Alertas e notificações
Os alertas são exibidos no Director no painel e em outras exibições de alto nível com símbolos de alerta de aviso e críticos. Os alertas estão disponíveis para sites com licença Premium. Os alertas são atualizados automaticamente a cada minuto; você também pode atualizar os alertas sob demanda.
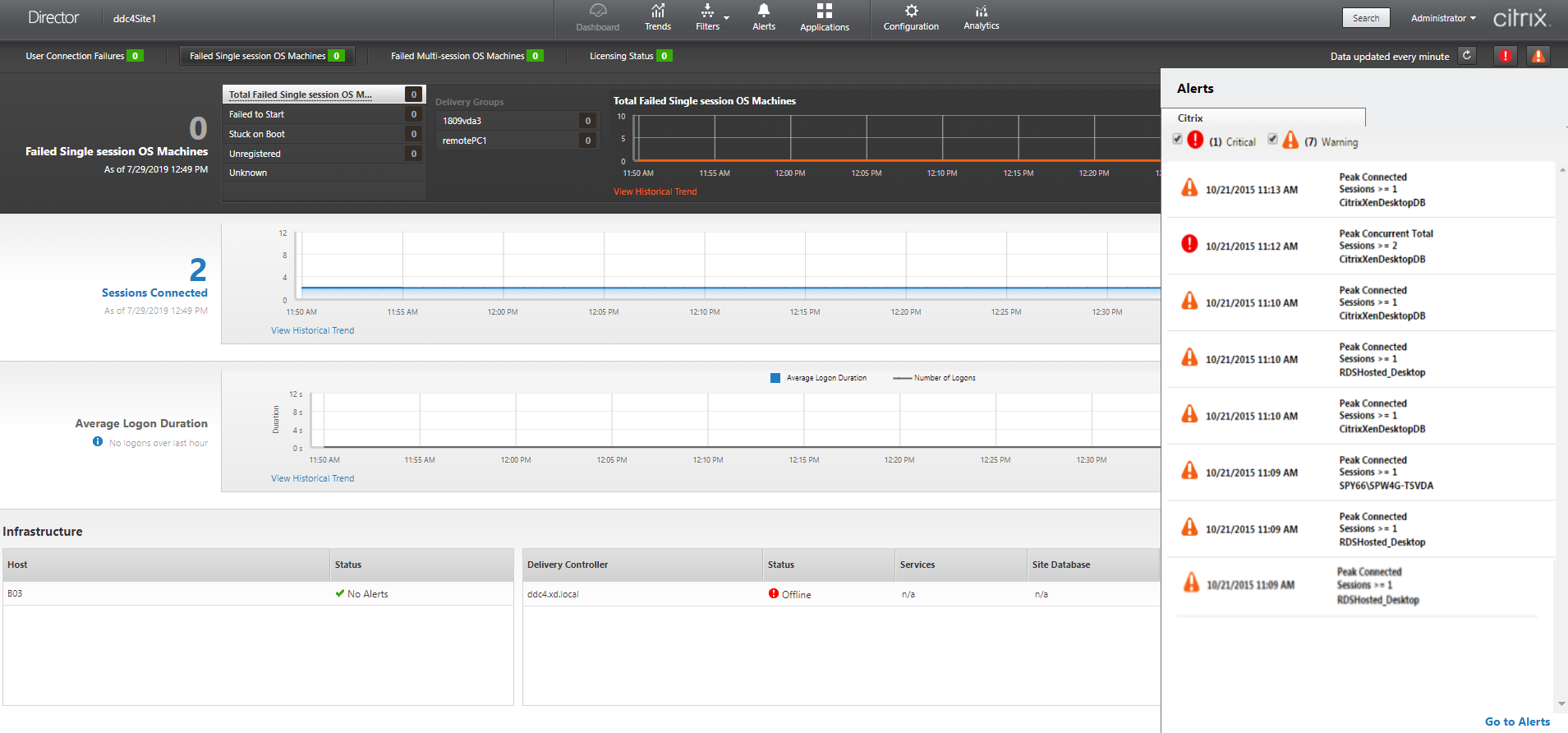
Um alerta de aviso (triângulo âmbar) indica que o limite de aviso de uma condição foi atingido ou excedido.
