-
-
Quelle est la place d'une appliance NetScaler dans le réseau ?
-
Comment un NetScaler communique avec les clients et les serveurs
-
Accélérez le trafic équilibré de charge en utilisant la compression
-
-
-
Configuration de NetScaler pour Citrix Virtual Apps and Desktops
-
Préférence de zone optimisée Global Server Load Balancing (GSLB)
-
Déployez une plateforme de publicité numérique sur AWS avec NetScaler
-
Améliorer l'analyse du flux de clics dans AWS à l'aide de NetScaler
-
NetScaler dans un cloud privé géré par Microsoft Windows Azure Pack et Cisco ACI
-
-
Solution native pour le cloud NetScaler
-
Utiliser NetScaler ADM pour résoudre les problèmes liés au réseau natif du cloud NetScaler
-
Déployer une instance NetScaler VPX
-
Optimisez les performances de NetScaler VPX sur VMware ESX, Linux KVM et Citrix Hypervisors
-
Améliorez les performances SSL-TPS sur les plateformes de cloud public
-
Configurer le multithreading simultané pour NetScaler VPX sur les clouds publics
-
Installation d'une instance NetScaler VPX sur un serveur bare metal
-
Installation d'une instance NetScaler VPX sur Citrix Hypervisor
-
Installation d'une instance NetScaler VPX sur VMware ESX
-
Configurer NetScaler VPX pour utiliser l'interface réseau VMXNET3
-
Configurer NetScaler VPX pour utiliser l'interface réseau SR-IOV
-
Configurer NetScaler VPX pour utiliser Intel QAT pour l'accélération SSL en mode SR-IOV
-
Migration du NetScaler VPX de E1000 vers les interfaces réseau SR-IOV ou VMXNET3
-
Configurer NetScaler VPX pour utiliser l'interface réseau PCI passthrough
-
-
Installation d'une instance NetScaler VPX sur le cloud VMware sur AWS
-
Installation d'une instance NetScaler VPX sur des serveurs Microsoft Hyper-V
-
Installation d'une instance NetScaler VPX sur la plateforme Linux-KVM
-
Provisioning de l'appliance virtuelle NetScaler à l'aide d'OpenStack
-
Provisioning de l'appliance virtuelle NetScaler à l'aide du Virtual Machine Manager
-
Configuration des appliances virtuelles NetScaler pour utiliser l'interface réseau SR-IOV
-
Configuration des appliances virtuelles NetScaler pour utiliser l'interface réseau PCI Passthrough
-
Provisioning de l'appliance virtuelle NetScaler à l'aide du programme virsh
-
Provisioning de l'appliance virtuelle NetScaler avec SR-IOV sur OpenStack
-
Déployer une instance NetScaler VPX sur AWS
-
Serveurs d'équilibrage de charge dans différentes zones de disponibilité
-
Déployer une paire HA VPX dans la même zone de disponibilité AWS
-
Haute disponibilité dans différentes zones de disponibilité AWS
-
Déployez une paire VPX haute disponibilité avec des adresses IP privées dans différentes zones AWS
-
Protégez AWS API Gateway à l'aide du pare-feu d'applications Web NetScaler
-
Configurer une instance NetScaler VPX pour utiliser l'interface réseau SR-IOV
-
Configurer une instance NetScaler VPX pour utiliser la mise en réseau améliorée avec AWS ENA
-
Déployer une instance NetScaler VPX sur Microsoft Azure
-
Architecture réseau pour les instances NetScaler VPX sur Microsoft Azure
-
Configurer plusieurs adresses IP pour une instance autonome NetScaler VPX
-
Configurer une configuration haute disponibilité avec plusieurs adresses IP et cartes réseau
-
Déployez une paire de haute disponibilité NetScaler sur Azure avec ALB en mode IP flottant désactivé
-
Configurer une instance NetScaler VPX pour utiliser le réseau accéléré Azure
-
Configurez les nœuds HA-INC à l'aide du modèle de haute disponibilité NetScaler avec Azure ILB
-
Installation d'une instance NetScaler VPX sur la solution Azure VMware
-
Configurer une instance autonome NetScaler VPX sur la solution Azure VMware
-
Configurer une configuration de haute disponibilité NetScaler VPX sur la solution Azure VMware
-
Configurer le serveur de routage Azure avec la paire NetScaler VPX HA
-
Ajouter des paramètres de mise à l'échelle automatique Azure
-
Configurer GSLB sur une configuration haute disponibilité active en veille
-
Configurer des pools d'adresses (IIP) pour un dispositif NetScaler Gateway
-
Scripts PowerShell supplémentaires pour le déploiement Azure
-
Déployer une instance NetScaler VPX sur Google Cloud Platform
-
Déployer une paire haute disponibilité VPX sur Google Cloud Platform
-
Déployer une paire VPX haute disponibilité avec des adresses IP privées sur Google Cloud Platform
-
Installation d'une instance NetScaler VPX sur Google Cloud VMware Engine
-
Support de dimensionnement VIP pour l'instance NetScaler VPX sur GCP
-
-
Automatisez le déploiement et les configurations de NetScaler
-
Solutions pour les fournisseurs de services de télécommunication
-
Trafic du plan de contrôle de l'équilibrage de charge basé sur les protocoles Diameter, SIP et SMPP
-
Utilisation de la bande passante avec la fonctionnalité de redirection du cache
-
Optimisation du protocole TCP avec NetScaler
-
Authentification, autorisation et audit du trafic des applications
-
Fonctionnement de l'authentification, de l'autorisation et de l'audit
-
Composants de base de la configuration de l'authentification, de l'autorisation et de l'audit
-
-
Autorisation de l'accès des utilisateurs aux ressources de l'application
-
NetScaler en tant que proxy du service de fédération Active Directory
-
NetScaler Gateway sur site en tant que fournisseur d'identité pour Citrix Cloud
-
Prise en charge de la configuration de l'attribut de cookie SameSite
-
Résoudre les problèmes liés à l'authentification et à l'autorisation
-
-
-
-
Configurer une expression de stratégie avancée : pour démarrer
-
Expressions de stratégie avancées : utilisation de dates, d'heures et de chiffres
-
Expressions de stratégie avancées : analyse des données HTTP, TCP et UDP
-
Expressions de politique avancées : analyse des certificats SSL
-
Expressions de stratégie avancées : adresses IP et MAC, débit, identifiants VLAN
-
Expressions politiques avancées : fonctions d'analyse des flux
-
Expressions de politique avancées utilisant la spécification de l'API
-
Exemples didacticiels de politiques avancées pour la réécriture
-
-
-
-
-
Protection basée sur la grammaire SQL pour les charges utiles HTML et JSON
-
Protection basée sur la grammaire par injection de commandes pour la charge utile HTML
-
Règles de relaxation et de refus pour la gestion des attaques par injection HTML SQL
-
Prise en charge du pare-feu d'application pour Google Web Toolkit
-
Vérifications de protection XML
-
Cas d'utilisation - Liaison de la stratégie Web App Firewall à un serveur virtuel VPN
-
Articles sur les alertes de signatures
-
-
Traduire l'adresse IP de destination d'une requête vers l'adresse IP d'origine
-
-
Prise en charge de la configuration de NetScaler dans un cluster
-
-
-
Groupes de nœuds pour les configurations repérées et partiellement entrelacées
-
Désactivation de la direction sur le fond de panier du cluster
-
Suppression d'un nœud d'un cluster déployé à l'aide de l'agrégation de liens de cluster
-
Surveillance de la configuration du cluster à l'aide de la MIB SNMP avec lien SNMP
-
Surveillance des échecs de propagation des commandes dans un déploiement de cluster
-
Liaison d'interface VRRP dans un cluster actif à nœud unique
-
Scénarios de configuration et d'utilisation du cluster
-
Migration d'une configuration HA vers une configuration de cluster
-
Interfaces communes pour le client et le serveur et interfaces dédiées pour le fond de panier
-
Commutateur commun pour le client, le serveur et le fond de panier
-
Commutateur commun pour client et serveur et commutateur dédié pour fond de panier
-
Services de surveillance dans un cluster à l'aide de la surveillance des chemins
-
Opérations prises en charge sur des nœuds de cluster individuels
-
-
-
Configurer les enregistrements de ressources DNS
-
Créer des enregistrements MX pour un serveur d'échange de messagerie
-
Créer des enregistrements NS pour un serveur faisant autorité
-
Créer des enregistrements NAPTR pour le domaine des télécommunications
-
Créer des enregistrements PTR pour les adresses IPv4 et IPv6
-
Créer des enregistrements SOA pour les informations faisant autorité
-
Créer des enregistrements TXT pour contenir du texte descriptif
-
Configurer NetScaler en tant que résolveur de stubs non validant et sensible à la sécurité
-
Prise en charge des trames Jumbo pour le DNS pour gérer les réponses de grande taille
-
Configurer la mise en cache négative des enregistrements DNS
-
Cas d'utilisation : configuration de la fonction de gestion automatique des clés DNSSEC
-
Cas d'utilisation : comment révoquer une clé active compromise
-
-
Équilibrage de charge de serveur global
-
Configurez les entités GSLB individuellement
-
Synchronisation de la configuration dans une configuration GSLB
-
Cas d'utilisation : déploiement d'un groupe de services Autoscale basé sur l'adresse IP
-
-
Remplacer le comportement de proximité statique en configurant les emplacements préférés
-
Configuration de la sélection des services GSLB à l'aide du changement de contenu
-
Configurer GSLB pour les requêtes DNS avec des enregistrements NAPTR
-
Exemple de configuration parent-enfant complète à l'aide du protocole d'échange de métriques
-
-
Équilibrer la charge du serveur virtuel et des états de service
-
Protection d'une configuration d'équilibrage de charge contre les défaillances
-
-
Configuration des serveurs virtuels d'équilibrage de charge sans session
-
Réécriture des ports et des protocoles pour la redirection HTTP
-
Insérer l'adresse IP et le port d'un serveur virtuel dans l'en-tête de requête
-
Utiliser une adresse IP source spécifiée pour la communication principale
-
Définir une valeur de délai d'expiration pour les connexions client inactives
-
Utiliser un port source d'une plage de ports spécifiée pour les communications en arrière-plan
-
Configurer la persistance de l'adresse IP source pour la communication principale
-
-
Paramètres d'équilibrage de charge avancés
-
Protégez les applications sur les serveurs protégés contre les pics de trafic
-
Activer le nettoyage des connexions de serveur virtuel et de service
-
Activer ou désactiver la session de persistance sur les services TROFS
-
Activer la vérification de l'état TCP externe pour les serveurs virtuels UDP
-
Maintenir la connexion client pour plusieurs demandes client
-
Utiliser l'adresse IP source du client lors de la connexion au serveur
-
Définissez une limite sur le nombre de demandes par connexion au serveur
-
Définir une valeur de seuil pour les moniteurs liés à un service
-
Définir une valeur de délai d'attente pour les connexions client inactives
-
Définir une valeur de délai d'attente pour les connexions de serveur inactives
-
Définir une limite sur l'utilisation de la bande passante par les clients
-
Conserver l'identificateur VLAN pour la transparence du VLAN
-
Configurer les moniteurs dans une configuration d'équilibrage de charge
-
Configurer l'équilibrage de charge pour les protocoles couramment utilisés
-
Cas d'utilisation 3 : configurer l'équilibrage de charge en mode de retour direct du serveur
-
Cas d'utilisation 4 : Configuration des serveurs LINUX en mode DSR
-
Cas d'utilisation 5 : configurer le mode DSR lors de l'utilisation de TOS
-
Cas d'utilisation 7 : Configurer l'équilibrage de charge en mode DSR à l'aide d'IP sur IP
-
Cas d'utilisation 8 : Configurer l'équilibrage de charge en mode à un bras
-
Cas d'utilisation 9 : Configurer l'équilibrage de charge en mode en ligne
-
Cas d'utilisation 10 : Équilibrage de charge des serveurs de systèmes de détection d'intrusion
-
Cas d'utilisation 11 : Isolation du trafic réseau à l'aide de stratégies d'écoute
-
Cas d'utilisation 12 : configurer Citrix Virtual Desktops pour l'équilibrage de charge
-
Cas d'utilisation 14 : Assistant ShareFile pour l'équilibrage de charge Citrix ShareFile
-
Cas d'utilisation 15 : configurer l'équilibrage de charge de couche 4 sur l'appliance NetScaler
-
-
-
Configuration pour générer le trafic de données NetScaler FreeBSD à partir d'une adresse SNIP
-
-
-
Déchargement et accélération SSL
-
Matrice de prise en charge des certificats de serveur sur l'appliance ADC
-
Prise en charge du module de sécurité matérielle Thales Luna Network
-
-
-
Authentification et autorisation pour les utilisateurs système
-
Configuration des utilisateurs, des groupes d'utilisateurs et des stratégies de commande
-
Réinitialisation du mot de passe administrateur par défaut (nsroot)
-
Configuration de l'authentification des utilisateurs externes
-
Authentification basée sur une clé SSH pour les administrateurs NetScaler
-
Authentification à deux facteurs pour les utilisateurs système
-
-
-
Points à prendre en compte pour une configuration haute disponibilité
-
Synchronisation des fichiers de configuration dans une configuration haute disponibilité
-
Restriction du trafic de synchronisation haute disponibilité vers un VLAN
-
Configuration de nœuds haute disponibilité dans différents sous-réseaux
-
Limitation des basculements causés par les moniteurs de routage en mode non INC
-
Gestion des messages Heartbeat à haute disponibilité sur une appliance NetScaler
-
Supprimer et remplacer un NetScaler dans une configuration de haute disponibilité
-
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Utilisez la console NetScaler pour résoudre les problèmes liés à la mise en réseau native du cloud NetScaler
Vue d’ensemble
Ce document fournit des informations sur la manière dont vous pouvez utiliser la console NetScaler pour fournir et surveiller des applications de microservices Kubernetes. Vous découvrirez également l’utilisation de l’interface de ligne de commande, des graphiques de service et du suivi pour permettre à la plateforme et aux équipes SRE de résoudre les problèmes.
