentes zonas de disponibilidad de AWS
-
Implementar un par de alta disponibilidad VPX con direcciones IP privadas en distintas zonas de AWS
-
Implementación de una instancia NetScaler VPX en AWS Outposts
-
Proteja AWS API Gateway mediante el firewall de aplicaciones web de Citrix
-
Configurar una instancia de NetScaler VPX para utilizar la interfaz de red SR-IOV
-
Configurar una instancia de NetScaler VPX para utilizar redes mejoradas con AWS ENA
-
Implementar una instancia de NetScaler VPX en Microsoft Azure
-
Arquitectura de red para instancias NetScaler VPX en Microsoft Azure
-
Configuración de varias direcciones IP para una instancia independiente NetScaler VPX
-
Configurar una configuración de alta disponibilidad con varias direcciones IP y NIC
-
Configurar una instancia de NetScaler VPX para usar redes aceleradas de Azure
-
Configure los nodos HA-INC mediante la plantilla de alta disponibilidad de NetScaler con Azure ILB
-
Instalación de una instancia NetScaler VPX en la solución Azure VMware
-
Configurar una instancia independiente de NetScaler VPX en la solución Azure VMware
-
Configurar una instalación de alta disponibilidad de NetScaler VPX en la solución Azure VMware
-
Configurar el servidor de rutas de Azure con un par de alta disponibilidad de NetScaler VPX
-
Configurar GSLB en una configuración de alta disponibilidad activa en espera
-
Configuración de grupos de direcciones (IIP) para un dispositivo NetScaler Gateway
-
Scripts de PowerShell adicionales para la implementación de Azure
-
Implementación de una instancia NetScaler VPX en Google Cloud Platform
-
Implementar un par de VPX de alta disponibilidad en Google Cloud Platform
-
Implementar un par de alta disponibilidad VPX con direcciones IP privadas en Google Cloud Platform
-
Instalar una instancia de NetScaler VPX en VMware Engine de Google Cloud
-
Compatibilidad con escalado VIP para la instancia NetScaler VPX en GCP
-
-
Automatizar la implementación y las configuraciones de NetScaler
-
Actualización y degradación de un dispositivo NetScaler
-
Consideraciones de actualización para configuraciones con directivas clásicas
-
Consideraciones sobre la actualización de archivos de configuración personalizados
-
Consideraciones sobre la actualización: Configuración de SNMP
-
Compatibilidad con actualización de software en servicio para alta disponibilidad
-
Soluciones para proveedores de servicios de telecomunicaciones
-
Equilibrio de carga del tráfico de plano de control basado en protocolos de diámetro, SIP y SMPP
-
Utilización del ancho de banda mediante la funcionalidad de redirección de caché
-
-
Autenticación, autorización y auditoría del tráfico de aplicaciones
-
Cómo funciona la autenticación, la autorización y la auditoría
-
Componentes básicos de la configuración de autenticación, autorización y auditoría
-
Autorización del acceso de los usuarios a los recursos de aplicaciones
-
NetScaler como proxy del servicio de federación de Active Directory
-
NetScaler Gateway local como proveedor de identidad de Citrix Cloud
-
Compatibilidad de configuración para el atributo de cookie SameSite
-
Configuración de autenticación, autorización y auditoría para protocolos de uso común
-
Solución de problemas relacionados con la autenticación y la autorización
-
-
-
-
Configurar una expresión de directiva avanzada: Cómo empezar
-
Expresiones de directiva avanzadas: trabajar con fechas, horas y números
-
Expresiones de directiva avanzadas: Análisis de datos HTTP, TCP y UDP
-
Expresiones de directiva avanzadas: análisis de certificados SSL
-
Expresiones de directivas avanzadas: direcciones IP y MAC, rendimiento, ID de VLAN
-
Expresiones de directivas avanzadas: funciones de análisis de transmisiones
-
Expresiones de directiva avanzadas que utilizan la especificación de API
-
Ejemplos de tutoriales de directivas avanzadas para la reescritura
-
-
-
Protecciones de nivel superior
-
Protección basada en gramática SQL para cargas útiles HTML y JSON
-
Protección basada en gramática por inyección de comandos para carga útil HTML
-
Reglas de relajación y denegación para gestionar ataques de inyección HTML SQL
-
Compatibilidad con palabras clave personalizadas para la carga útil HTML
-
Compatibilidad con firewall de aplicaciones para Google Web Toolkit
-
Comprobaciones de protección XML
-
Caso de uso: Vincular la directiva de Web App Firewall a un servidor virtual VPN
-
-
-
Administrar un servidor virtual de redirección de caché
-
Ver estadísticas del servidor virtual de redirección de caché
-
Habilitar o inhabilitar un servidor virtual de redirección de caché
-
Resultados directos de directivas a la caché en lugar del origen
-
Realizar una copia de seguridad de un servidor virtual de redirección de caché
-
Habilitar la comprobación de estado TCP externa para servidores virtuales UDP
-
-
Traducir la dirección IP de destino de una solicitud a la dirección IP de origen
-
-
Descripción general del cluster
-
Administración del clúster de NetScaler
-
Grupos de nodos para configuraciones detectadas y parcialmente rayadas
-
Desactivación de la dirección en el plano posterior del clúster
-
Eliminar un nodo de un clúster implementado mediante la agregación de vínculos de clúster
-
Supervisión de la configuración del clúster mediante SNMP MIB con enlace SNMP
-
Supervisión de los errores de propagación de comandos en una implementación de clúster
-
Compatibilidad con logotipos preparados para IPv6 para clústeres
-
Enlace de interfaz VRRP en un clúster activo de un solo nodo
-
Casos de configuración y uso de clústeres
-
Migración de una configuración de HA a una configuración de clúster
-
Interfaces comunes para cliente y servidor e interfaces dedicadas para backplane
-
Conmutador común para cliente y servidor y conmutador dedicado para placa posterior
-
Supervisar servicios en un clúster mediante la supervisión de rutas
-
-
Configurar NetScaler como un solucionador de stubs con reconocimiento de seguridad no validante
-
Compatibilidad con tramas gigantes para DNS para gestionar respuestas de grandes tamaños
-
Configurar el almacenamiento en caché negativo de los registros DNS
-
Caso de uso: Configurar la función de administración automática de claves de DNSSEC
-
Caso de uso: Configurar la administración automática de claves DNSSEC en la implementación de GSLB
-
-
Estado de servicio y servidor virtual de equilibrio de carga
-
Insertar atributos de cookie a las cookies generadas por ADC
-
Proteja una configuración de equilibrio de carga contra fallos
-
Administrar el tráfico de clientes
-
Configurar servidores virtuales de equilibrio de carga sin sesión
-
Reescritura de puertos y protocolos para la redirección HTTP
-
Insertar la dirección IP y el puerto de un servidor virtual en el encabezado de solicitud
-
Utilizar una IP de origen especificada para la comunicación de back-end
-
Establecer un valor de tiempo de espera para las conexiones de cliente inactivas
-
Gestionar el tráfico de clientes en función de la velocidad de tráfico
-
Utilizar un puerto de origen de un rango de puertos especificado para la comunicación de back-end
-
Configurar la persistencia IP de origen para la comunicación back-end
-
-
Configuración avanzada de equilibrio de carga
-
Aumenta gradualmente la carga en un nuevo servicio con un inicio lento a nivel de servidor virtual
-
Proteger aplicaciones en servidores protegidos contra los picos de tráfico
-
Habilitar la limpieza de las conexiones de servicios y servidores virtuales
-
Habilitar o inhabilitar la sesión de persistencia en los servicios TROFS
-
Habilitar la comprobación de estado TCP externa para servidores virtuales UDP
-
Mantener la conexión de cliente para varias solicitudes de cliente
-
Insertar la dirección IP del cliente en el encabezado de solicitud
-
Utilizar la dirección IP de origen del cliente al conectarse al servidor
-
Configurar el puerto de origen para las conexiones del lado del servidor
-
Establecer un límite en el número de solicitudes por conexión al servidor
-
Establecer un valor de umbral para los monitores enlazados a un servicio
-
Establecer un valor de tiempo de espera para las conexiones de clientes inactivas
-
Establecer un valor de tiempo de espera para las conexiones de servidor inactivas
-
Establecer un límite en el uso del ancho de banda por parte de los clientes
-
Conservar el identificador de VLAN para la transparencia de VLAN
-
-
Configurar monitores en una configuración de equilibrio de carga
-
Configurar el equilibrio de carga para los protocolos de uso común
-
Caso de uso 3: Configurar el equilibrio de carga en modo de Direct Server Return
-
Caso de uso 6: Configurar el equilibrio de carga en modo DSR para redes IPv6 mediante el campo TOS
-
Caso de uso 7: Configurar el equilibrio de carga en modo DSR mediante IP sobre IP
-
Caso de uso 8: Configurar el equilibrio de carga en modo de un brazo
-
Caso de uso 9: Configurar el equilibrio de carga en modo en línea
-
Caso de uso 10: Equilibrio de carga de los servidores del sistema de detección de intrusiones
-
Caso de uso 11: Aislamiento del tráfico de red mediante directivas de escucha
-
Caso de uso 12: Configurar Citrix Virtual Desktops para el equilibrio de carga
-
Caso de uso 13: Configurar Citrix Virtual Apps and Desktops para equilibrar la carga
-
Caso de uso 14: Asistente de ShareFile para equilibrar la carga Citrix ShareFile
-
Caso práctico 15: Configurar el equilibrio de carga de capa 4 en el dispositivo NetScaler
-
-
Configurar para obtener el tráfico de datos NetScaler FreeBSD desde una dirección SNIP
-
-
-
Matriz de compatibilidad de certificados de servidor en el dispositivo ADC
-
Compatibilidad con plataformas basadas en chip SSL Intel Coleto
-
Compatibilidad con el módulo de seguridad de hardware Thales Luna Network
-
-
-
-
Configuración de un túnel de CloudBridge Connector entre dos centros de datos
-
Configuración de CloudBridge Connector entre el centro de datos y la nube de AWS
-
Configuración de un túnel de CloudBridge Connector entre un centro de datos y Azure Cloud
-
Configuración del túnel CloudBridge Connector entre Datacenter y SoftLayer Enterprise Cloud
-
Diagnóstico y solución de problemas de túnel CloudBridge Connector
-
-
Puntos a tener en cuenta para una configuración de alta disponibilidad
-
Sincronizar archivos de configuración en una configuración de alta disponibilidad
-
Restricción del tráfico de sincronización de alta disponibilidad a una VLAN
-
Configuración de nodos de alta disponibilidad en distintas subredes
-
Limitación de las conmutaciones por error causadas por monitores de ruta en modo no INC
-
Configuración del conjunto de interfaces de conmutación por error
-
Administración de mensajes de latido de alta disponibilidad en un dispositivo NetScaler
-
Quitar y reemplazar un NetScaler en una configuración de alta disponibilidad
-
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Utilice NetScaler Console para solucionar problemas de redes nativas en la nube de NetScaler
Información general
Este documento proporciona información sobre cómo puede usar NetScaler Console para entregar y supervisar las aplicaciones de microservicios de Kubernetes. También se sumerge en el uso de la CLI, los gráficos de servicio y el seguimiento para permitir que los equipos de la plataforma y de SRE solucionen los problemas.