Um alerta crítico (círculo vermelho) mostra que o limite crítico de uma condição foi atingido ou excedido.
Você pode visualizar informações mais detalhadas sobre os alertas selecionando um alerta na barra lateral, clicando no link “Ir para Alertas” na parte inferior da barra lateral ou selecionando “Alertas” na parte superior da página do Director.
Na exibição “Alertas”, você pode filtrar e exportar alertas. Por exemplo, máquinas de SO de várias sessões com falha para um Delivery Group específico no último mês, ou todos os alertas para um usuário específico. Para obter mais informações, consulte Exportar relatórios.
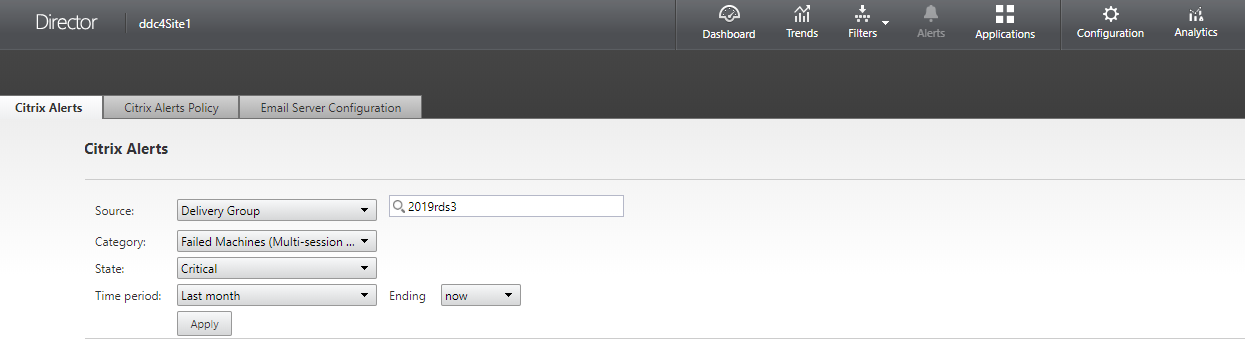
Alertas Citrix®
Alertas Citrix são alertas monitorados no Director que se originam de componentes Citrix. Você pode configurar alertas Citrix no Director em “Alertas” > “Política de Alertas Citrix”. Como parte da configuração, você pode definir notificações a serem enviadas por e-mail para indivíduos e grupos quando os alertas excederem os limites que você configurou. Para obter mais informações sobre como configurar Alertas Citrix, consulte Criar políticas de alerta.
Nota:
Certifique-se de que seu firewall, proxy ou Microsoft Exchange Server não bloqueiem os alertas por e-mail.
Políticas de alerta inteligentes
Um conjunto de políticas de alerta integradas com valores de limite predefinidos está disponível para Delivery Groups e escopo de VDA de SO de várias sessões. Este recurso requer a versão 7.18 ou posterior do Delivery Controller. Você pode modificar os parâmetros de limite das políticas de alerta integradas em “Alertas” > “Política de Alertas Citrix”. Essas políticas são criadas quando há pelo menos um destino de alerta — um Delivery Group ou um VDA de SO de várias sessões definido em seu site. Além disso, esses alertas integrados são adicionados automaticamente a um novo grupo de entrega ou a um VDA de SO de várias sessões.
Caso você atualize o Director e seu site, as políticas de alerta da sua instância anterior do Director são transferidas. As políticas de alerta integradas são criadas somente se não existirem regras de alerta correspondentes no banco de dados do Monitor.
Para os valores de limite das políticas de alerta integradas, consulte a seção Condições das políticas de alerta.
Alertas SCOM
Os alertas SCOM exibem informações de alerta do Microsoft System Center 2012 Operations Manager (SCOM) para fornecer uma indicação mais abrangente da integridade e desempenho do data center no Director. Para obter mais informações, consulte a seção Configurar integração de alertas SCOM.
O número de alertas exibidos ao lado dos ícones de alerta antes de você expandir a barra lateral é a soma combinada dos alertas Citrix e SCOM.