Présentation des performances et de la latence
Cryptage TLS
Le protocole TLS est un protocole de cryptage conçu pour sécuriser les communications Internet. Une prise de contact TLS est le processus qui démarre une session de communication utilisant le cryptage TLS. Lors d’une poignée de main TLS, les deux parties communicantes échangent des messages pour s’accuser réception, se vérifier mutuellement, établir les algorithmes de chiffrement qu’ils utilisent et se mettre d’accord sur les clés de session. Les poignées de main TLS sont un élément fondamental du fonctionnement du protocole HTTPS.
Poignée de main TLS vs SSL
SSL (Secure Sockets Layer) était le protocole de cryptage original développé pour HTTP. TLS (Transport Layer Security) a remplacé SSL il y a quelque temps. Les poignées de main SSL sont maintenant appelées poignées de main TLS, bien que le nom « SSL » soit encore largement utilisé.
Quand se produit une prise de contact TLS ?
Une poignée de main TLS a lieu chaque fois qu’un utilisateur accède à un site Web via HTTPS et que le navigateur commence d’abord à interroger le serveur d’origine du site Web. Une prise de contact TLS se produit également chaque fois que d’autres communications utilisent HTTPS, y compris les appels d’API et les requêtes DNS sur HTTPS.
Les prises de contact TLS se produisent après l’ouverture d’une connexion TCP via une poignée de main TCP.
Que se passe-t-il lors d’une prise de contact TLS ?
- Lors d’une prise de contact TLS, le client et le serveur effectuent ensemble les opérations suivantes :
- Spécifiez la version de TLS (TLS 1.0, 1.2, 1.3, etc.) qu’ils utilisent.
- Déterminez les suites de chiffrement (voir la section suivante) qu’ils utilisent.
- Authentifiez l’identité du serveur via la clé publique du serveur et la signature numérique de l’autorité de certification SSL.
- Générez des clés de session pour utiliser le chiffrement symétrique une fois la prise de contact terminée.
Quelles sont les étapes d’une prise de contact TLS ?
- Les poignées de main TLS sont une série de datagrammes, ou messages, échangés par un client et un serveur. Une prise de contact TLS comporte plusieurs étapes, car le client et le serveur échangent les informations nécessaires pour terminer la prise de contact et permettre la poursuite de la conversation.
Les étapes exactes d’une négociation TLS varient en fonction du type d’algorithme d’échange de clés utilisé et des suites de chiffrement prises en charge par les deux parties. L’algorithme d’échange de clés RSA est le plus souvent utilisé. Il se déroule comme suit :
- Le message « bonjour client » : Le client initie la prise de contact en envoyant un message « bonjour » au serveur. Le message indique la version TLS prise en charge par le client, les suites de chiffrement prises en charge et une chaîne d’octets aléatoires appelée « client aléatoire ».
- Le message « bonjour du serveur » : En réponse au message Hello du client, le serveur envoie un message contenant le certificat SSL du serveur, la suite de chiffrement choisie par le serveur et le « serveur aléatoire », une autre chaîne aléatoire d’octets générée par le serveur.
- Authentification : Le client vérifie le certificat SSL du serveur auprès de l’autorité de certification qui l’a émis. Cela confirme que le serveur est bien celui qu’il prétend être et que le client interagit avec le véritable propriétaire du domaine.
- Le secret prémaître: Le client envoie une autre chaîne aléatoire d’octets, le « secret prémaître ». Le secret prémaître est chiffré avec la clé publique et ne peut être déchiffré qu’avec la clé privée par le serveur. (Le client obtient la clé publique du certificat SSL du serveur.)
- Clé privée utilisée : Le serveur déchiffre le secret du prémaster.
- Clés de session créées : le client et le serveur génèrent des clés de session à partir du client aléatoire, du serveur aléatoire et du secret prémaître. Ils devraient parvenir aux mêmes résultats.
- Le client est prêt : le client envoie un message « terminé » chiffré avec une clé de session.
- Le serveur est prêt : le serveur envoie un message « terminé » chiffré avec une clé de session.
- Chiffrement symétrique sécurisé obtenu : la prise de contact est terminée et la communication se poursuit à l’aide des clés de session.
Toutes les prises de contact TLS utilisent un cryptage asymétrique (clé publique et privée), mais toutes n’utilisent pas la clé privée dans le processus de génération des clés de session. Par exemple, une poignée de main éphémère Diffie-Hellman se déroule comme suit :
- Client Hello : le client envoie un message Hello client avec la version du protocole, le caractère aléatoire du client et une liste de suites de chiffrement.
- Bonjour du serveur : Le serveur répond avec son certificat SSL, sa suite de chiffrement sélectionnée et le serveur aléatoire. Contrairement à l’établissement de liaison RSA décrit dans la section précédente, le serveur inclut également dans ce message les informations suivantes (étape 3).
- Signature numérique du serveur : Le serveur utilise sa clé privée pour chiffrer le client au hasard, le serveur aléatoire et son paramètre DH*. Ces données cryptées fonctionnent comme la signature numérique du serveur, établissant que le serveur possède la clé privée qui correspond à la clé publique du certificat SSL.
- Signature numérique confirmée : le client déchiffre la signature numérique du serveur avec la clé publique, en vérifiant que le serveur contrôle la clé privée et qu’il est bien celui qu’il prétend être. Paramètre DH du client : Le client envoie son paramètre DH au serveur.
- Le client et le serveur calculent le secret prémaître : au lieu que le client génère le secret prémaître et l’envoie au serveur, comme dans une poignée de main RSA, le client et le serveur utilisent les paramètres DH qu’ils ont échangés pour calculer séparément un secret prémaître correspondant.
- Clés de session créées : Maintenant, le client et le serveur calculent les clés de session à partir du secret prémaître, du hasard du client et du serveur, comme dans une poignée de main RSA.
- Le client est prêt : même chose qu’une poignée de main RSA
- Le serveur est prêt
- Cryptage symétrique sécurisé obtenu
*Paramètre DH : DH signifie Diffie-Hellman. L’algorithme Diffie-Hellman utilise des calculs exponentiels pour arriver au même secret prémaster. Le serveur et le client fournissent chacun un paramètre pour le calcul et, lorsqu’ils sont combinés, ils aboutissent à un calcul différent de chaque côté, avec des résultats égaux.
Pour en savoir plus sur le contraste entre les poignées de main éphémères Diffie-Hellman et d’autres types de poignées de main, et sur la manière dont elles permettent d’atteindre le secret de transmission, consultez cette documentation sur le protocole TLS.
Qu’est-ce qu’une suite de chiffrement ?
- Une suite de chiffrement est un ensemble d’algorithmes de chiffrement utilisés pour établir une connexion de communication sécurisée. (Un algorithme de chiffrement est un ensemble d’opérations mathématiques effectuées sur des données pour les rendre aléatoires.) Il existe différentes suites de chiffrement largement utilisées, et une partie essentielle de la prise de contact TLS consiste à déterminer quelle suite de chiffrement est utilisée pour cette poignée de main.
Pour commencer, reportez-vous à la section Référence : Documentation du protocole TLS.
Tableau de bord SSL de NetScaler Application Delivery Management
NetScaler Application Delivery Management (ADM) rationalise désormais tous les aspects de la gestion des certificats pour vous. Grâce à une console unique, vous pouvez établir des stratégies automatisées pour garantir l’émetteur, la force de clé et les algorithmes corrects, tout en gardant un œil étroit sur les certificats inutilisés ou bientôt expirés. Pour commencer à utiliser le tableau de bord SSL de NetScaler Console et ses fonctionnalités, vous devez comprendre ce qu’est un certificat SSL et comment utiliser NetScaler Console pour suivre vos certificats SSL.
Un certificat SSL (Secure Socket Layer), qui fait partie de toute transaction SSL, est un formulaire de données numérique (X509) qui identifie une société (domaine) ou un individu. Le certificat possède un composant de clé publique visible par tout client qui souhaite lancer une transaction sécurisée avec le serveur. La clé privée correspondante, qui réside en toute sécurité sur l’appliance Citrix Application Delivery Controller (ADC), est utilisée pour effectuer le chiffrement et le déchiffrement des clés asymétriques (ou des clés publiques).
Vous pouvez obtenir un certificat SSL et une clé de l’une des manières suivantes :
- De la part d’une autorité de certification (CA) autorisée
- En générant un nouveau certificat SSL et une nouvelle clé sur l’appliance NetScaler
La console NetScaler fournit une vue centralisée des certificats SSL installés sur toutes les instances NetScaler gérées. Sur le tableau de bord SSL, vous pouvez afficher des graphiques qui vous aident à suivre les émetteurs de certificats, les forces clés, les algorithmes de signature, les certificats expirés ou non utilisés, etc. Vous pouvez également voir la distribution des protocoles SSL qui s’exécutent sur vos serveurs virtuels et les clés qui y sont activées.
Vous pouvez également configurer des notifications pour vous informer lorsque les certificats sont sur le point d’expirer et inclure des informations sur les instances NetScaler qui utilisent ces certificats.