Descripción general de rendimiento y latencia de aplicaciones
Cifrado TLS
TLS es un protocolo de cifrado diseñado para proteger las comunicaciones por Internet. Un desafío mutuo TLS es el proceso que inicia una sesión de comunicación que utiliza el cifrado TLS. Durante un protocolo de enlace TLS, las dos partes que se comunican intercambian mensajes para reconocerse mutuamente, verificarse mutuamente, establecer los algoritmos de cifrado que utilizan y ponerse de acuerdo sobre las claves de sesión. Los apretones de manos de TLS son una parte fundamental del funcionamiento de HTTPS.
Apretones de manos TLS vs SSL
SSL (Secure Sockets Layer), fue el protocolo de cifrado original desarrollado para HTTP. TLS (Transport Layer Security) reemplazó a SSL hace algún tiempo. Los apretones de manos SSL ahora se denominan apretones de manos TLS, aunque el nombre “SSL” sigue siendo de uso generalizado.
¿Cuándo se produce un desafío mutuo TLS?
Se produce un desafío mutuo TLS cada vez que un usuario navega a un sitio web a través de HTTPS y el explorador comienza a consultar primero el servidor de origen del sitio web. Un desafío mutuo TLS también ocurre cuando cualquier otra comunicación utiliza HTTPS, incluidas las llamadas a la API y las consultas DNS a través de HTTPS.
Los apretones de manos TLS se producen después de que se ha abierto una conexión TCP mediante un protocolo de enlace TCP.
¿Qué ocurre durante un desafío mutuo de TLS?
- Durante un protocolo de enlace de TLS, el cliente y el servidor juntos hacen lo siguiente:
- Especifique qué versión de TLS (TLS 1.0, 1.2, 1.3, etc.) usan.
- Decida qué conjuntos de cifrado (consulte la siguiente sección) que utilizan.
- Autenticar la identidad del servidor a través de la clave pública del servidor y la firma digital de la entidad de certificación SSL.
- Genere claves de sesión para usar cifrado simétrico después de que se complete el desafío mutuo.
¿Cuáles son los pasos de un desafío mutuo TLS?
- Los apretones de manos TLS son una serie de datagramas o mensajes intercambiados por un cliente y un servidor. Un desafío mutuo TLS implica varios pasos, ya que el cliente y el servidor intercambian la información necesaria para completar el desafío mutuo y hacer posible una conversación posterior.
Los pasos exactos dentro de un protocolo de enlace TLS varían según el tipo de algoritmo de intercambio de claves utilizado y los conjuntos de cifrado admitidos por ambas partes. El algoritmo de intercambio de claves RSA se usa con mayor frecuencia. Va de la siguiente manera:
- El mensaje de “saludo del cliente”: el cliente inicia el desafío mutuo enviando un mensaje de “hola” al servidor. El mensaje incluye qué versión de TLS admite el cliente, las suites de cifrado admitidas y una cadena de bytes aleatorios conocida como “cliente aleatorio”.
- El mensaje de “saludo del servidor”: en respuesta al mensaje de saludo del cliente, el servidor envía un mensaje que contiene el certificado SSL del servidor, el conjunto de cifrado elegido por el servidor y el “servidor aleatorio”, otra cadena aleatoria de bytes que genera el servidor.
- Autenticación: El cliente verifica el certificado SSL del servidor con la entidad de certificación que lo emitió. Esto confirma que el servidor es quien dice ser y que el cliente interactúa con el propietario real del dominio.
- El secreto premaestro: El cliente envía una cadena aleatoria más de bytes, el “secreto premaestro”. El secreto premaestro se cifra con la clave pública y el servidor solo puede descifrarlo con la clave privada. (El cliente obtiene la clave pública del certificado SSL del servidor).
- Clave privada utilizada: el servidor descifra el secreto premaestro.
- Claves de sesión creadas: tanto el cliente como el servidor generan claves de sesión a partir del cliente aleatorio, el servidor aleatorio y el secreto premaestro. Deben llegar a los mismos resultados.
- El cliente está listo: el cliente envía un mensaje “finalizado” que se cifra con una clave de sesión.
- El servidor está listo: el servidor envía un mensaje “finalizado” cifrado con una clave de sesión.
- Cifrado simétrico seguro: se completa el desafío mutuo y la comunicación continúa utilizando las claves de sesión.
Todos los apretones de manos TLS utilizan cifrado asimétrico (la clave pública y la privada), pero no todos usan la clave privada en el proceso de generación de claves de sesión. Por ejemplo, un desafío mutuo efímero de Diffie-Hellman procede de la siguiente manera:
- Saludo del cliente: el cliente envía un mensaje de saludo al cliente con la versión del protocolo, el cliente aleatorio y una lista de conjuntos de cifrado.
- Saludos del servidor: el servidor responde con su certificado SSL, su conjunto de cifrado seleccionado y el servidor de forma aleatoria. A diferencia del protocolo de enlace RSA descrito en la sección anterior, en este mensaje el servidor también incluye lo siguiente (paso 3).
- Firma digital del servidor: el servidor utiliza su clave privada para cifrar el cliente de forma aleatoria, el servidor de forma aleatoria y su parámetro DH*. Estos datos cifrados funcionan como la firma digital del servidor, lo que establece que el servidor tiene la clave privada que coincide con la clave pública del certificado SSL.
- Firma digital confirmada: el cliente descifra la firma digital del servidor con la clave pública, verificando que el servidor controla la clave privada y es quien dice ser. Parámetro DH del cliente: el cliente envía su parámetro DH al servidor.
- El cliente y el servidor calculan el secreto premaestro: en lugar de que el cliente genere el secreto premaestro y lo envíe al servidor, como en un protocolo de enlace RSA, el cliente y el servidor utilizan los parámetros DH que intercambiaron para calcular un secreto premaestro coincidente por separado.
- Claves de sesión creadas: Ahora, el cliente y el servidor calculan las claves de sesión a partir del secreto premaestro, el aleatorio del cliente y el aleatorio del servidor, al igual que en un protocolo de enlace RSA.
- El cliente está listo: igual que un desafío mutuo de RSA
- El servidor está listo
- Encriptación simétrica segura
*Parámetro DH: DH significa Diffie-Hellman. El algoritmo Diffie-Hellman utiliza cálculos exponenciales para llegar al mismo secreto de premaster. El servidor y el cliente proporcionan un parámetro para el cálculo y, cuando se combinan, dan como resultado un cálculo diferente en cada lado, con resultados iguales.
Para obtener más información sobre el contraste entre los apretones de manos efímeros de Diffie-Hellman y otros tipos de apretones de manos, y cómo logran el secreto hacia adelante, consulte esta documentación del protocolo TLS.
¿Qué es un conjunto de cifrado?
- Un conjunto de cifrado es un conjunto de algoritmos de cifrado para su uso en el establecimiento de una conexión de comunicaciones segura. (Un algoritmo de cifrado es un conjunto de operaciones matemáticas que se realizan en los datos para hacer que los datos parezcan aleatorios). Hay varios conjuntos de cifrado de uso generalizado, y una parte esencial del desafío mutuo TLS es acordar qué conjunto de cifrado se usa para ese desafío mutuo.
Para empezar, consulte Referencia: documentación del protocolo TLS.
Panel SSL de NetScaler Application Delivery Management
NetScaler Application Delivery Management (ADM) ahora optimiza todos los aspectos de la administración de certificados para usted. A través de una sola consola, puede establecer directivas automatizadas para garantizar el emisor correcto, la fortaleza de la clave y los algoritmos correctos, al tiempo que mantiene una estrecha ficha sobre los certificados que no se utilizan o que caducan pronto. Para empezar a usar el panel SSL de NetScaler Console y sus funcionalidades, debe entender qué es un certificado SSL y cómo puede usar NetScaler Console para rastrear sus certificados SSL.
Un certificado Secure Socket Layer (SSL), que forma parte de cualquier transacción SSL, es un formulario de datos digitales (X509) que identifica a una empresa (dominio) o a un individuo. El certificado tiene un componente de clave pública visible para cualquier cliente que quiera iniciar una transacción segura con el servidor. La clave privada correspondiente, que reside de forma segura en el dispositivo Citrix Application Delivery Controller (ADC), se utiliza para completar el cifrado y descifrado de clave asimétrica (o clave pública).
Puede obtener un certificado y una clave SSL de cualquiera de las siguientes maneras:
- De una autoridad de certificación autorizada (CA)
- Al generar un nuevo certificado SSL y una clave en el dispositivo NetScaler
NetScaler Console proporciona una vista centralizada de los certificados SSL instalados en todas las instancias de NetScaler administradas. En el panel de control de SSL, puede ver gráficos que le ayudan a rastrear los emisores de certificados, los puntos fuertes clave, los algoritmos de firma, los certificados caducados o no utilizados, etc. También puede ver la distribución de los protocolos SSL que se ejecutan en sus servidores virtuales y las claves que están habilitadas en ellos.
También puede configurar notificaciones para informarle cuando los certificados están a punto de caducar e incluir información sobre las instancias NetScaler que utilizan dichos certificados.
Puede vincular los certificados de una instancia de NetScaler a un certificado de CA. Sin embargo, asegúrese de que los certificados que enlace al mismo certificado de CA tengan el mismo origen y el mismo emisor. Después de vincular los certificados a un certificado de CA, puede desvincularlos.