Vous pouvez lier les certificats d’une instance NetScaler à un certificat CA. Cependant, assurez-vous que les certificats que vous liez au même certificat d’autorité de certification ont la même source et le même émetteur. Après avoir lié les certificats à un certificat d’autorité de certification, vous pouvez les dissocier.
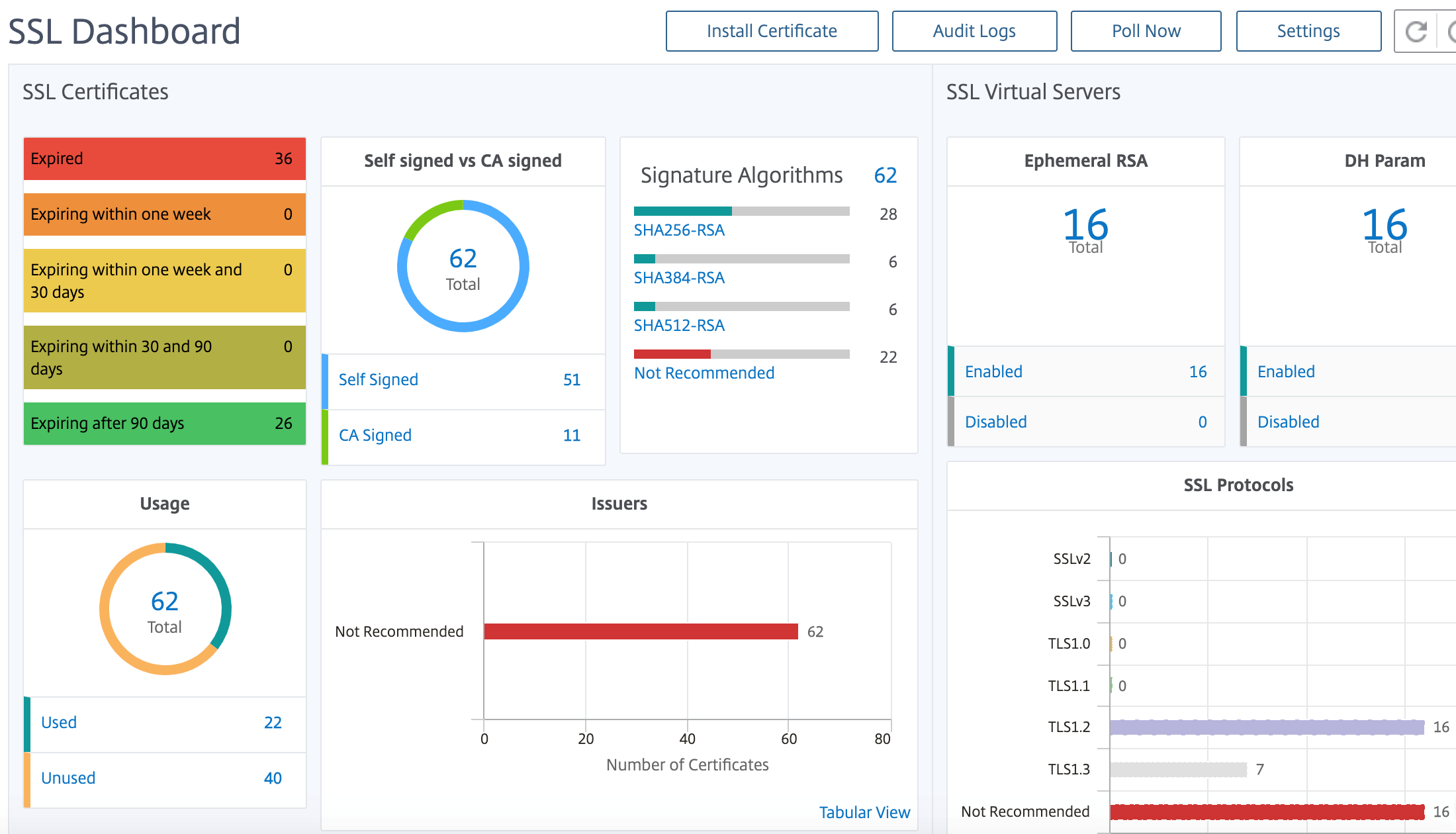
Pour commencer, consultez la documentation du tableau de bord SSL.
Intégrations tierces
La latence de l’application est mesurée en millisecondes et peut indiquer l’un des deux éléments suivants en fonction de la mesure utilisée. La méthode la plus courante de mesure de la latence est appelée « temps aller-retour » (ou RTT). RTT calcule le temps nécessaire à un paquet de données pour se déplacer d’un point à un autre sur le réseau et pour qu’une réponse soit renvoyée à la source. L’autre mesure est appelée « temps jusqu’au premier octet » (ou TTFB), qui enregistre le temps qu’il faut entre le moment où un paquet quitte un point du réseau et le moment où il arrive à destination. Le RTT est plus couramment utilisé pour mesurer la latence car il peut être exécuté à partir d’un point unique du réseau et ne nécessite pas l’installation d’un logiciel de collecte de données sur le point de destination (comme le fait TTFB).
En surveillant l’utilisation et les performances de la bande passante de votre application en temps réel, le service ADM facilite l’identification des problèmes et la résolution préventive des problèmes potentiels avant qu’ils ne se manifestent et n’affectent les utilisateurs de votre réseau. Cette solution basée sur les flux suit l’utilisation par interface, application et conversation, vous fournissant des informations détaillées sur l’activité de votre réseau.
Utiliser les outils Splunk
Les performances de l’infrastructure et des applications sont interdépendantes. Pour avoir une vue d’ensemble, SignalFX fournit une corrélation transparente entre l’infrastructure cloud et les microservices qui s’exécutent dessus. Si votre application échoue en raison d’une fuite de mémoire, d’un conteneur voisin bruyant ou de tout autre problème lié à l’infrastructure, SignalFX vous en informe. Pour compléter le tableau, l’accès en contexte aux journaux et aux événements Splunk permet un dépannage plus approfondi et une analyse des causes profondes.
Pour plus d’informations sur l’APM des microservices SignalFX et le dépannage avec Splunk, consultez les informations relatives à Splunk pour DevOps.
Prise en charge MongoDB
MongoDB stocke les données dans des documents flexibles de type JSON. Les champs de signification peuvent varier d’un document à l’autre et la structure des données peut être modifiée au fil du temps.
Le modèle de document correspond aux objets de votre code d’application, ce qui facilite l’utilisation des données.
Les requêtes à la demande, l’indexation et l’agrégation en temps réel fournissent de puissants moyens d’accéder à vos données et de les analyser.
MongoDB est une base de données distribuée, de sorte que la haute disponibilité, la mise à l’échelle horizontale et la distribution géographique sont intégrées et faciles à utiliser.
MongoDB est conçu pour répondre aux exigences des applications modernes grâce à une base technologique qui vous permet de :
- Le modèle de données du document, qui vous présente la meilleure façon de travailler avec les données.
- Une conception de systèmes distribués qui vous permet de placer intelligemment les données où vous le souhaitez.
- Une expérience unifiée qui vous donne la liberté d’exécuter n’importe où, ce qui vous permet de pérenniser votre travail et d’éliminer la dépendance vis-à-vis des fournisseurs.
Avec ces fonctionnalités, vous pouvez créer une plate-forme de données opérationnelles intelligente, soutenue par MongoDB. Pour plus d’informations, consultez la documentation MongoDB.
Comment équilibrer la charge du trafic entrant vers une application basée sur TCP ou UDP
Dans un environnement Kubernetes, une entrée est un objet qui permet d’accéder aux services Kubernetes depuis l’extérieur du cluster Kubernetes. Les ressources Kubernetes Ingress standard supposent que tout le trafic est basé sur HTTP et ne répond pas aux protocoles non HTTP tels que TCP, TCP-SSL et UDP. Par conséquent, les applications critiques basées sur les protocoles L7 tels que DNS, FTP, LDAP, ne peuvent pas être exposées à l’aide de Kubernetes Ingress standard.
La solution standard de Kubernetes consiste à créer un service de type LoadBalancer. Reportez-vous à la section Service Type LoadBalancer dans NetScaler pour plus d’informations.
La deuxième option consiste à annoter l’objet d’entrée. NetScaler Ingress Controller vous permet d’équilibrer la charge du trafic d’entrée basé sur TCP ou UDP. Il fournit les annotations suivantes que vous pouvez utiliser dans votre définition de ressource Kubernetes Ingress pour équilibrer la charge du trafic entrant basé sur TCP ou UDP :
- ingress.citrix.com/insecure-service-type : l’annotation permet l’équilibrage de charge L4 avec TCP, UDP ou ANY comme protocole pour NetScaler.
- ingress.citrix.com/insecure-port : l’annotation configure le port TCP. L’annotation est utile lorsque l’accès au microservice est requis sur un port non standard. Par défaut, le port 80 est configuré.
Pour plus d’informations, consultez Comment équilibrer la charge du trafic entrant vers une application basée sur TCP ou UDP.
Surveillez et améliorez les performances de vos applications basées sur TCP ou UDP
Les développeurs d’applications peuvent surveiller de près l’état de santé des applications basées sur TCP ou UDP à l’aide de puissants moniteurs (tels que TCP-ECV, UDP-ECV) intégrés à NetScaler. L’ECV (Extended Content Validation) surveille l’aide pour vérifier si l’application renvoie le contenu attendu ou non.
En outre, les performances de l’application peuvent être améliorées en utilisant des méthodes de persistance telles que l’adresse IP source. Vous pouvez utiliser ces fonctionnalités de NetScaler via des annotations intelligentes dans Kubernetes. Voici un exemple de ce type :
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: mongodb
annotations:
ingress.citrix.com/insecure-port: “80”
ingress.citrix.com/frontend-ip: “192.168.1.1”
ingress.citrix.com/csvserver: ‘{“l2conn”:”on”}’
ingress.citrix.com/lbvserver: ‘{“mongodb-svc”:{“lbmethod”:”SRCIPDESTIPHASH”}}’
ingress.citrix.com/monitor: ‘{“mongodbsvc”:{“type”:”tcp-ecv”}}’
Spec:
rules:
- host: mongodb.beverages.com
http:
paths:
- path: /
backend:
serviceName: mongodb-svc
servicePort: 80
<!--NeedCopy-->
Service de gestion de la diffusion des applications (ADM) NetScaler
Le service de console NetScaler offre les avantages suivants :
- Agile — Facile à utiliser, à mettre à jour et à consommer. Le modèle de service de NetScaler Console Service est disponible sur le cloud, ce qui facilite l’utilisation, la mise à jour et l’utilisation des fonctionnalités fournies. La fréquence des mises à jour, associée à la fonctionnalité de mise à jour automatique, améliore rapidement votre déploiement NetScaler.
- Délai de rentabilisation plus rapide — Réalisation plus rapide des objectifs commerciaux. Contrairement au déploiement local traditionnel, vous pouvez utiliser votre service de console NetScaler en quelques clics. Vous économisez non seulement du temps d’installation et de configuration, mais vous évitez également de perdre du temps et des ressources en cas d’erreurs potentielles.
- Gestion multisite : volet unique de verre pour les instances dans les datacenters multi-sites. Le service de console NetScaler vous permet de gérer et de surveiller les appareils NetScaler faisant l’objet de différents types de déploiements. Vous disposez d’une gestion centralisée pour les NetScalers déployés sur site et dans le cloud.
- Efficacité opérationnelle — Une façon optimisée et automatisée d’atteindre une productivité opérationnelle plus élevée. Le service NetScaler Console vous permet de réduire vos coûts opérationnels en économisant du temps, de l’argent et des ressources sur la maintenance et la mise à niveau des déploiements matériels traditionnels.
Graphique de service pour les applications Kubernetes
À l’aide du graphique de service de la fonctionnalité d’application native du cloud dans NetScaler Console, vous pouvez :
- Garantir les performances globales des applications de bout en bout
- Identifiez les goulots d’étranglement créés par l’interdépendance des différents composants de vos applications
- Recueillez des informations sur les dépendances des différents composants de vos applications
- Surveiller les services au sein du cluster Kubernetes
- Surveiller quel service rencontre des problèmes
- Vérifiez les facteurs qui contribuent aux problèmes de performance
- Afficher la visibilité détaillée des transactions HTTP de service
- Analyser les mesures HTTP, TCP et SSL
En visualisant ces mesures dans NetScaler Console, vous pouvez analyser la cause première des problèmes et prendre les mesures de dépannage nécessaires plus rapidement. Le graphique de service affiche vos applications dans divers services de composants. Ces services s’exécutant à l’intérieur du cluster Kubernetes peuvent communiquer avec divers composants à l’intérieur et à l’extérieur de l’application.
Pour commencer, reportez-vous à la section Configuration du graphique de service.
Graphique de service pour les applications Web à 3 niveaux
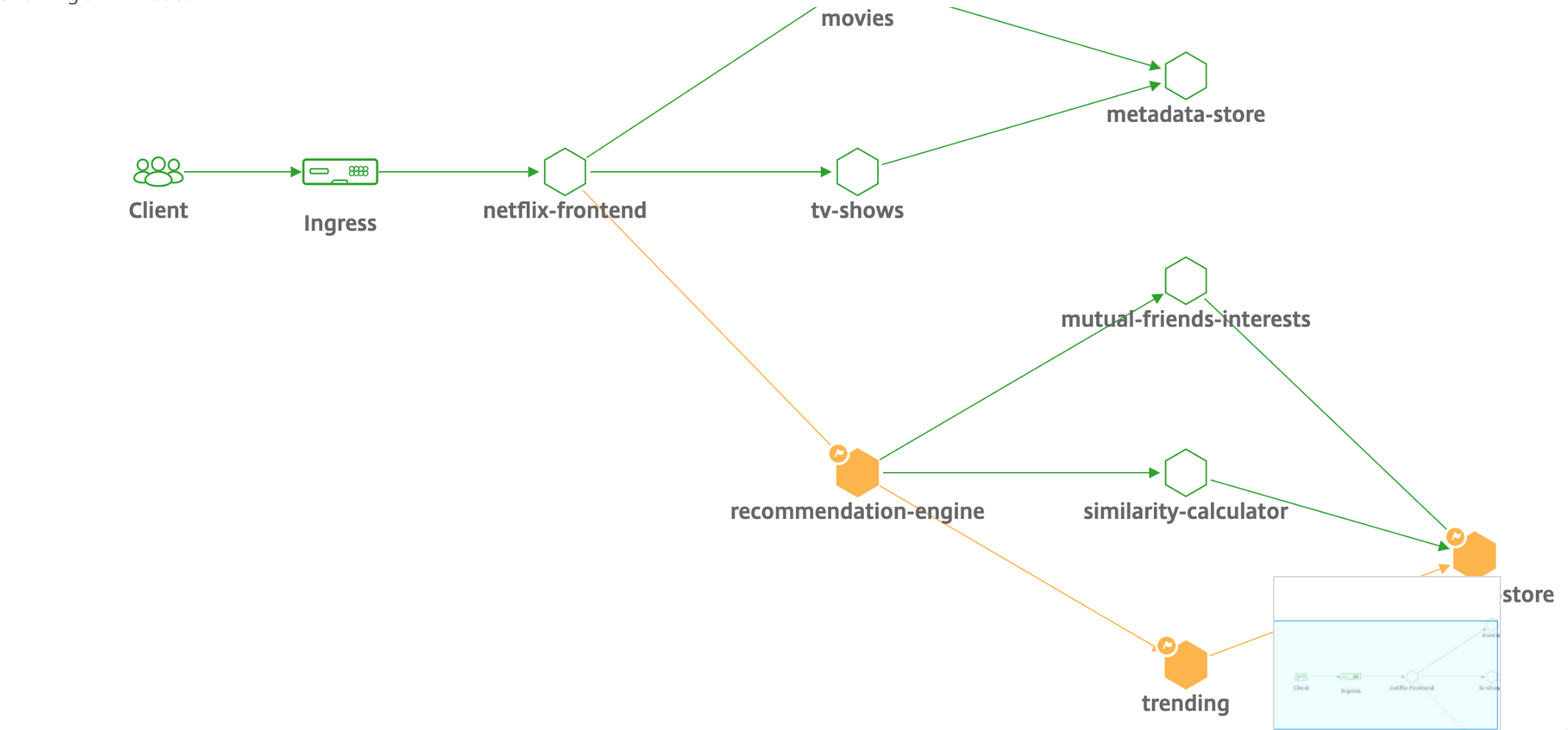
À l’aide de la fonction de graphe de service du tableau de bord de l’application, vous pouvez afficher :
- Détails sur la configuration de l’application (avec un serveur virtuel de commutation de contenu et un serveur virtuel d’équilibrage de charge)
- Pour les applications GSLB, vous pouvez afficher le centre de données, l’instance ADC, les serveurs virtuels CS et LB
- Transactions de bout en bout du client au service
- Emplacement à partir duquel le client accède à l’application
- Le nom du centre de données dans lequel les demandes des clients sont traitées et les métriques NetScaler du centre de données associées (uniquement pour les applications GSLB)
- Détails des mesures pour les serveurs clients, les services et les serveurs virtuels
- Si les erreurs proviennent du client ou du service
- L’état du service, tel que Critique, RévisionetBon. La console NetScaler affiche l’état du service en fonction du temps de réponse du service et du nombre d’erreurs.
- Critique (rouge) - Indique si le temps de réponse moyen du service est supérieur à 200 ms ET le nombre d’erreurs > 0
- Avis (orange) - Indique si le temps de réponse moyen du service est supérieur à 200 ms OU le nombre d’erreurs > 0
- Bon (vert) - Indique l’absence d’erreur et le temps de réponse moyen du service est inférieur à 200 ms
- L’état du client, tel que Critique, RévisionetBon. La console NetScaler affiche l’état du client en fonction de la latence du réseau client et du nombre d’erreurs.
- Critique (rouge)- Indique si la latence moyenne du réseau client est > 200 ms ET le nombre d’erreurs > 0
- Avis (orange) - Indique lorsque la latence moyenne du réseau client est > 200 ms OU le nombre d’erreurs > 0
- Bon (vert) - Indique l’absence d’erreur et la latence moyenne du réseau client est inférieure à 200 ms
- L’état du serveur virtuel, tel que Critique, RévisionetBon. La console NetScaler affiche l’état du serveur virtuel en fonction du score de l’application.
- Critique (rouge) - Indique lorsque le score de l’application est inférieur à 40
- Avis (orange) - Indique quand le score de l’application se situe entre 40 et 75
- Bon (vert) - Indique lorsque le score de l’application est > 75
Points à noter :
- Seuls les serveurs virtuels d’équilibrage de charge, de commutation de contenu et GSLB sont affichés dans le graphique de service.
- Si aucun serveur virtuel n’est lié à une application personnalisée, les détails ne sont pas visibles dans le graphique de service de l’application.
- Vous pouvez afficher les mesures des clients et des services dans le graphique des services uniquement si des transactions actives ont lieu entre des serveurs virtuels et une application Web.
- Si aucune transaction active n’est disponible entre les serveurs virtuels et l’application Web, vous pouvez uniquement afficher les détails dans le graphique de service en fonction des données de configuration telles que l’équilibrage de charge, la commutation de contenu, les serveurs virtuels GSLB et les services.
- Les mises à jour de la configuration de l’application peuvent prendre 10 minutes pour apparaître dans le graphique de service.
Pour plus d’informations, consultez la section Graphique de service pour les applications.
Pour commencer, consultez la documentation Service Graph.
Résolution des problèmes pour les équipes NetScaler
Examinons certains des attributs les plus courants pour le dépannage de la plate-forme NetScaler et comment ces techniques de dépannage s’appliquent aux déploiements de niveau 1 pour les topologies de microservices.
NetScaler possède une interface de ligne de commande (CLI) qui affiche les commandes en temps réel et est utile pour déterminer les configurations d’exécution, les statiques et la configuration des stratégies. Cela est facilité par la commande « SHOW ».
SHOW - effectuer des opérations CLI ADC :
>Show running config (-summary -fullValues)
Ability to search (grep command)
>“sh running config | -i grep vserver”
Check the version.
>Show license
“sh license"
<!--NeedCopy-->
Afficher les statistiques SSL
>Sh ssl
System
Frontend
Backend
Encryption
<!--NeedCopy-->
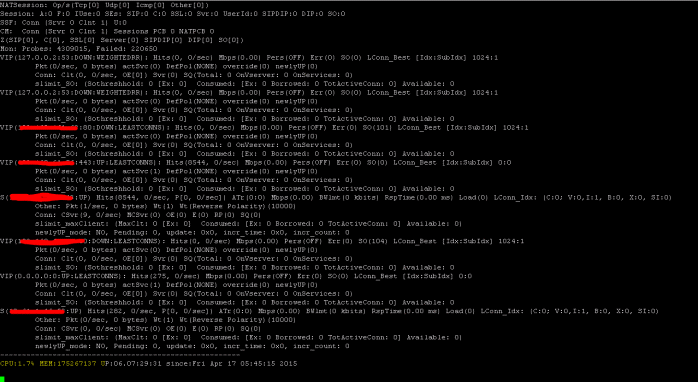
NetScaler dispose d’une commande permettant d’énumérer les statistiques de tous les objets sur la base d’un intervalle de compteur de sept (7) secondes. Cela est facilité par la commande « STAT ».
Télémétrie L3-L7 hautement granulaire par NetScaler
- Niveau système : utilisation du processeur et de la mémoire de l’ADC.
- Protocole HTTP : #Requests /Responses, split GET/POST, erreurs HTTP pour N-S et E-W (pour le service mesh lite uniquement, sidecar bientôt).
- SSL : #Sessions et #Handshakes pour le trafic N-S et E-W pour le service mesh lite uniquement.
- Protocole IP : #Packets reçu/envoyé, #Bytes reçu/envoyé, paquets #Truncated et recherche d’adresse #IP.
- NetScaler AAA : Séances #Active
- Interface : paquets multidiffusion #Total, #Total octets transférés et paquets #Jumbo reçus/envoyés.
- Serveur virtuel d’équilibrage de charge et serveur virtuel de commutation de contenu : #Packets, #Hits et #Bytes reçus/envoyés.