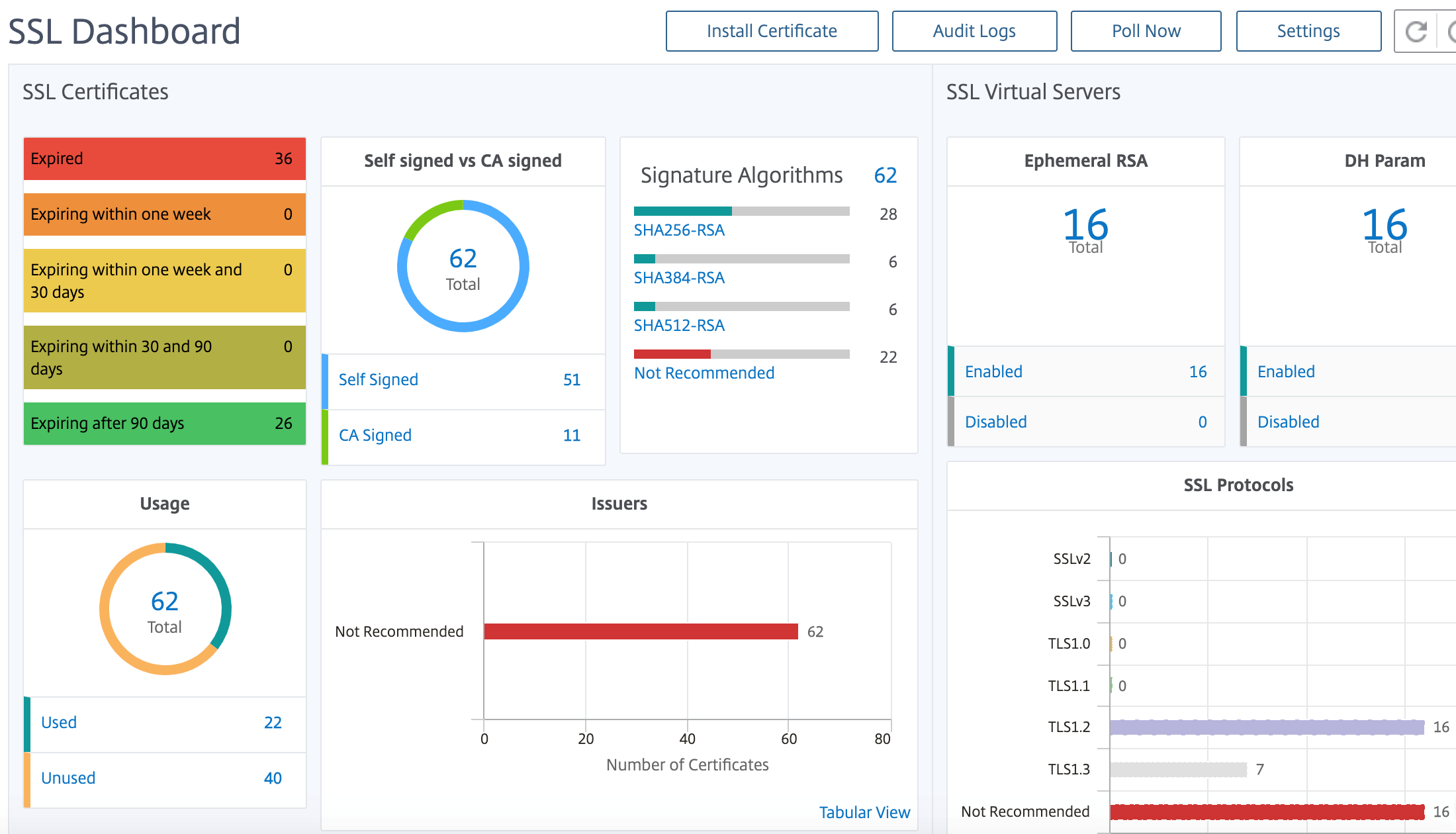
Para empezar, consulte la documentación del panel de SSL.
Integraciones de terceros
La latencia de la aplicación se mide en milisegundos y puede indicar una de dos cosas según la métrica utilizada. La forma más común de medir la latencia se llama “tiempo de ida y vuelta” (o RTT). El RTT calcula el tiempo que tarda un paquete de datos en viajar de un punto a otro de la red y para que una respuesta se envíe de vuelta al origen. La otra medición se denomina “tiempo hasta el primer byte” (o TTFB), que registra el tiempo que tarda desde el momento en que un paquete sale de un punto de la red hasta el momento en que llega a su destino. El RTT se usa más comúnmente para medir la latencia porque se puede ejecutar desde un solo punto de la red y no requiere que el software de recopilación de datos se instale en el punto de destino (como lo hace TTFB).
Al supervisar el uso y el rendimiento del ancho de banda de la aplicación en tiempo real, el servicio ADM facilita la identificación de problemas y el tratamiento preventivo de posibles problemas antes de que se manifiesten y afecten a los usuarios de su red. Esta solución basada en flujo hace un seguimiento del uso por interfaz, aplicación y conversación, lo que le brinda información detallada sobre la actividad en su red.
Uso de herramientas de Splunk
El rendimiento de la infraestructura y las aplicaciones es interdependiente. Para ver el panorama completo, SignalFx proporciona una correlación perfecta entre la infraestructura de la nube y los microservicios que se ejecutan en la parte superior de la misma. Si su aplicación funciona mal debido a una pérdida de memoria, a un contenedor vecino ruidoso o a cualquier otro problema relacionado con la infraestructura, SignalFx se lo informa. Para completar el panorama, el acceso en contexto a los registros y eventos de Splunk permite una solución de problemas más profunda y un análisis de la causa raíz.
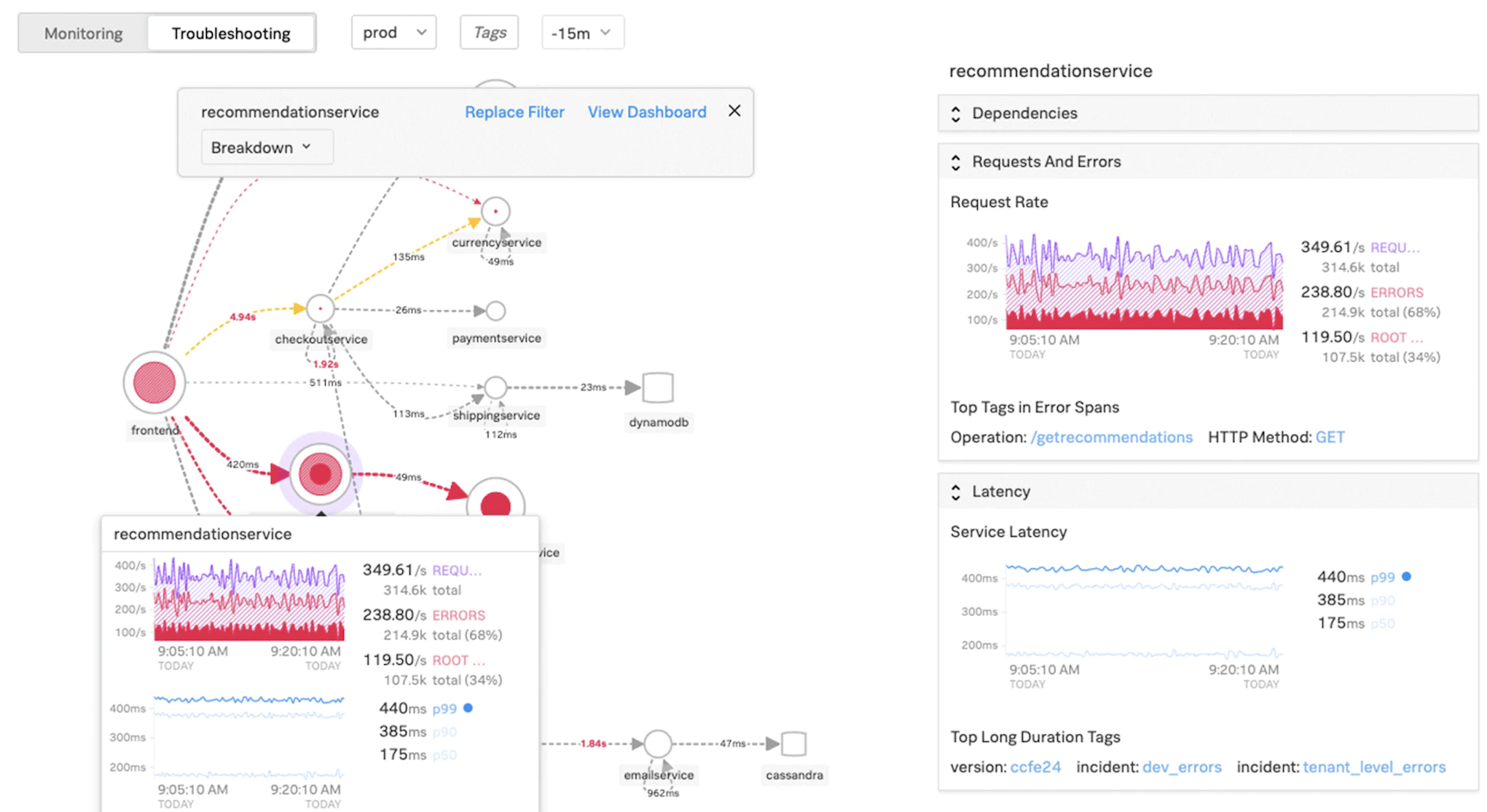
Para obtener más información sobre la APM de microservicios SignalFx y la solución de problemas con Splunk, consulte Splunk para obtener información sobre DevOps.
Compatibilidad con MongoDB
MongoDB almacena los datos en documentos flexibles similares a JSON. Los campos de significado pueden variar de un documento a otro y la estructura de los datos se puede cambiar con el tiempo.
El modelo de documento se asigna a los objetos del código de la aplicación, lo que facilita el trabajo con los datos.
Las consultas bajo demanda, la indexación y la agregación en tiempo real proporcionan formas eficaces de acceder a sus datos y analizarlos.
MongoDB es una base de datos distribuida en su núcleo, por lo que la alta disponibilidad, el escalado horizontal y la distribución geográfica están integradas y son fáciles de usar.
MongoDB está diseñado para satisfacer las demandas de las aplicaciones modernas con una base tecnológica que le permite:
- El modelo de datos de documentos: le presenta la mejor manera de trabajar con datos.
- Un diseño de sistemas distribuidos, que le permite colocar los datos de manera inteligente donde lo quiere.
- Una experiencia unificada que le da la libertad de funcionar en cualquier lugar, lo que le permite preparar su trabajo para el futuro y eliminar la dependencia de los proveedores.
Con estas capacidades, puede crear una plataforma de datos operativos inteligente, respaldada por MongoDB. Para obtener más información, consulte la documentación de MongoDB.
Cómo equilibrar la carga del tráfico de entrada a una aplicación basada en TCP o UDP
En un entorno de Kubernetes, un Ingress es un objeto que permite el acceso a los servicios de Kubernetes desde fuera del clúster de Kubernetes. Los recursos estándar de Kubernetes Ingress asumen que todo el tráfico se basa en HTTP y no atiende a protocolos no basados en HTTP, como TCP, TCP-SSL y UDP. Por lo tanto, las aplicaciones críticas basadas en protocolos L7, como DNS, FTP o LDAP, no se pueden exponer mediante Kubernetes Ingress estándar.
La solución estándar de Kubernetes consiste en crear un servicio de tipo LoadBalancer. Consulte LoadBalancer de tipos de servicio en NetScaler para obtener más información.
La segunda opción es anotar el objeto de entrada. El Ingress Controller NetScaler le permite equilibrar la carga del tráfico de ingreso basado en TCP o UDP. Proporciona las siguientes anotaciones que puede usar en la definición de recursos de Kubernetes Ingress para equilibrar la carga del tráfico de entrada basado en TCP o UDP:
- ingress.citrix.com/insecure-service-type: La anotación habilita el equilibrio de carga L4 con TCP, UDP o ANY como protocolo para NetScaler.
- ingress.citrix.com/insecure-port: La anotación configura el puerto TCP. La anotación es útil cuando se requiere acceso a microservicios en un puerto no estándar. De forma predeterminada, se configura el puerto 80.
Para obtener más información, consulte Cómo equilibrar la carga del tráfico de entrada a una aplicación basada en TCP o UDP.
Supervise y mejore el rendimiento de sus aplicaciones basadas en TCP o UDP
Los desarrolladores de aplicaciones pueden supervisar de cerca el estado de las aplicaciones basadas en TCP o UDP a través de monitores enriquecidos (como TCP-ECV, UDP-ECV) en NetScaler. La ECV (validación de contenido extendida) supervisa la ayuda para verificar si la aplicación devuelve el contenido esperado o no.
Además, el rendimiento de la aplicación se puede mejorar mediante el uso de métodos de persistencia, como la IP de origen. Puede usar estas funciones de NetScaler a través de anotaciones inteligentes en Kubernetes. A continuación se muestra un ejemplo de ello:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: mongodb
annotations:
ingress.citrix.com/insecure-port: “80”
ingress.citrix.com/frontend-ip: “192.168.1.1”
ingress.citrix.com/csvserver: ‘{“l2conn”:”on”}’
ingress.citrix.com/lbvserver: ‘{“mongodb-svc”:{“lbmethod”:”SRCIPDESTIPHASH”}}’
ingress.citrix.com/monitor: ‘{“mongodbsvc”:{“type”:”tcp-ecv”}}’
Spec:
rules:
- host: mongodb.beverages.com
http:
paths:
- path: /
backend:
serviceName: mongodb-svc
servicePort: 80
<!--NeedCopy-->
Servicio de administración de entrega de aplicaciones (ADM) de NetScaler
El servicio de consola NetScaler ofrece las siguientes ventajas:
- Ágil: Fácil de operar, actualizar y consumir. El modelo de servicio de NetScaler Console Service está disponible en la nube, lo que facilita el funcionamiento, la actualización y el uso de las funciones proporcionadas. La frecuencia de las actualizaciones, combinada con la función de actualización automatizada, mejora rápidamente la implementación de NetScaler.
- Tiempo de obtención de valor más rápido: Logro de objetivos empresariales más rápido. A diferencia de la implementación local tradicional, puede usar el servicio de consola de NetScaler con unos pocos clics. No solo ahorra tiempo de instalación y configuración, sino que también evita perder tiempo y recursos en posibles errores.
- Administración de varios sitios: Un solo panel de vidrio para instancias en centros de datos de varios sitios. Con el servicio de consola de NetScaler, puede administrar y supervisar los NetScaler que se encuentran en varios tipos de implementaciones. Dispone de una gestión integral para los NetScalers implementados en las instalaciones y en la nube.
- Eficiencia operativa: Forma optimizada y automatizada de lograr una mayor productividad operativa. Con el servicio de consola NetScaler, sus costos operativos se reducen al ahorrar tiempo, dinero y recursos en el mantenimiento y la actualización de las implementaciones de hardware tradicionales.
Gráfico de servicio para aplicaciones Kubernetes
Con el gráfico de servicio para la función de aplicación nativa de la nube de NetScaler Console, puede:
- Garantice el performance general de las aplicaciones end-to-end
- Identifique los cuellos de botella creados por la interdependencia de los diferentes componentes de sus aplicaciones
- Reúna información sobre las dependencias de los diferentes componentes de sus aplicaciones
- Supervise los servicios dentro del clúster de Kubernetes
- Supervisa qué servicio tiene problemas
- Compruebe los factores que contribuyen a los problemas de rendimiento
- Ver la visibilidad detallada de las transacciones HTTP del servicio
- Analizar las métricas HTTP, TCP y SSL
Al visualizar estas métricas en NetScaler Console, puede analizar la causa raíz de los problemas y tomar las medidas de solución de problemas necesarias con mayor rapidez. El gráfico de servicios muestra sus aplicaciones en varios servicios de componentes. Estos servicios que se ejecutan dentro del clúster de Kubernetes pueden comunicarse con varios componentes dentro y fuera de la aplicación.
Para empezar, consulta Configurar el gráfico de servicios.
Gráfico de servicio para aplicaciones web de 3 niveles
Con la función de gráfico de servicio desde el panel de aplicación, puede ver:
- Detalles sobre cómo se configura la aplicación (con el servidor virtual de conmutación de contenido y el servidor virtual de equilibrio de carga)
- Para las aplicaciones GSLB, puede ver el centro de datos, la instancia de ADC, los servidores virtuales CS y LB
- Transacciones de extremo a extremo desde el cliente hasta el servicio
- La ubicación desde la que el cliente accede a la aplicación
- El nombre del centro de datos donde se procesan las solicitudes de cliente y las métricas NetScaler del centro de datos asociadas (solo para aplicaciones GSLB)
- Detalles de métricas para clientes, servicios y servidores virtuales
- Si los errores son del cliente o del servicio
- El estado del servicio, como Crítico, Revisadoy Bueno. NetScaler Console muestra el estado del servicio según el tiempo de respuesta del servicio y el recuento de errores.
- Crítico (rojo): Indica cuándo el tiempo promedio de respuesta del servicio es superior a 200 ms Y el recuento de errores es > 0
- Revisión (naranja): Indica si el tiempo promedio de respuesta del servicio es > 200 ms O el recuento de errores es > 0
- Bueno (verde): Indica que no hay errores y que el tiempo medio de respuesta del servicio es inferior a 200 ms
- El estado del cliente, como Crítico, Revisadoy Bueno. NetScaler Console muestra el estado del cliente según la latencia de la red del cliente y el recuento de errores.
- Crítico (rojo): indica si la latencia promedio de la red del cliente es > 200 ms Y el recuento de errores es > 0
- Revisión (naranja): Indica si la latencia promedio de la red del cliente es > 200 ms O el recuento de errores es > 0
- Bueno (verde): Indica que no hay ningún error y que la latencia media de la red del cliente es < 200 ms.
- El estado del servidor virtual, como Crítico, Revisadoy Correcto. NetScaler Console muestra el estado del servidor virtual en función de la puntuación de la aplicación.
- Crítico (rojo): Indica si la puntuación de la aplicación es inferior < 40
- Reseña (naranja): Indica si la puntuación de la aplicación está entre 40 y 75
- Bueno (verde): Indica cuando la puntuación de la aplicación es > 75
Puntos a tener en cuenta:
- En el gráfico de servicio solo se muestran los servidores virtuales de equilibrio de carga, conmutación de contenido y GSLB.
- Si ningún servidor virtual está enlazado a una aplicación personalizada, los detalles no se ven en el gráfico de servicio de la aplicación.
- Puede ver métricas para clientes y servicios en el gráfico de servicios solo si se producen transacciones activas entre servidores virtuales y aplicaciones web.
- Si no hay transacciones activas disponibles entre los servidores virtuales y la aplicación web, solo puede ver los detalles en el gráfico de servicio en función de los datos de configuración, como el equilibrio de carga, la conmutación de contenido, los servidores virtuales GSLB y los servicios.
- Las actualizaciones en la configuración de la aplicación pueden tardar 10 minutos en reflejarse en el gráfico de servicio.
Para obtener más información, consulte Gráfico de servicio para aplicaciones.
Para empezar, consulte la documentación de Service Graph.
Solución de problemas para los equipos NetScaler
Analicemos algunos de los atributos más comunes para solucionar problemas en la plataforma NetScaler y cómo estas técnicas de solución de problemas se aplican a las implementaciones de nivel 1 para topologías de microservicios.
NetScaler tiene una interfaz de línea de comandos (CLI) que muestra los comandos en tiempo real y es útil para determinar las configuraciones en tiempo de ejecución, la estática y la configuración de directivas. Esto se facilita mediante el comando “SHOW”.
SHOW: realizar operaciones CLI de ADC:
>Show running config (-summary -fullValues)
Ability to search (grep command)
>“sh running config | -i grep vserver”
Check the version.
>Show license
“sh license"
<!--NeedCopy-->
Mostrar estadísticas de SSL
>Sh ssl
System
Frontend
Backend
Encryption
<!--NeedCopy-->
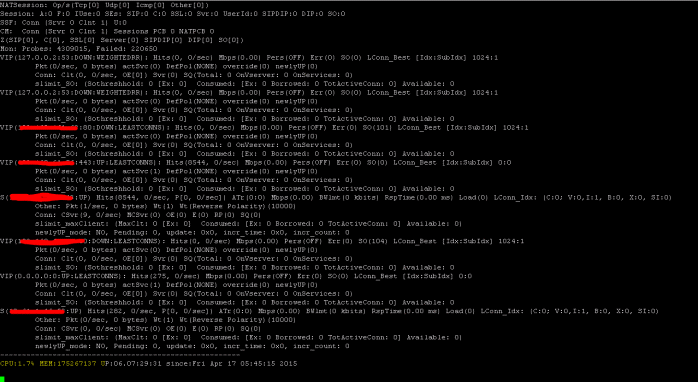
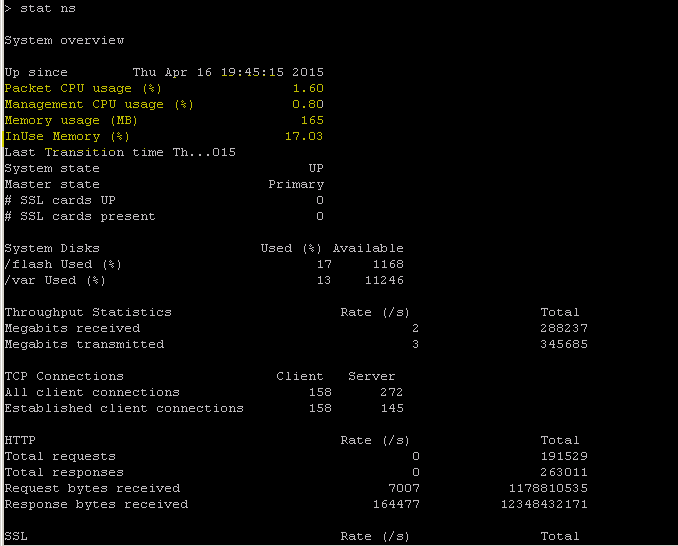
NetScaler tiene un comando para enumerar las estadísticas de todos los objetos en función de un intervalo de contador de siete (7) segundos. Esto se facilita mediante el comando “STAT”.
Telemetría L3-L7 altamente granular de NetScaler
- Nivel del sistema: uso de CPU y memoria del ADC.
- Protocolo HTTP: #Requests /Responses, división GET/POST, errores HTTP para N-S y E-W (solo para service mesh lite, sidecar pronto).
- SSL: #Sessions y #Handshakes para tráfico N-S y E-W solo para service mesh lite.
- Protocolo IP: #Packets recibidos/enviados, #Bytes recibidos/enviados, paquetes #Truncated y búsqueda de direcciones #IP.
- NetScaler AAA: Sesiones #Active
- Interfaz: paquetes de multidifusión #Total, bytes transferidos #Total y paquetes #Jumbo recibidos/enviados.
- Servidor virtual de equilibrio de carga y servidor virtual de conmutación de contenido: #Packets, #Hits y #Bytes recibidos/enviados.
STAT: realice operaciones CLI de ADC:
>Statistics
“stat ssl”
<!--NeedCopy-->
NetScaler tiene una estructura de archivo de registros que permite buscar estadísticas y contadores al solucionar errores específicos mediante el comando “NSCONMSG”.
NSCONMSG - archivo de registro principal (formato de datos ns)
Cd/var/nslog
“Mac Moves”
nsconmsg -d current -g nic_err
<!--NeedCopy-->
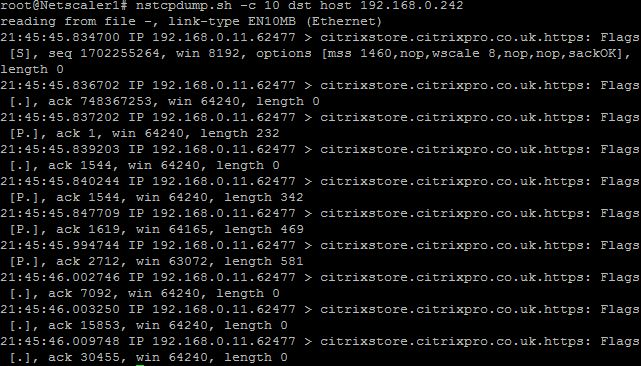
Nstcpdump
Se puede utilizar nstcpdump para la solución de problemas de bajo nivel. nstcpdump recopila información menos detallada que nstrace. Abra la CLI de ADC y escriba shell. Puede usar filtros con nstcpdump, pero no puede usar filtros específicos para los recursos ADC. La salida del volcado se puede ver directamente en la pantalla de la CLI.