STAT - effectuer des opérations CLI ADC :
>Statistics
“stat ssl”
<!--NeedCopy-->
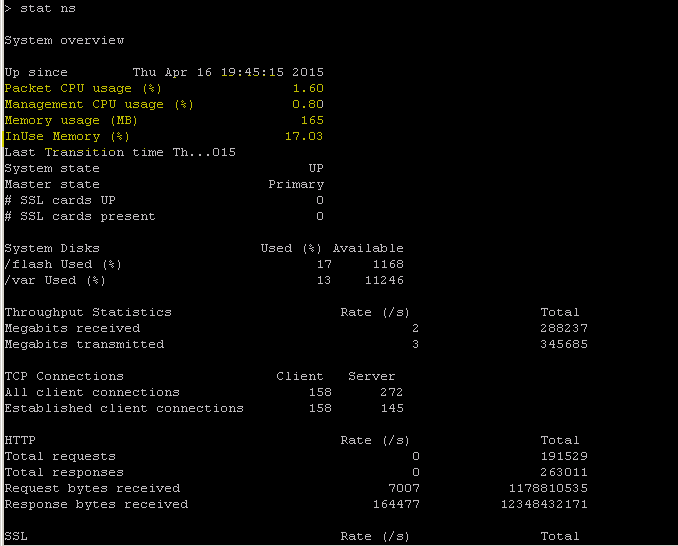
NetScaler possède une structure d’archivage des journaux qui permet de rechercher des statistiques et des compteurs lors de la résolution d’erreurs spécifiques via la commande « NSCONMSG ».
NSCONMSG - fichier journal principal (format de données ns)
Cd/var/nslog
“Mac Moves”
nsconmsg -d current -g nic_err
<!--NeedCopy-->
Nstcpdump
Vous pouvez utiliser nstcpdump pour le dépannage de bas niveau. nstcpdump recueille des informations moins détaillées que nstrace. Ouvrez l’interface de ligne de commande ADC et tapez shell. Vous pouvez utiliser des filtres avec nstcpdump mais ne pouvez pas utiliser de filtres spécifiques aux ressources ADC. La sortie de vidage peut être visualisée directement dans l’écran CLI.
CTRL + C — Appuyez simultanément sur ces touches pour arrêter un nstcpdump.
nstcpdump.sh dst host x.x.x.x : affiche le trafic envoyé à l’hôte de destination.
nstcpdump.sh -n src host x.x.x.x — Affiche le trafic provenant de l’hôte spécifié et ne convertit pas les adresses IP en noms (-n).
nstcpdump.sh host x.x.x.x — Affiche le trafic vers et depuis l’adresse IP de l’hôte spécifiée.
NSTRACE - fichier de suivi des paquets
NSTRACE est un outil de débogage de paquets de bas niveau destiné au dépannage des réseaux. Il vous permet de stocker des fichiers de capture que vous pouvez analyser davantage à l’aide des outils d’analyse. Les deux outils courants sont Network Analyzer et Wireshark.
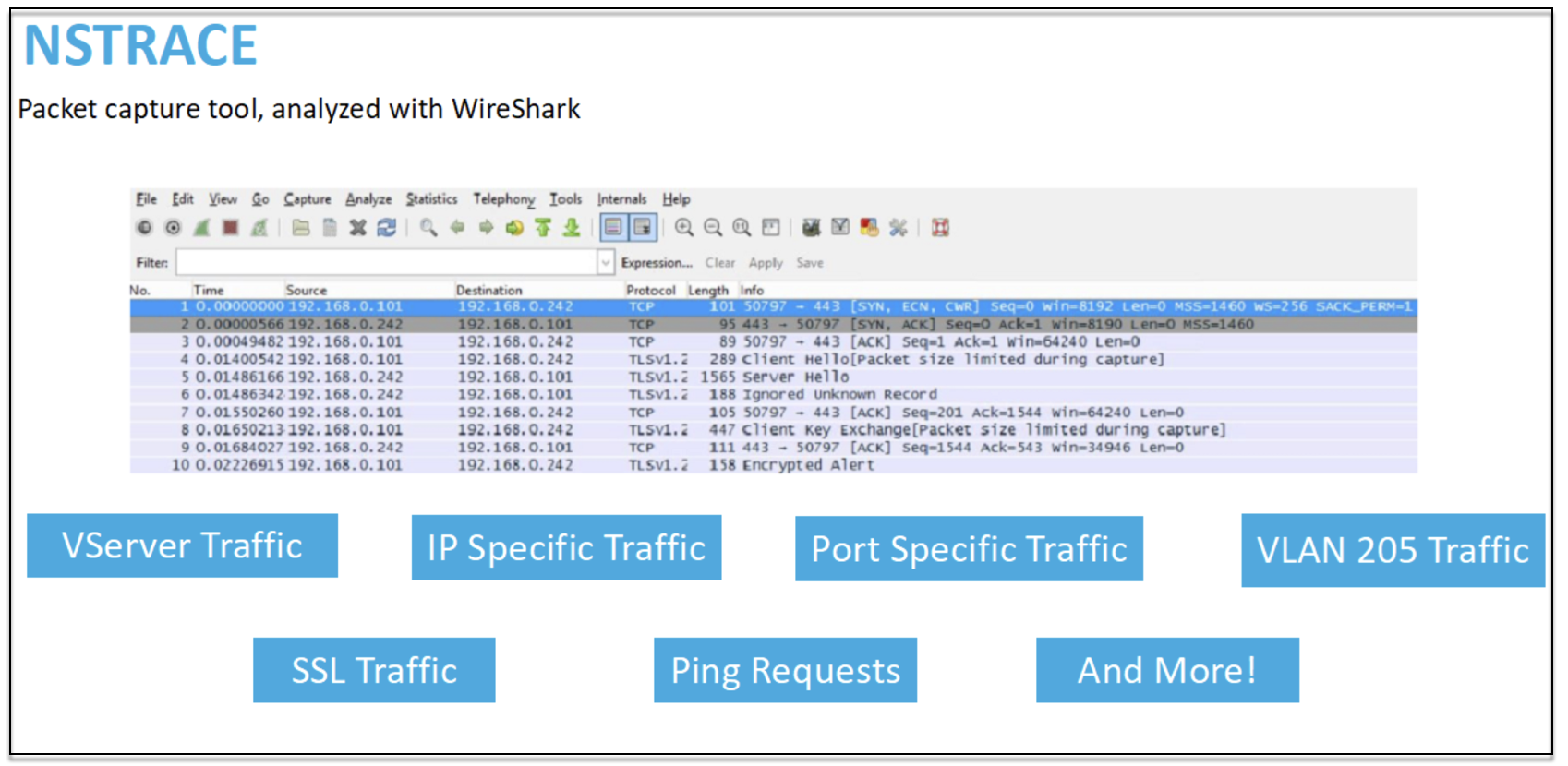
Une fois le fichier de capture NSTRACE créé dans /var/nstrace sur l’ADC, vous pouvez importer le fichier de capture dans Wireshark pour la capture de paquets et l’analyse du réseau.
SYSCTL - Informations détaillées sur l’ADC : description, modèle, plate-forme, processeurs, etc
sysctl -a grep hw.physmem
hw.physmem: 862306304
netscaler.hw_physmem_mb: 822
<!--NeedCopy-->
aaad.debug - Canal ouvert pour les informations de débogage d’authentification

Pour plus d’informations sur la façon de résoudre les problèmes d’authentification via ADC ou ADC Gateway avec le module aaad.debug, consultez l’article de support aaad.debug.
Il est également possible d’obtenir des statistiques de performances et des journaux d’événements directement pour l’ADC. Pour plus d’informations à ce sujet, consultez le document de support ADC.
Dépannage pour les équipes SRE et plateformes
Flux de trafic Kubernetes
Nord/Sud :
- Le trafic Nord/Sud est le trafic circulant de l’utilisateur vers le cluster, via l’entrée.
Est/Ouest :
- Le trafic est/ouest est le trafic circulant autour du cluster Kubernetes : service à service ou service à magasin de données.
Comment NetScaler CPX équilibre la charge du flux de trafic est-ouest dans un environnement Kubernetes
Après avoir déployé le cluster Kubernetes, vous devez intégrer le cluster à ADM en fournissant les détails de l’environnement Kubernetes dans ADM. ADM surveille les modifications apportées aux ressources Kubernetes, telles que les services, les points de terminaison et les règles d’entrée.
Lorsque vous déployez une instance NetScaler CPX dans le cluster Kubernetes, elle s’enregistre automatiquement auprès d’ADM. Dans le cadre du processus d’enregistrement, ADM prend connaissance de l’adresse IP de l’instance CPX et du port sur lequel il peut atteindre l’instance pour la configurer à l’aide des API REST NITRO.
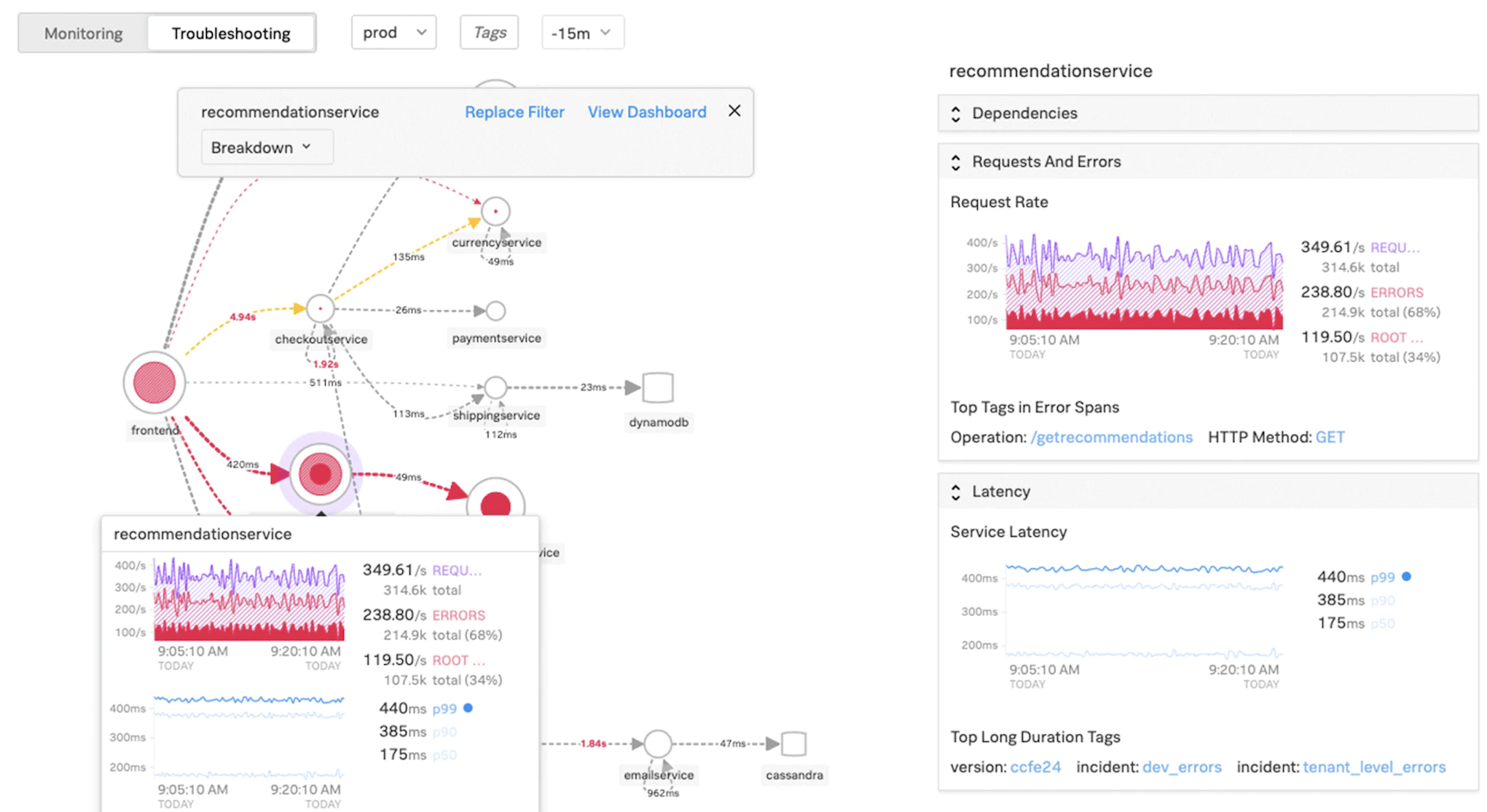
La figure suivante montre comment NetScaler CPX équilibre la charge du flux de trafic est-ouest dans un cluster Kubernetes.