CTRL + C: Presione estas teclas simultáneamente para detener un nstcpdump.
nstcpdump.sh dst host x.x.x.x — Muestra el tráfico enviado al host de destino.
nstcpdump.sh -n src host x.x.x.x — Muestra el tráfico del host especificado y no convierte las direcciones IP en nombres (-n).
nstcpdump.sh host x.x.x.x — Muestra el tráfico hacia y desde la IP del host especificada.
NSTRACE: Archivo de seguimiento de paquetes
NSTRACE es una herramienta de depuración de paquetes de bajo nivel para solucionar problemas de redes. Le permite almacenar archivos de captura que puede analizar más a fondo con las herramientas del analizador. Dos herramientas comunes son Network Analyzer y Wireshark.
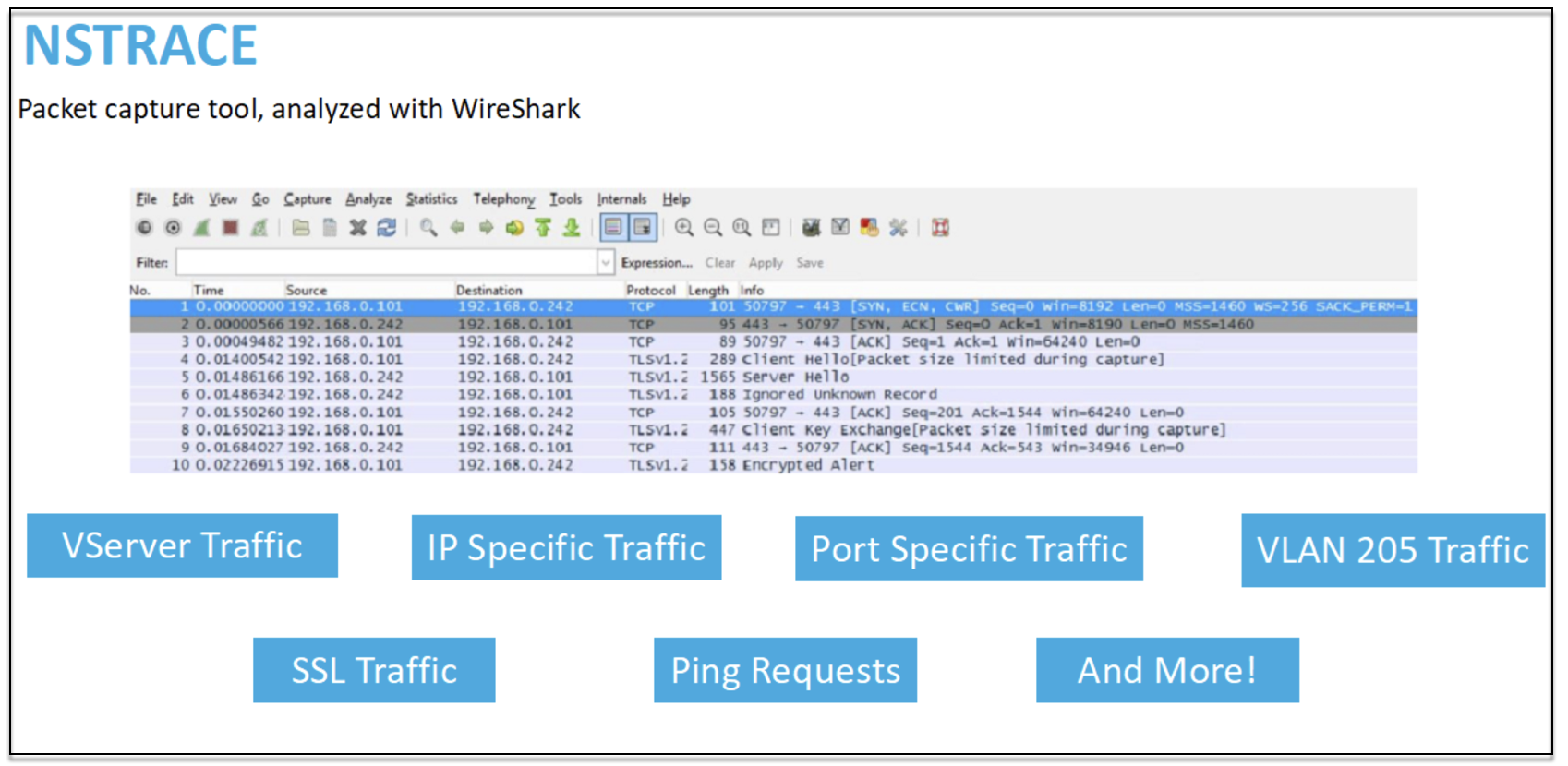
Una vez que se crea el archivo de captura NSTRACE en /var/nstrace en el ADC, puede importar el archivo de captura en Wireshark para la captura de paquetes y el análisis de red.
SYSCTL: Información detallada del ADC: descripción, modelo, plataforma, CPU, etc
sysctl -a grep hw.physmem
hw.physmem: 862306304
netscaler.hw_physmem_mb: 822
<!--NeedCopy-->
aaad.debug: Abrir proceso para información de depuración de autenticación

Para obtener más información sobre cómo solucionar problemas de autenticación a través de ADC o ADC Gateway con el módulo aaad.debug, consulte el artículo de asistencia de aaad.debug.
También existe la posibilidad de obtener estadísticas de rendimiento y registros de eventos directamente para el ADC. Para obtener más información al respecto, consulte el documento de asistencia de ADC.
Solución de problemas para los equipos de SRE
Flujos de tráfico de Kubernetes
Norte/sur:
- El tráfico norte/sur es el tráfico que fluye desde el usuario al clúster, a través de la entrada.
Este/oeste:
- El tráfico este/oeste es el tráfico que fluye por el clúster de Kubernetes: de servicio a servicio o de servicio a almacén de datos.
Cómo la carga de NetScaler CPX equilibra el flujo de tráfico de este a oeste en un entorno de Kubernetes
Después de implementar el clúster de Kubernetes, debe integrar el clúster con ADM proporcionando los detalles del entorno de Kubernetes en ADM. ADM supervisa los cambios en los recursos de Kubernetes, como los servicios, los puntos finales y las reglas de entrada.
Al implementar una instancia CPX de NetScaler en el clúster de Kubernetes, se registra automáticamente en ADM. Como parte del proceso de registro, ADM aprende sobre la dirección IP de la instancia CPX y el puerto en el que puede llegar a la instancia para configurarla mediante las API REST de NITRO.
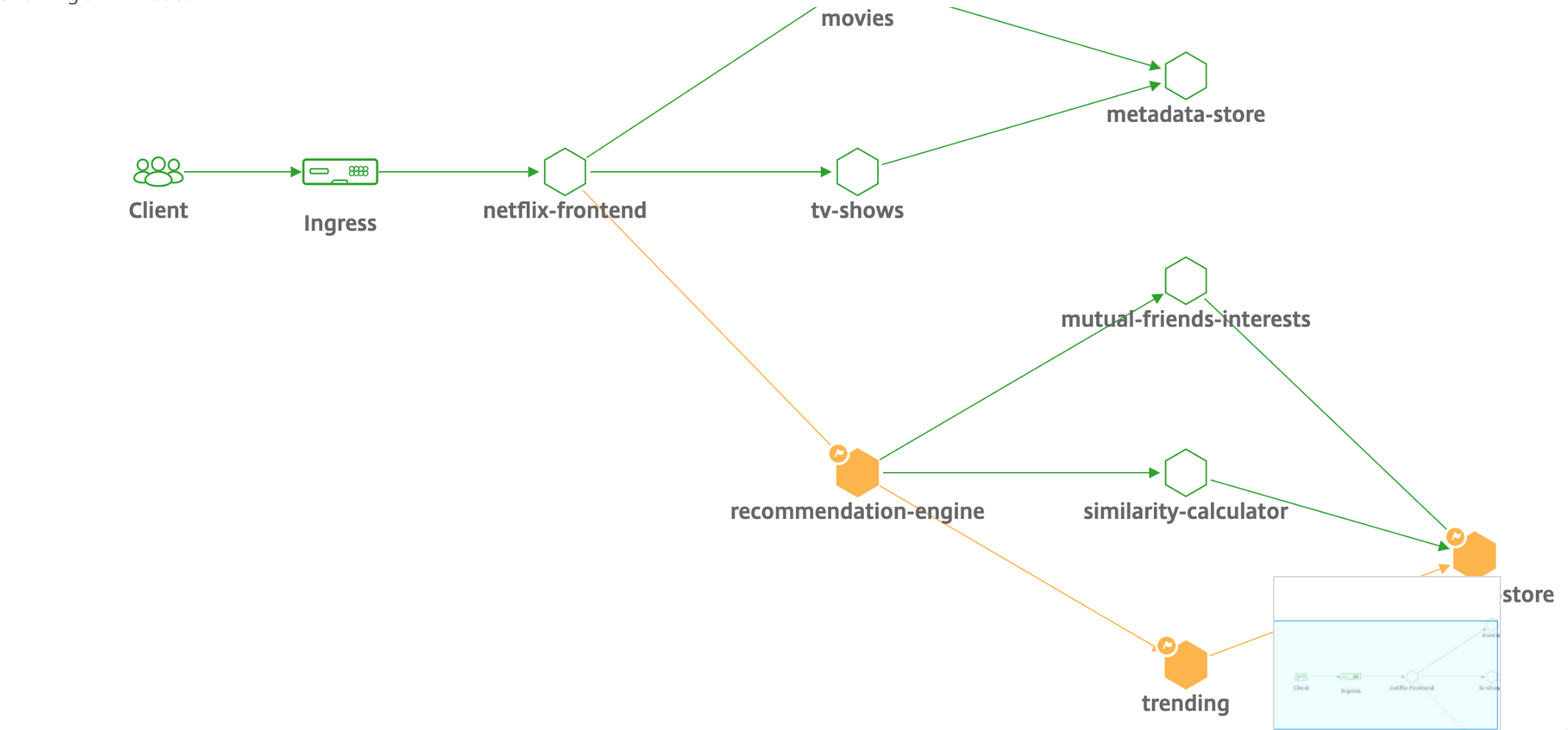
La siguiente figura muestra cómo NetScaler CPX equilibra la carga del flujo de tráfico de este a oeste en un clúster de Kubernetes.
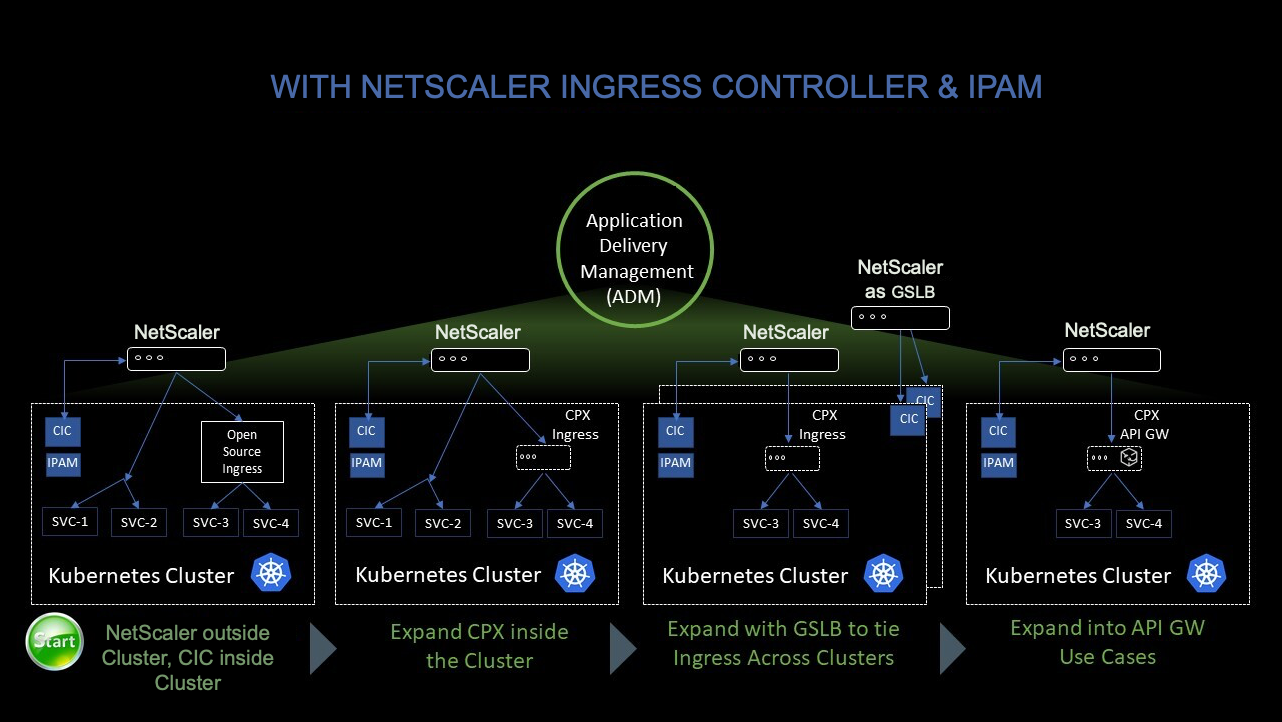
En este ejemplo,
El nodo 1 y el nodo 2 de los clústeres de Kubernetes contienen instancias de un servicio front-end y un servicio back-end. Cuando las instancias CPX de NetScaler se implementan en los nodos 1 y 2, las instancias CPX de NetScaler se registran automáticamente en ADM. Debe integrar manualmente el clúster de Kubernetes con ADM configurando los detalles del clúster de Kubernetes en ADM.
Cuando un cliente solicita el servicio front-end, la carga de recursos de entrada equilibra la solicitud entre las instancias del servicio front-end en los dos nodos. Cuando una instancia del servicio de front-end necesita información de los servicios de fondo del clúster, dirige las solicitudes a la instancia CPX de NetScaler de su nodo. La carga de esa instancia CPX de NetScaler equilibra las solicitudes entre los servicios de fondo del clúster, lo que proporciona un flujo de tráfico de este a oeste.
Gráfico de servicio ADM para aplicaciones
La función de gráfico de servicios de NetScaler Console le permite supervisar todos los servicios en una representación gráfica. Esta función también proporciona un análisis detallado y métricas útiles. Puede ver gráficos de servicios para:
- Aplicaciones configuradas en todas las instancias de NetScaler
- Aplicaciones de Kubernetes
- Aplicaciones web de 3 niveles
Para empezar, consulte los detalles en el gráfico de servicios.
Ver contadores de aplicaciones de microservicios
El gráfico de servicio también muestra todas las aplicaciones de microservicios que pertenecen a los clústeres de Kubernetes. Sin embargo, el puntero del mouse en un servicio para ver los detalles de las métricas.
Podrá ver lo siguiente:
- El nombre del servicio
- El protocolo utilizado por el servicio como SSL, HTTP, TCP, SSL sobre HTTP
- Visitas: Número total de visitas recibidas por el servicio
- Tiempo de respuesta del servicio: El tiempo de respuesta promedio tomado del servicio. (Tiempo de respuesta = RTT del cliente + último byte de la solicitud — primer byte de la solicitud)
- Errores: El total de errores, como 4xx, 5xx, etc.
- Volumen de datos: El volumen total de datos procesados por el servicio
- Espacio de nombres: El espacio de nombres del servicio
- Nombre del clúster: Nombre del clúster en el que está alojado el servicio
- Errores del servidor SSL: El total de errores SSL del servicio
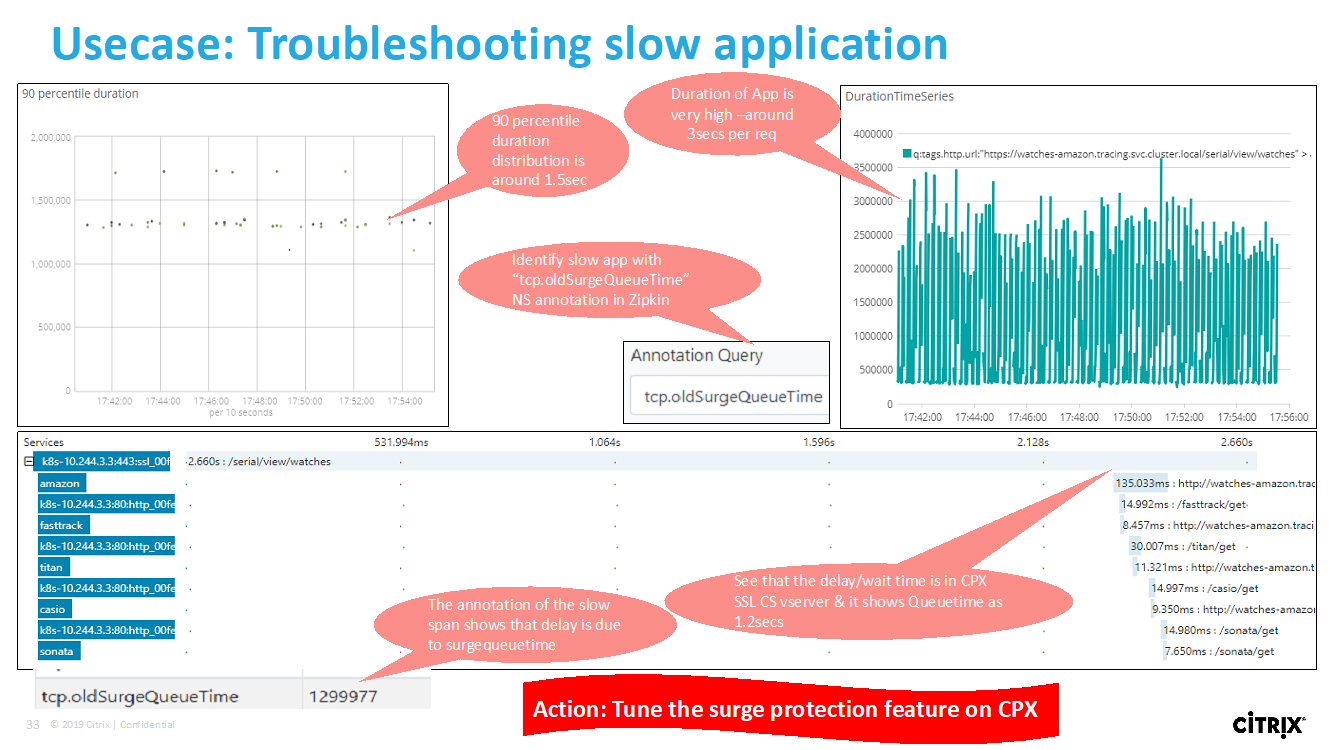
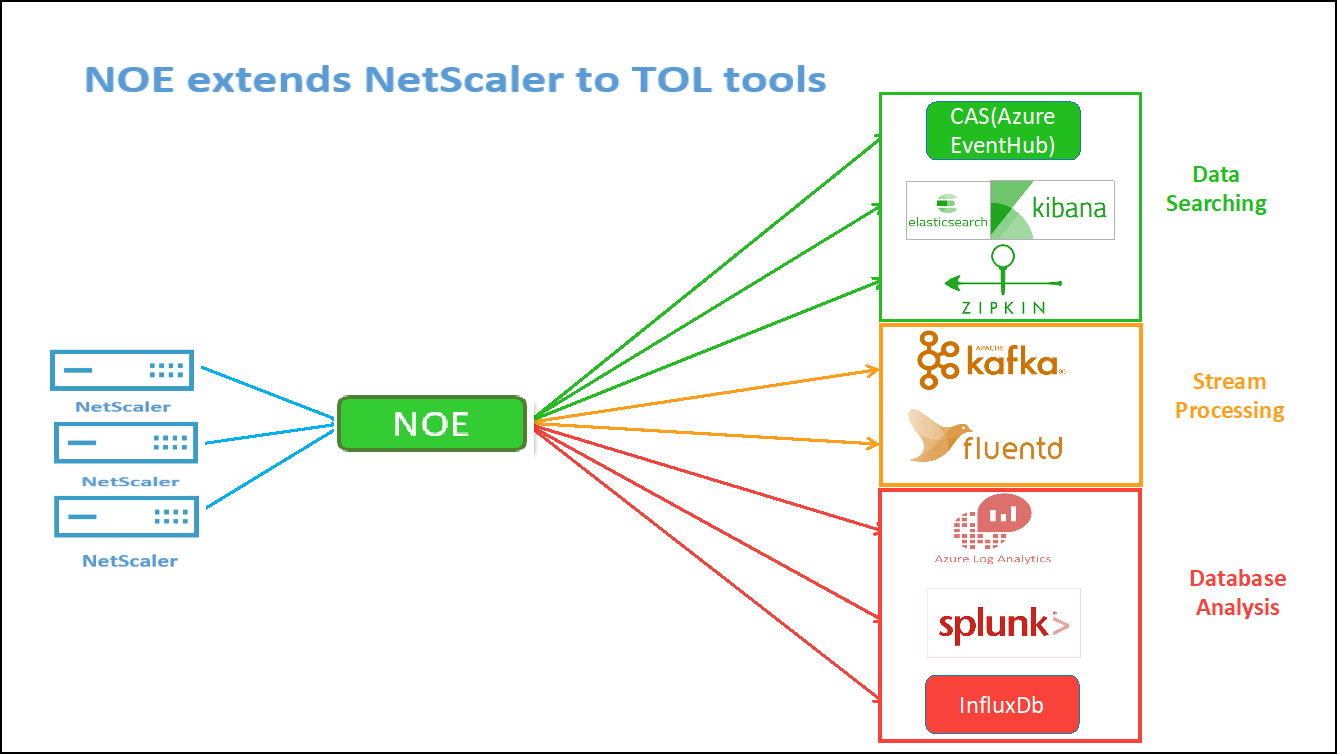
Estos contadores y registros de transacciones específicos se pueden extraer a través del NetScaler Observability Exporter (COE) mediante una variedad de puntos de conexión compatibles. Para obtener más información sobre el COE, consulte las siguientes secciones.