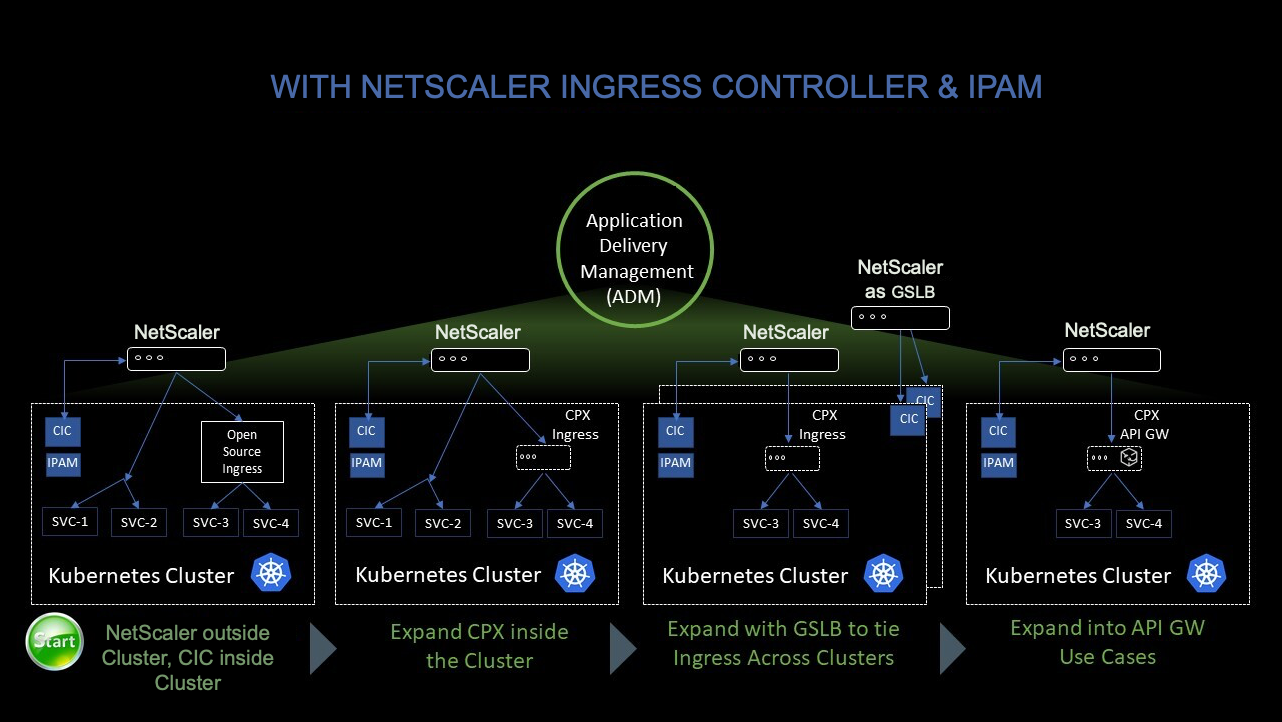
Dans cet exemple,
Le nœud 1 et le nœud 2 des clusters Kubernetes contiennent des instances d’un service frontal et d’un service principal. Lorsque les instances NetScaler CPX sont déployées dans les nœuds 1 et 2, les instances NetScaler CPX sont automatiquement enregistrées auprès d’ADM. Vous devez intégrer manuellement le cluster Kubernetes à ADM en configurant les détails du cluster Kubernetes dans ADM.
Lorsqu’un client demande le service frontal, la charge de ressource d’entrée équilibre la demande entre les instances du service frontal sur les deux nœuds. Lorsqu’une instance du service frontal a besoin d’informations provenant des services principaux du cluster, elle dirige les demandes vers l’instance NetScaler CPX de son nœud. Cette instance NetScaler CPX équilibre la charge des demandes entre les services principaux du cluster, fournissant ainsi un flux de trafic est-ouest.
Graphique de service ADM pour les applications
La fonctionnalité graphique des services de NetScaler Console vous permet de surveiller tous les services sous forme de représentation graphique. Cette fonctionnalité fournit également une analyse détaillée et des mesures utiles. Vous pouvez consulter les graphiques de service pour :
- Applications configurées sur toutes les instances NetScaler
- Applications Kubernetes
- Applications Web à 3 niveaux
Pour commencer, consultez les détails dans le graphique de service.
Afficher les compteurs d’applications de microservices
Le graphique de service affiche également toutes les applications de microservice appartenant aux clusters Kubernetes. Toutefois, le pointeur de la souris sur un service permet d’afficher les détails des mesures.
Vous pouvez consulter les éléments suivants :
- Le nom du service
- Le protocole utilisé par le service tel que SSL, HTTP, TCP, SSL sur HTTP
- Hits — Nombre total d’accès reçus par le service
- Temps de réponse du service — Temps de réponse moyen pris par le service. (Temps de réponse = RTT client + demande le dernier octet — demande le premier octet)
- Erreurs — Les erreurs totales telles que 4xx, 5xx, et ainsi de suite
- Volume de données — Volume total de données traitées par le service
- Espace de noms — Espace de noms du service
- Nom du cluster — Nom du cluster où le service est hébergé
- Erreurs SSL Server : nombre total d’erreurs SSL provenant du service
Ces compteurs et journaux de transactions spécifiques peuvent être extraits via NetScaler Observability Exporter (COE) à l’aide d’une gamme de points de terminaison compatibles. Pour plus d’informations sur COE, consultez les sections suivantes.
Exportateur pour les statistiques de NetScaler
Il s’agit d’un serveur simple qui extrait les statistiques de NetScaler et les exporte via HTTP vers Prometheus. Prometheus peut ensuite être ajouté en tant que source de données à Grafana pour afficher graphiquement les statistiques de NetScaler.
Pour surveiller les statistiques et les compteurs des instances NetScaler, citrix-adc-metric-exporter vous pouvez les exécuter sous forme de conteneur ou de script. L’exportateur collecte des statistiques NetScaler telles que le nombre total d’accès à un serveur virtuel, le taux de requêtes HTTP, le taux de cryptage/déchiffrement SSL, etc. à partir des instances NetScaler et les conserve jusqu’à ce que le serveur Prometheus extrait les statistiques et les enregistre avec un horodatage. Grafana peut ensuite être pointé vers le serveur Prometheus pour récupérer les statistiques, les tracer, définir des alarmes, créer des cartes thermiques, générer des tableaux, etc. selon les besoins pour analyser les statistiques de NetScaler.
Les sections suivantes fournissent des détails sur la configuration de l’exportateur pour qu’il fonctionne dans un environnement tel qu’indiqué dans la figure. Une note sur les entités/métriques NetScaler que l’exportateur extrait par défaut et sur la manière de les modifier est également expliquée.
Pour plus d’informations sur Exporter pour NetScaler, consultez le GitHub de Metrics Exporter.
Suivi distribué du service ADM
Dans le graphique de service, vous pouvez utiliser la vue de suivi distribué pour :
- Analysez les performances globales du service.
- Visualisez le flux de communication entre le service sélectionné et ses services interdépendants.
- Identifier le service qui indique des erreurs et dépanner le service erroné
- Affichez les détails des transactions entre le service sélectionné et chaque service interdépendant.
Prérequis pour le suivi distribué ADM
Pour afficher les informations de suivi du service, vous devez :
- Assurez-vous qu’une application conserve les en-têtes de trace suivants, tout en envoyant tout trafic est-ouest :

- Mettez à jour le fichier YAML CPX avec NS_DISTRIBUTED_TRACING et la valeur sur YES. Pour commencer, consultez la section Suivi distribué.
Analyse de NetScaler Observability Exporter (COE)
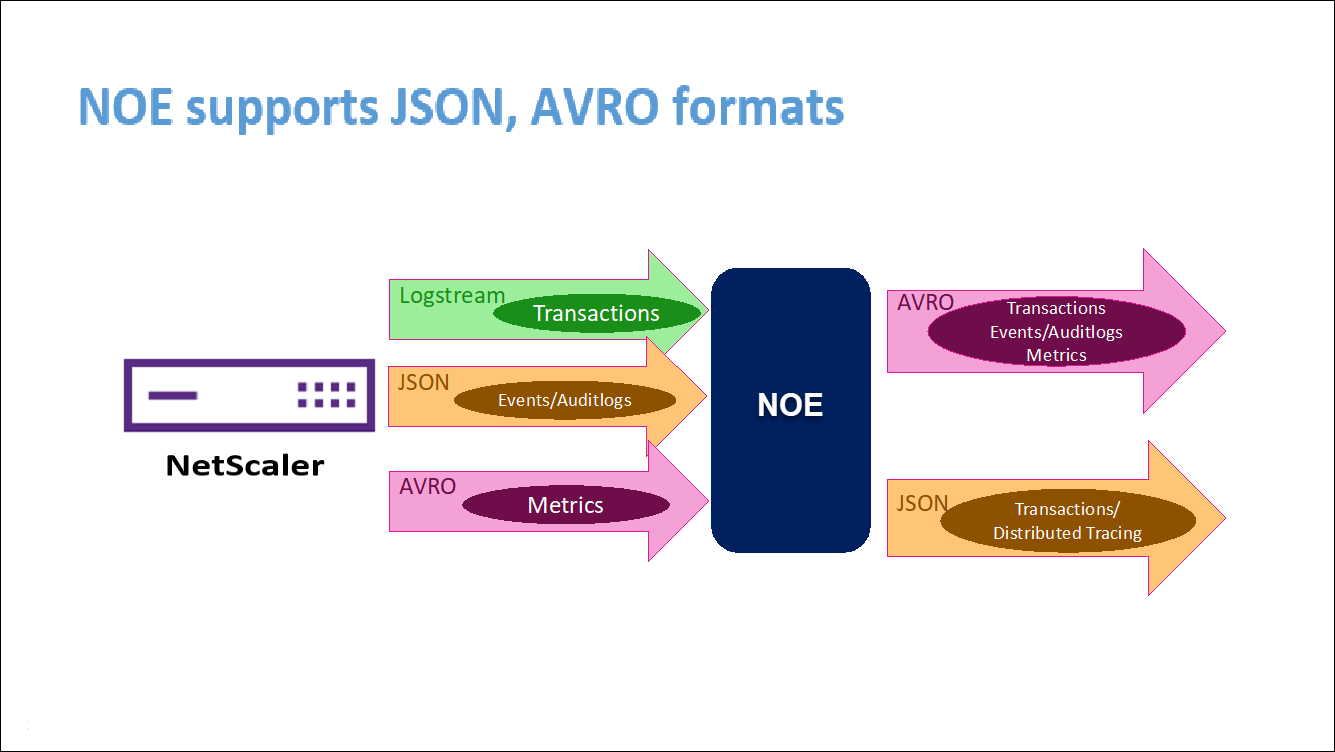
NetScaler Observability Exporter est un conteneur qui collecte des métriques et des transactions auprès de NetScalers et les transforme en formats adaptés (tels que JSON, AVRO) pour les terminaux pris en charge. Vous pouvez exporter les données collectées par NetScaler Observability Exporter vers le point de terminaison souhaité. En analysant les données exportées vers le terminal, vous pouvez obtenir des informations précieuses au niveau des microservices pour les applications fournies par proxy par NetScalers.