Exportador de estadísticas de NetScaler
Se trata de un servidor sencillo que extrae las estadísticas de NetScaler y las exporta a través de HTTP a Prometheus. Luego, Prometheus se puede agregar como origen de datos a Grafana para ver las estadísticas de NetScaler de forma gráfica.
Para supervisar las estadísticas y los contadores de las instancias de NetScaler, citrix-adc-metric-exporter se puede ejecutar como contenedor o script. El exportador recopila estadísticas de NetScaler, como el total de visitas a un servidor virtual, la tasa de solicitudes HTTP, la tasa de cifrado y descifrado SSL, etc., de las instancias de NetScaler y las retiene hasta que el servidor Prometheus extrae las estadísticas y las almacena con una marca de tiempo. A continuación, se puede apuntar a Grafana al servidor Prometheus para obtener las estadísticas, trazarlas, establecer alarmas, crear mapas de calor, generar tablas, etc., según sea necesario para analizar las estadísticas de NetScaler.
En estas secciones se proporcionan detalles sobre la configuración del exportador para que trabaje en un entorno como se indica en la ilustración. También se explica una nota sobre qué entidades/métricas de NetScaler extrae el exportador de forma predeterminada y cómo modificarlas.
Para obtener más información sobre Exporter for NetScaler, consulte el GitHub de Metrics Exporter.
Rastreo distribuido del servicio ADM
En el gráfico de servicio, puede utilizar la vista de rastreo distribuido para:
- Analice el rendimiento general del servicio.
- Visualice el flujo de comunicación entre el servicio seleccionado y sus servicios interdependientes.
- Identificar qué servicio indica errores y solucionar el servicio erróneo
- Permite ver los detalles de las transacciones entre el servicio seleccionado y cada servicio interdependiente.
Requisitos previos para el seguimiento distribuido de ADM
Para ver la información de seguimiento del servicio, debe:
- Asegúrese de que una aplicación mantenga los siguientes encabezados de seguimiento, mientras envía cualquier tráfico este-oeste:

- Actualice el archivo YAML CPX con NS_DISTRIBUTED_TRACING y el valor YES. Para empezar, consulte Rastreo distribuido.
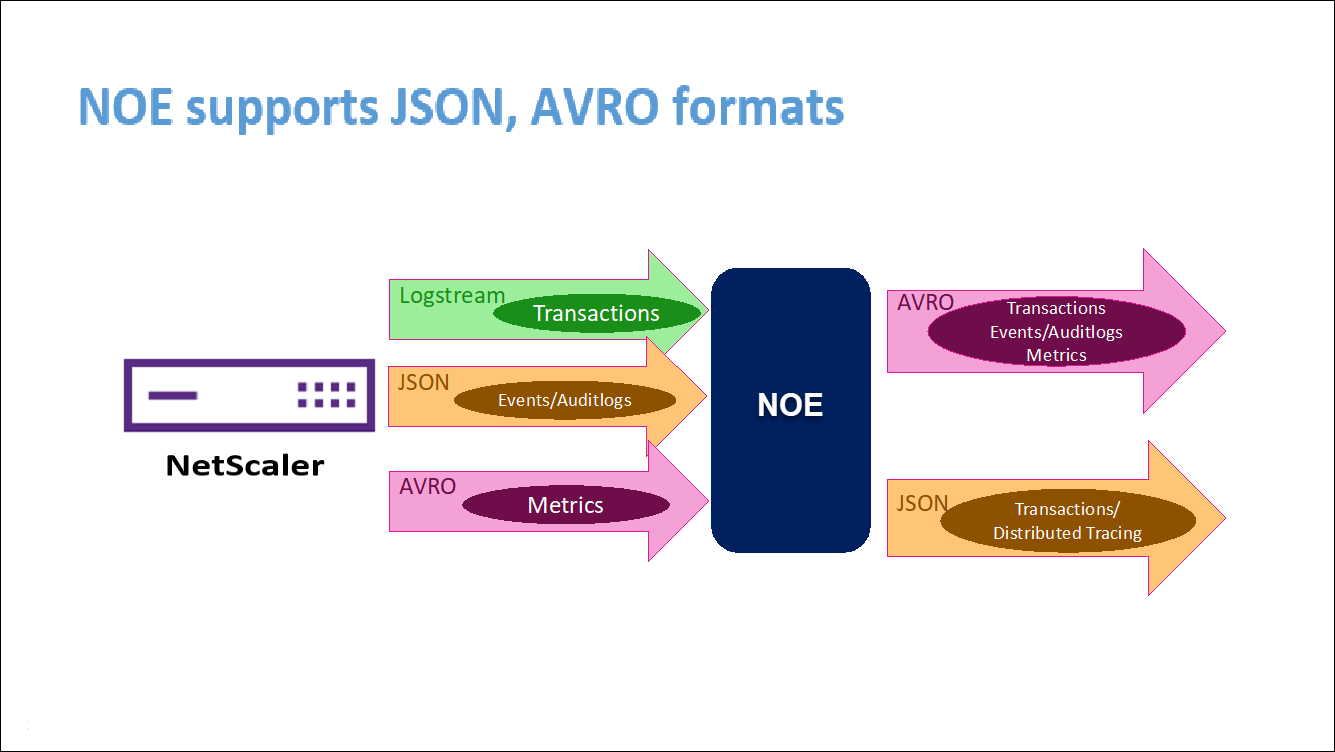
Análisis de NetScaler Observability Exporter (COE)
NetScaler Observability Exporter es un contenedor que recopila métricas y transacciones de NetScaler y las transforma a formatos adecuados (como JSON o AVRO) para los puntos de conexión compatibles. Puede exportar los datos recopilados por el exportador de observabilidad de NetScaler al punto final deseado. Al analizar los datos exportados al endpoint, puede obtener información valiosa a nivel de microservicios para las aplicaciones proxies de NetScalers.
Para obtener más información sobre el COE, consulta el COE GitHub.
COE con Elasticsearch como punto final de la transacción

Cuando se especifica Elasticsearch como el punto de enlace de la transacción, NetScaler Observability Exporter convierte los datos a formato JSON. En el servidor de Elasticsearch, NetScaler Observability Exporter crea índices de Elasticsearch para cada ADC cada hora. Estos índices se basan en los datos, la hora, el UUID del ADC y el tipo de datos HTTP (http_event o http_error). A continuación, el exportador de observabilidad de NetScaler carga los datos en formato JSON en los índices de búsqueda de Elastic para cada ADC. Todas las transacciones regulares se colocan en el índice http_event y cualquier anomalía se coloca en el índice http_error.
Función de rastreo distribuido con Zipkin
En una arquitectura de microservicios, una solicitud de un solo usuario final puede abarcar varios microservicios, lo que dificulta el seguimiento de una transacción y la corrección de los orígenes de los errores. En tales casos, las formas tradicionales de supervisión del rendimiento no pueden identificar con precisión dónde ocurren las fallas y cuál es la razón detrás de un rendimiento deficiente. Necesita una forma de capturar puntos de datos específicos para cada microservicio que gestiona una solicitud y analizarlos para obtener información valiosa.
El rastreo distribuido aborda este desafío al proporcionar una forma de rastrear una transacción de extremo a extremo y comprender cómo se maneja en varios microservicios.
OpenTracing es una especificación y un conjunto estándar de API para diseñar e implementar el rastreo distribuido. Los trazadores distribuidos le permiten visualizar el flujo de datos entre sus microservicios y le ayudan a identificar los cuellos de botella en su arquitectura de microservicios.
NetScaler Observability Exporter implementa el seguimiento distribuido para NetScaler y actualmente admite Zipkin como rastreador distribuido.
Actualmente, puede supervisar el rendimiento a nivel de aplicación mediante NetScaler. Con NetScaler Observability Exporter con NetScaler, puede obtener datos de seguimiento para microservicios de cada aplicación proxy por su NetScaler CPX, MPX o VPX.
Para empezar, consulta el Exportador de observabilidad de GitHub.
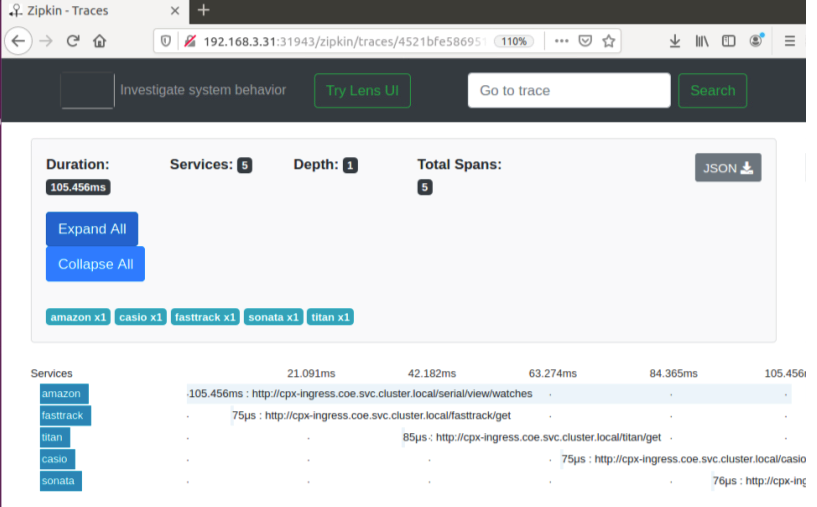
Zipkin para depuración de aplicaciones
Zipkin es un sistema de rastreo distribuido de código abierto basado en el documento de Dapper de Google. Dapper es el sistema de Google para su sistema de rastreo distribuido en producción. Google explica esto en su artículo: “Creamos Dapper para proporcionar a los desarrolladores de Google más información sobre el comportamiento de los sistemas distribuidos complejos”. Observar el sistema desde diferentes ángulos es fundamental a la hora de solucionar problemas, especialmente cuando un sistema es complejo y está distribuido.
Los siguientes datos de rastreo de Zipkin identifican un total de 5 intervalos y 5 servicios relacionados con la aplicación de muestra Watches. Los datos de seguimiento muestran los datos de extensión específicos en los 5 microservicios.
Para empezar, consulte Zipkin.