Pour plus d’informations sur COE, consultez COE GitHub.
COE avec Elasticsearch comme point de terminaison de transaction

Lorsque Elasticsearch est spécifié comme point de terminaison de la transaction, NetScaler Observability Exporter convertit les données au format JSON. Sur le serveur Elasticsearch, NetScaler Observability Exporter crée des index Elasticsearch pour chaque ADC sur une base horaire. Ces index sont basés sur les données, l’heure, l’UUID de l’ADC et le type de données HTTP (http_event ou http_error). Ensuite, l’exportateur NetScaler Observability télécharge les données au format JSON sous les index de recherche Elastic pour chaque ADC. Toutes les transactions régulières sont placées dans l’index http_event et toutes les anomalies sont placées dans l’index http_error.
Prise en charge du suivi distribué avec Zipkin
Dans une architecture de microservices, une seule demande d’utilisateur final peut s’étendre à plusieurs microservices, ce qui rend difficile le suivi d’une transaction et la résolution des sources d’erreurs. Dans de tels cas, les méthodes traditionnelles de surveillance des performances ne permettent pas de déterminer avec précision où les défaillances se produisent et quelle est la raison de ces mauvaises performances. Vous avez besoin d’un moyen de capturer des points de données spécifiques à chaque microservice traitant une demande et de les analyser pour obtenir des informations pertinentes.
Le suivi distribué répond à ce défi en fournissant un moyen de suivre une transaction de bout en bout et de comprendre comment elle est gérée sur plusieurs microservices.
OpenTracing est une spécification et un ensemble standard d’API pour la conception et la mise en œuvre du suivi distribué. Les traceurs distribués vous permettent de visualiser le flux de données entre vos microservices et d’identifier les goulots d’étranglement dans votre architecture de microservices.
NetScaler Observability Exporter implémente le traçage distribué pour NetScaler et prend actuellement en charge Zipkin en tant que traceur distribué.
Actuellement, vous pouvez surveiller les performances au niveau de l’application à l’aide de NetScaler. À l’aide de NetScaler Observability Exporter avec NetScaler, vous pouvez obtenir des données de suivi pour les microservices de chaque application via un proxy par votre NetScaler CPX, MPX ou VPX.
Pour commencer, consultez l’ exportateur d’observabilité GitHub.
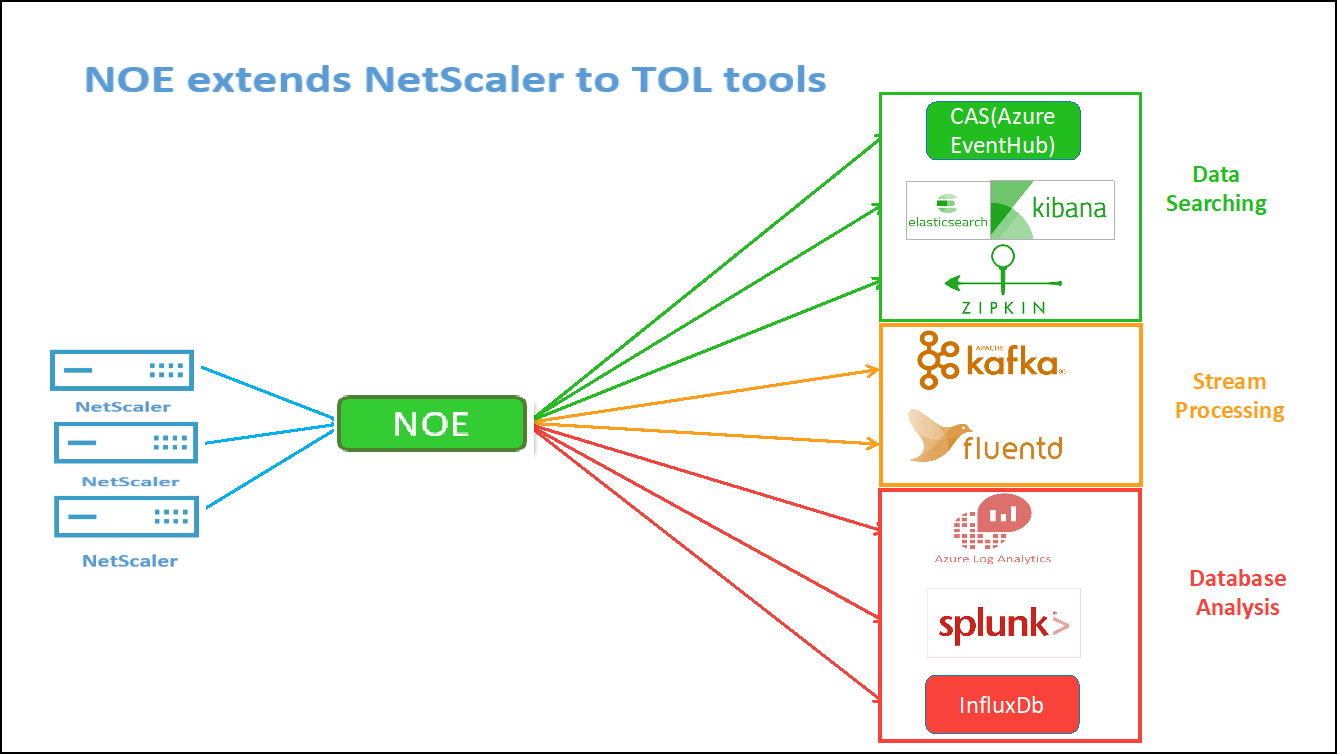
Zipkin pour le débogage des applications
Zipkin est un système de traçage distribué open source basé sur l’article de Dapper de Google. Dapper est le système de Google pour son système de traçage distribué en production. Google explique cela dans son article : « Nous avons conçu Dapper pour fournir aux développeurs de Google plus d’informations sur le comportement des systèmes distribués complexes ». L’observation du système sous différents angles est essentielle lors du dépannage, en particulier lorsqu’un système est complexe et distribué.
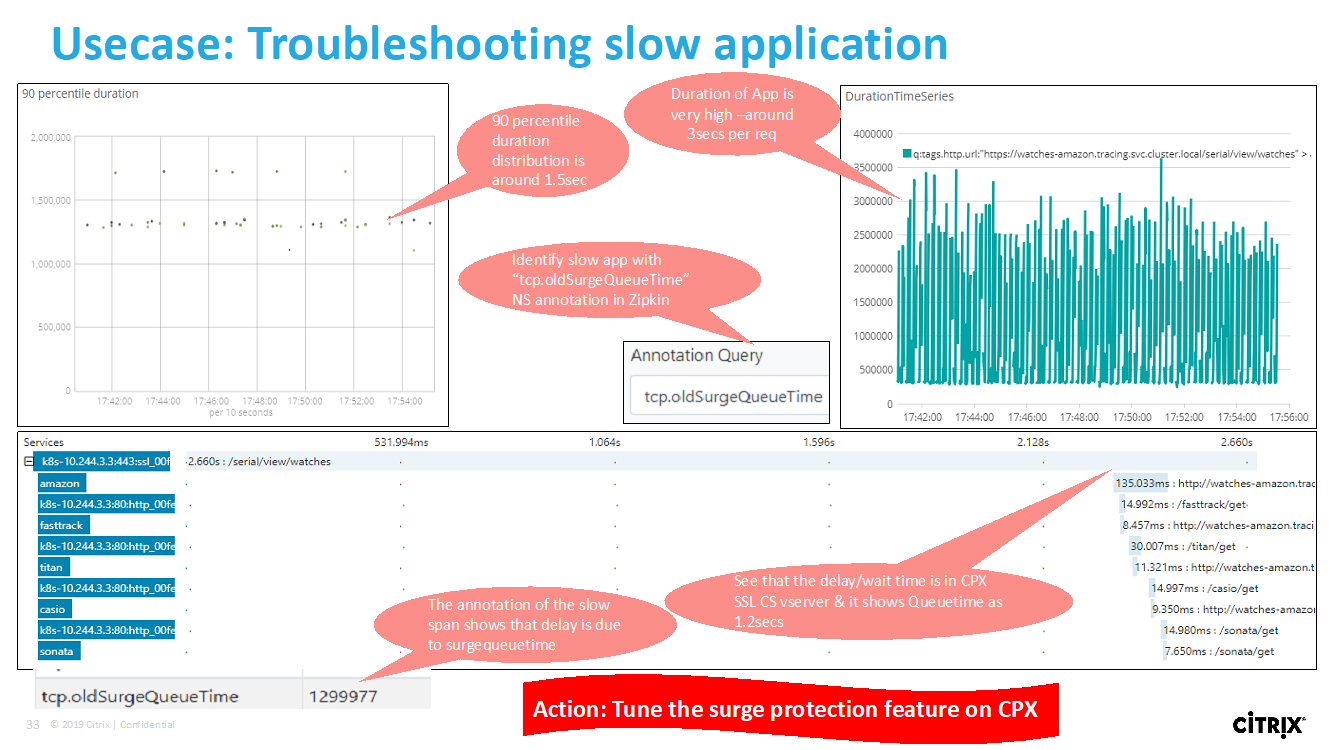
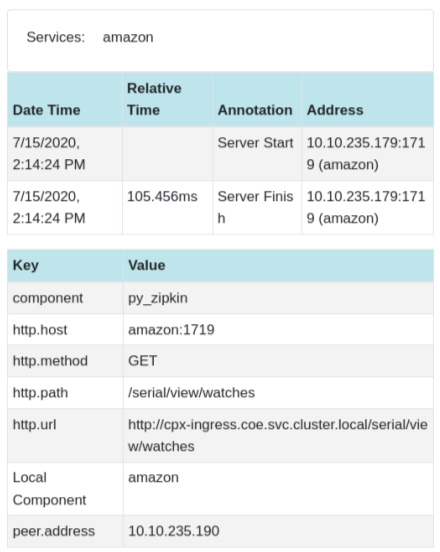
Les données de trace Zipkin suivantes identifient un total de 5 spans et 5 services liés à l’exemple d’application Watches. Les données de suivi montrent les données de portée spécifiques sur les 5 microservices.
Pour commencer, consultez Zipkin.
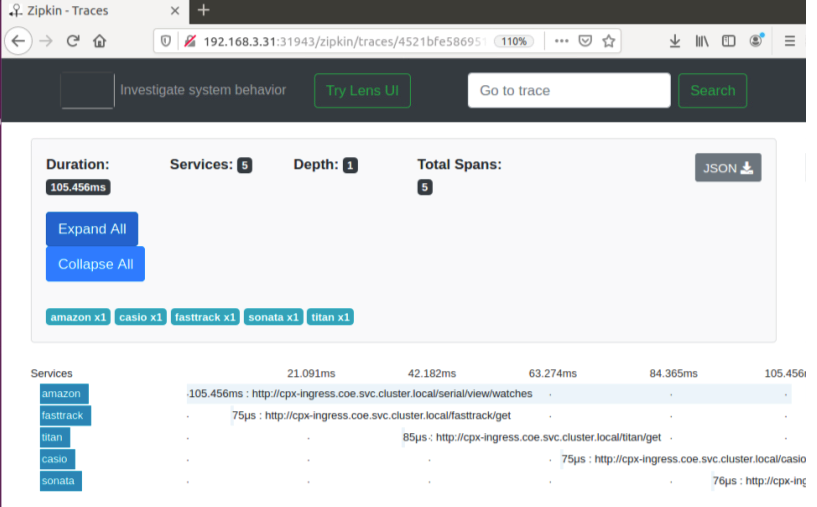
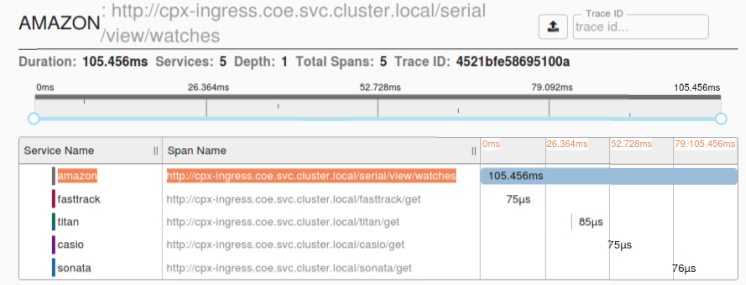
Exemple de plage Zipkin montrant la latence de l’application pour la demande initiale de chargement de
Kibana pour l’affichage des données
Kibana est une interface utilisateur ouverte qui vous permet de visualiser vos données Elasticsearch et de naviguer dans Elastic Stack. Faites n’importe quoi, du suivi du chargement des requêtes à la compréhension de la façon dont les demandes circulent dans vos applications
Que vous soyez analyste ou administrateur, Kibana rend vos données exploitables en fournissant les trois fonctions clés suivantes :
- Une plateforme d’analyse et de visualisation open source. Utilisez Kibana pour explorer vos données Elasticsearch, puis créez de superbes visualisations et tableaux de bord.
- Une interface utilisateur pour gérer la pile Elastic. Gérez vos paramètres de sécurité, attribuez des rôles d’utilisateur, prenez des instantanés, regroupez vos données et bien plus encore, le tout depuis le confort d’une interface utilisateur Kibana.
- Un hub centralisé pour les solutions Elastic. De l’analyse des journaux à la découverte de documents en passant par le SIEM, Kibana est le portail d’accès à ces fonctionnalités et à d’autres.
Kibana est conçu pour utiliser Elasticsearch comme source de données. Considérez Elasticsearch comme le moteur qui stocke et traite les données, avec Kibana en tête.
Sur la page d’accueil, Kibana propose les options suivantes pour ajouter des données :
- Importez des données en utilisant le visualiseur de données de fichier.
- Configurez un flux de données vers Elasticsearch à l’aide de nos didacticiels intégrés. S’il n’existe aucun didacticiel pour vos données, consultez l’ aperçu Beats pour en savoir plus sur les autres expéditeurs de données de la famille Beats.
- Ajoutez un exemple d’ensemble de données et faites un essai routier de Kibana sans charger de données vous-même.
- Indexez vos données dans Elasticsearch avec des API REST ou des bibliothèques clientes
Kibana utilise un modèle d’index pour indiquer les indices Elasticsearch à explorer. Si vous téléchargez un fichier, exécutez un didacticiel intégré ou ajoutez des exemples de données, vous obtenez un modèle d’index gratuitement et vous pouvez commencer à explorer. Si vous chargez vos propres données, vous pouvez créer un modèle d’index dans Stack Management.
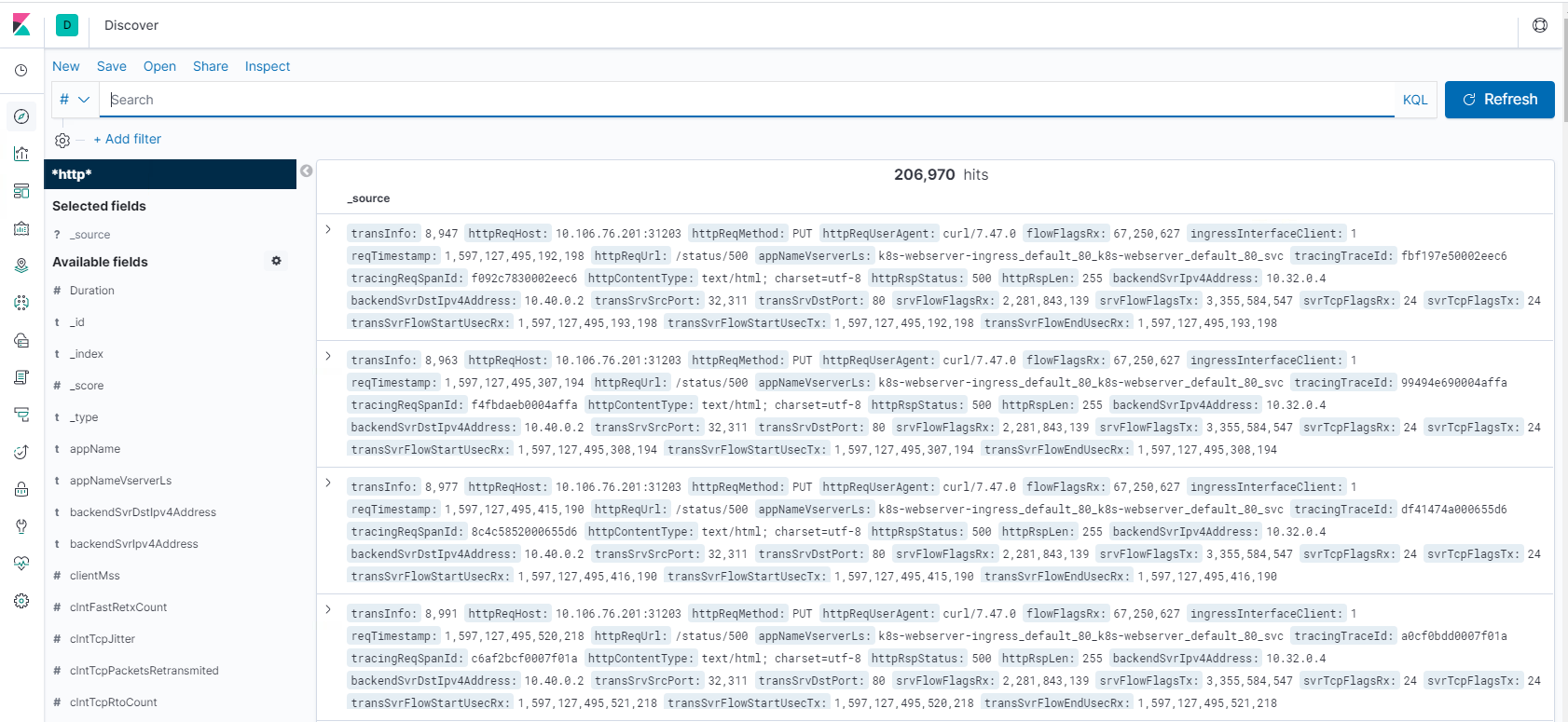
Étape 1 : Configurer le modèle d’index pour Logstash
Étape 2 : Sélectionnez l’index et générez le trafic à remplir.
Étape 3 : générer une application à partir des données non structurées issues des flux de journaux.
Étape 4 : Kibana met en forme l’entrée Logstash pour créer des rapports et des tableaux de bord.
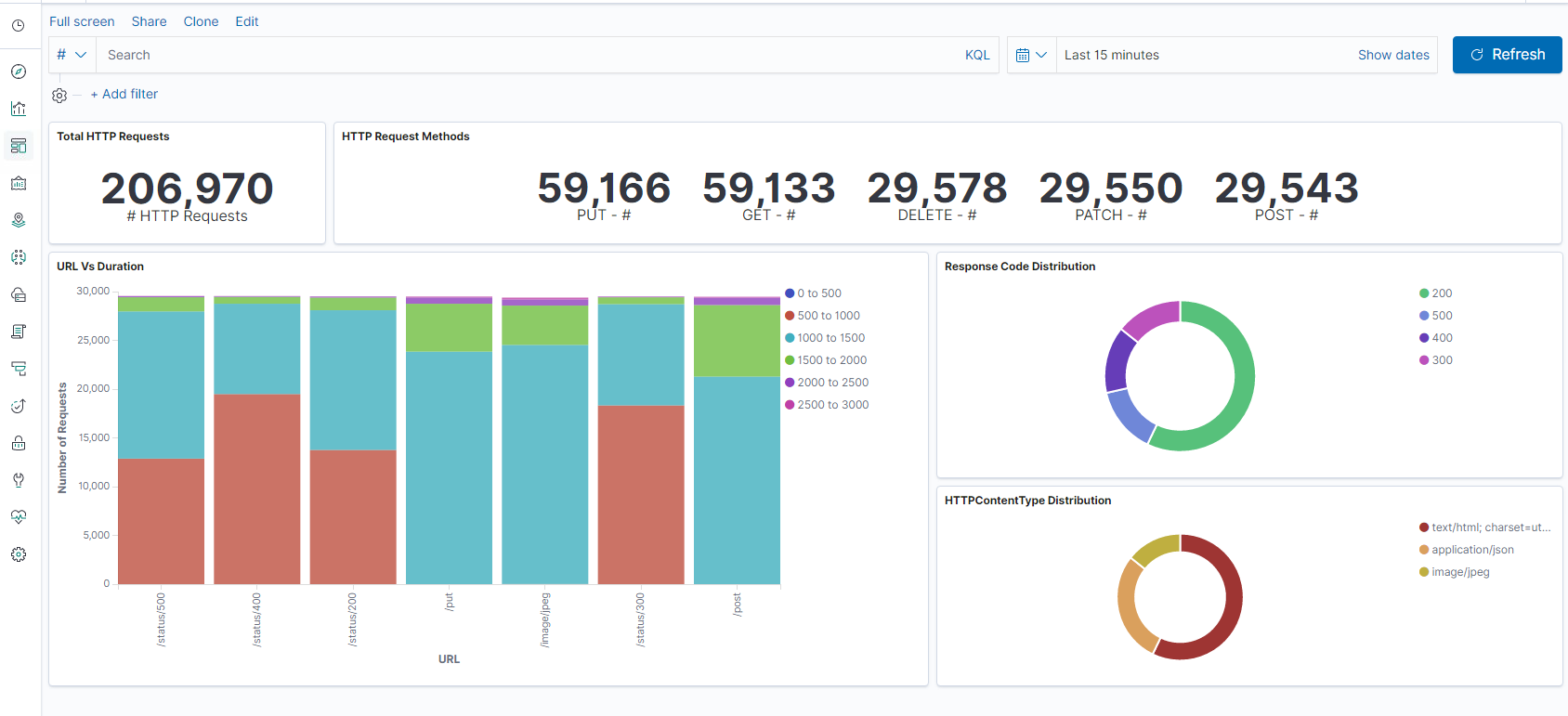
- Plage de temps
- Vue tabulaire
- Nombre de visites en fonction de l’application.
- IP de temps, agent, machine.OS, code de réponse (200), URL
- Filtre sur les valeurs
Étape 5 : Visualisez les données dans un rapport d’agrégations.
- Agrégation des résultats dans un rapport graphique (secteur, graphique, etc.)
Partager
Partager
Dans cet article
- Vue d’ensemble
- Présentation des performances et de la latence
- Tableau de bord SSL de NetScaler Application Delivery Management
- Intégrations tierces
- Comment équilibrer la charge du trafic entrant vers une application basée sur TCP ou UDP
- Surveillez et améliorez les performances de vos applications basées sur TCP ou UDP
- Service de gestion de la diffusion des applications (ADM) NetScaler
- Résolution des problèmes pour les équipes NetScaler
- Dépannage pour les équipes SRE et plateformes
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.