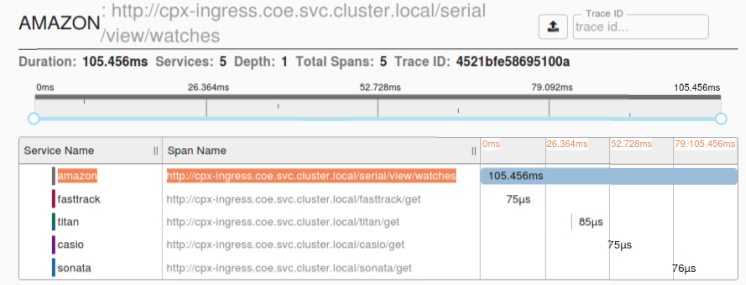
Ejemplo de intervalo de Zipkin que muestra la latencia de la aplicación para la solicitud de carga
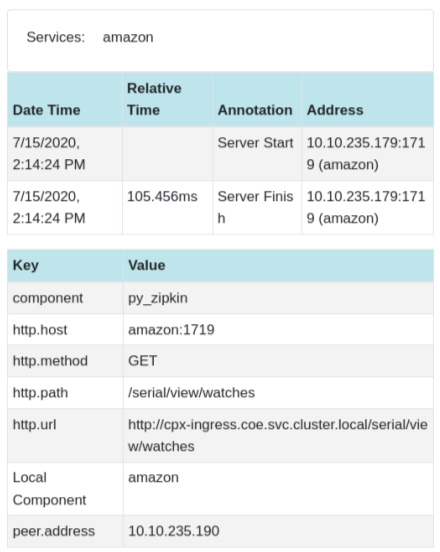
Kibana para ver datos
Kibana es una interfaz de usuario abierta que le permite visualizar sus datos de Elasticsearch y navegar por Elastic Stack. Puede hacer lo que quiera, desde hacer un seguimiento de la carga de las consultas hasta comprender la forma en que las solicitudes fluyen
Tanto si es analista como administrador, Kibana hace que sus datos sean procesables al proporcionar las siguientes tres funciones clave:
- Una plataforma de análisis y visualización de código abierto. Use Kibana para explorar sus datos de Elasticsearch y, a continuación, crear visualizaciones y paneles atractivos.
- Una interfaz de usuario para administrar Elastic Stack. Administre su configuración de seguridad, asigne funciones de usuario, tome instantáneas, acumule sus datos y mucho más, todo desde la comodidad de una interfaz de usuario de Kibana.
- Un centro centralizado para las soluciones de Elastic. Desde análisis de registros hasta descubrimiento de documentos y SIEM, Kibana es el portal para acceder a estas y otras capacidades.
Kibana está diseñado para usar Elasticsearch como origen de datos. Piense en Elasticsearch como el motor que almacena y procesa los datos, con Kibana en la cima.
En la página principal, Kibana proporciona estas opciones para agregar datos:
- Importe datos mediante el visualizador de datos de archivo.
- Configura un flujo de datos a Elasticsearch con nuestros tutoriales integrados. Si no existe un tutorial para sus datos, vaya a Descripción general de Beats para obtener información sobre otros remitentes de datos de la familia Beats.
- Agregue un conjunto de datos de muestra y lleve a Kibana a probarlo sin cargar los datos usted mismo.
- Indexe sus datos en Elasticsearch con las API REST o lasbibliotecas cliente.
Kibana usa un patrón de índice para indicarle qué índices de Elasticsearch explorar. Si carga un archivo, ejecuta un tutorial incorporado o agrega datos de muestra, obtiene un patrón de índice de forma gratuita y es bueno comenzar a explorar. Si carga sus propios datos, puede crear un patrón de índice en Stack Management.
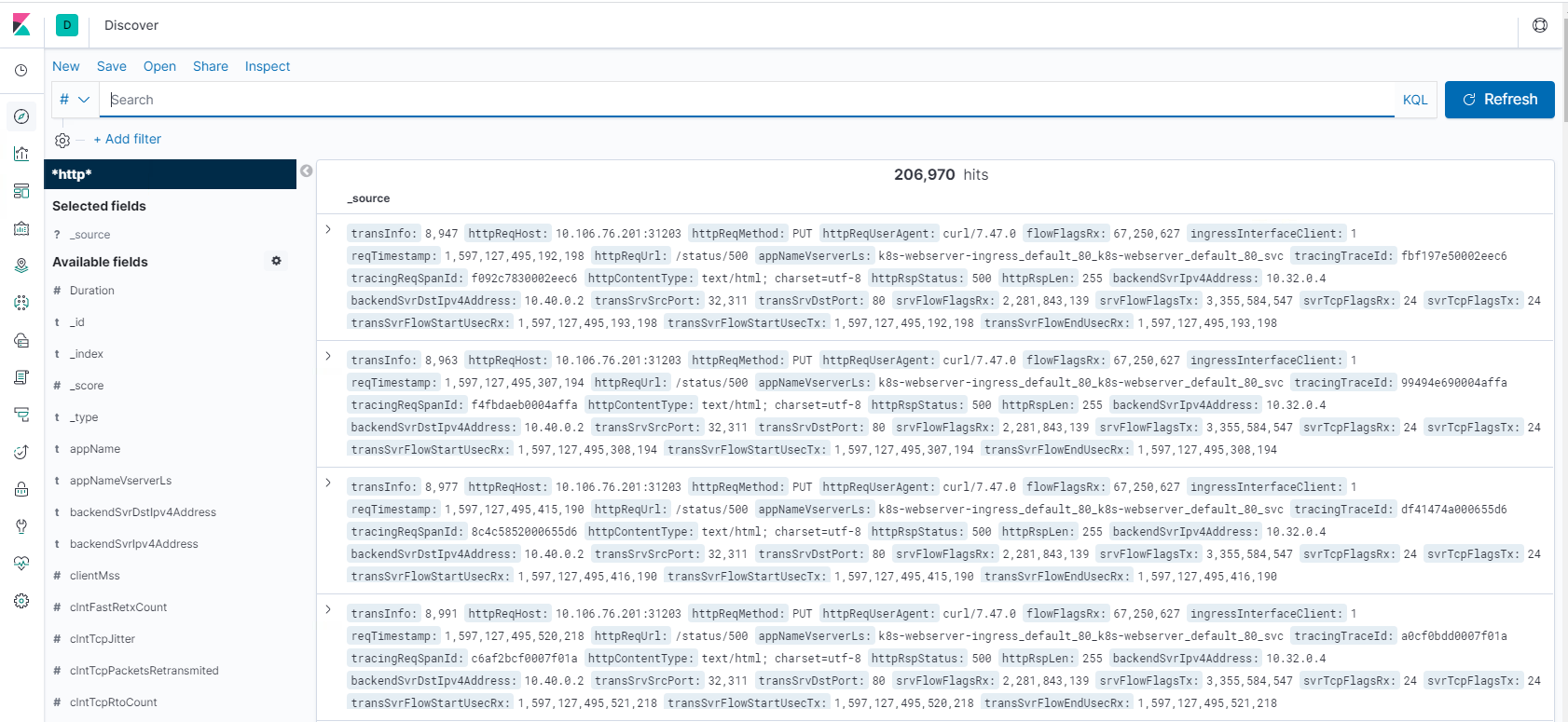
Paso 1: Configurar el patrón de índice para Logstash
Paso 2: Seleccione el índice y genere tráfico para rellenar.
Paso 3: generar la aplicación a partir de los datos no estructurados de los orígenes de los registros.
Paso 4: Kibana formatea la entrada de Logstash para crear informes y paneles.
- Intervalo de tiempo
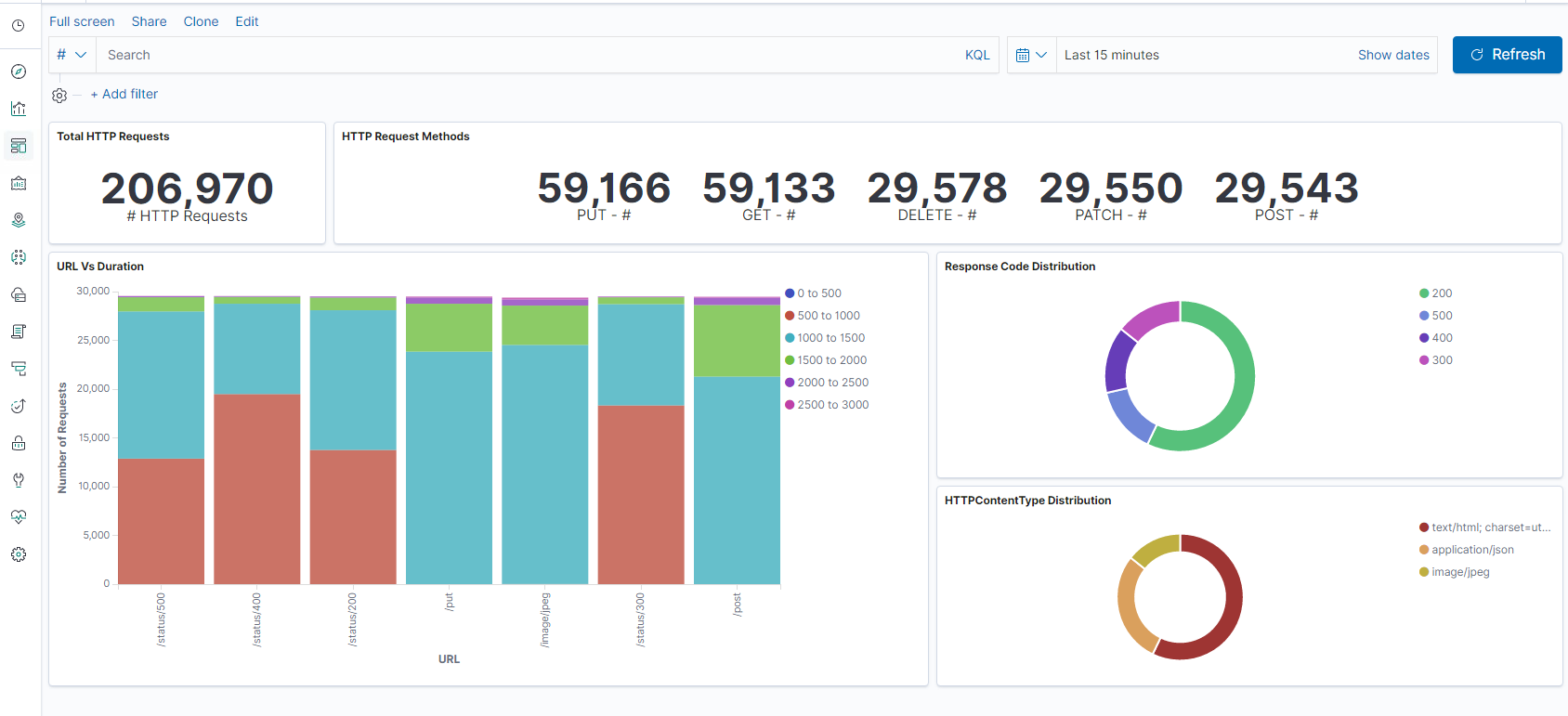
- Vista tabular
- Los recuentos de resultados se basan en la aplicación.
- Hora IP, agente, Machine.OS, código de respuesta (200), URL
- Filtrar por valores
Paso 5: Visualice los datos en un informe de agregaciones.
- Agregación de resultados en un informe de gráficos (circular, gráfico, etc.)
Compartir
Compartir
En este artículo
- Información general
- Descripción general de rendimiento y latencia de aplicaciones
- Panel SSL de NetScaler Application Delivery Management
- Integraciones de terceros
- Cómo equilibrar la carga del tráfico de entrada a una aplicación basada en TCP o UDP
- Supervise y mejore el rendimiento de sus aplicaciones basadas en TCP o UDP
- Servicio de administración de entrega de aplicaciones (ADM) de NetScaler
- Solución de problemas para los equipos NetScaler
- Solución de problemas para los equipos de SRE
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.