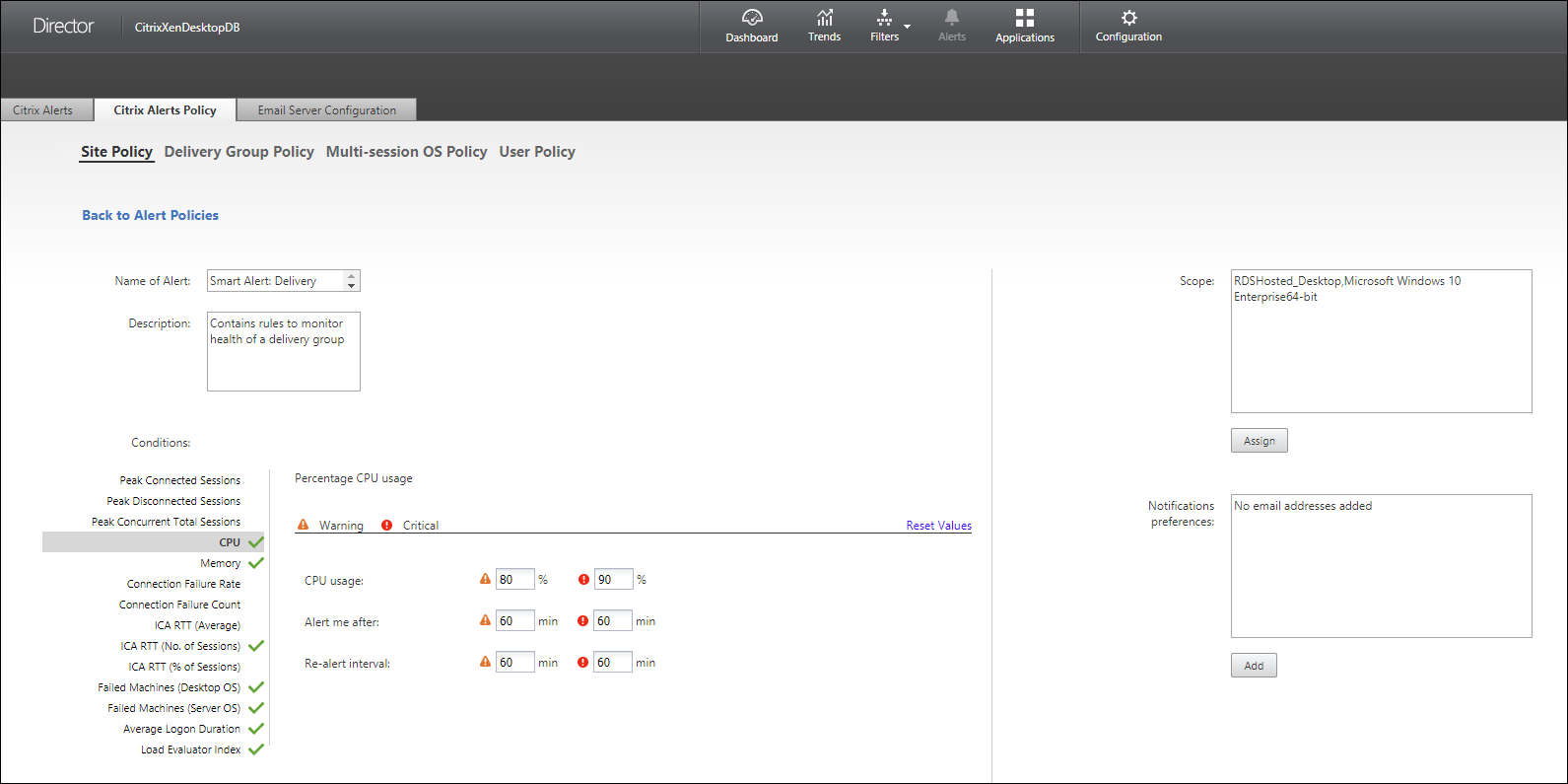
Criar políticas de alerta
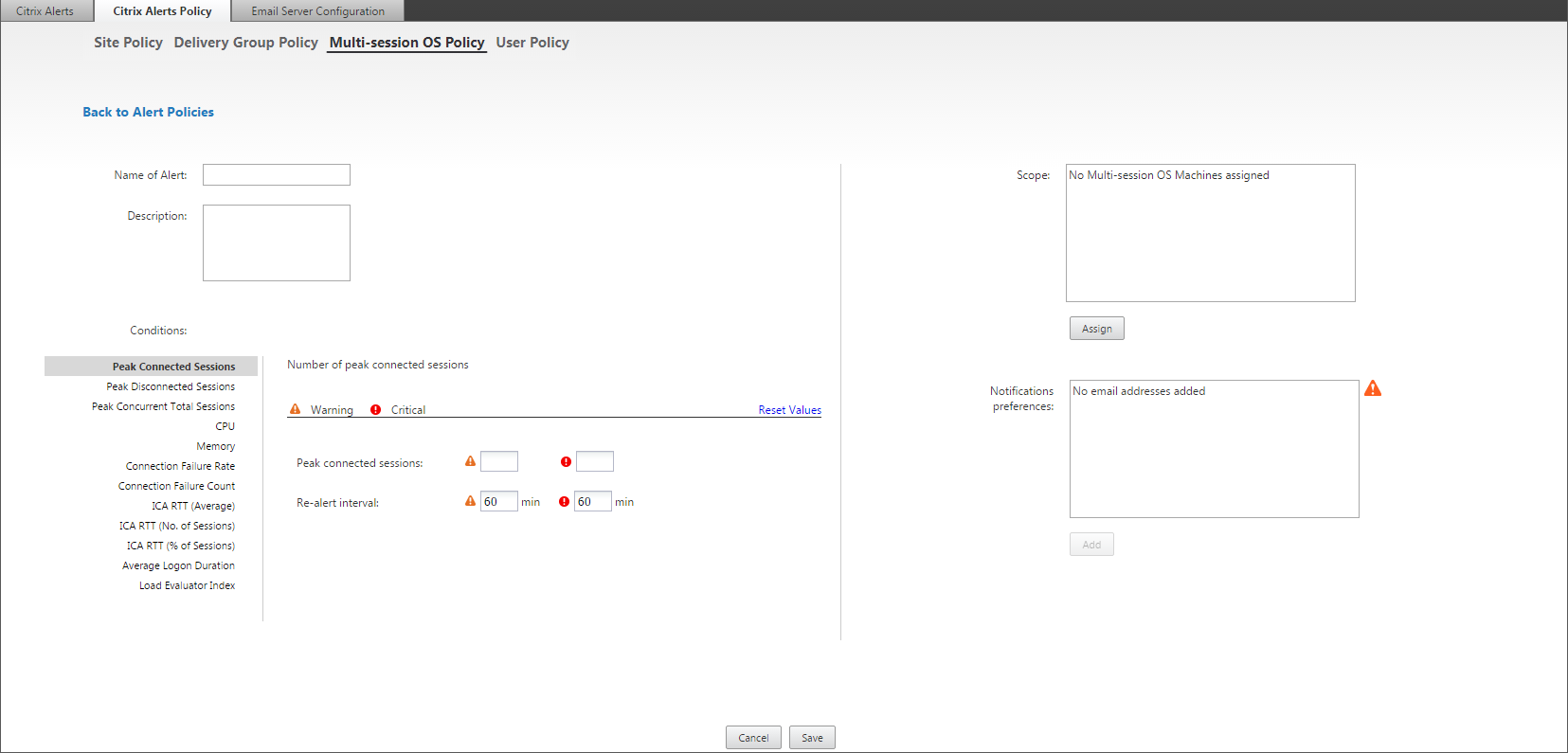
Para criar uma nova política de alertas, por exemplo, para gerar um alerta quando um conjunto específico de critérios de contagem de sessões for atendido:
- Vá para “Alertas” > “Política de Alertas Citrix” e selecione, por exemplo, “Política de SO de várias sessões”.
- Clique em “Criar”.
- Nomeie e descreva a política e, em seguida, defina as condições que devem ser atendidas para que o alerta seja acionado. Por exemplo, especifique as contagens de Aviso e Crítico para “Sessões Conectadas de Pico”, “Sessões Desconectadas de Pico” e “Sessões Concorrentes Totais de Pico”. Os valores de aviso não devem ser maiores que os valores críticos. Para obter mais informações, consulte Condições das políticas de alerta.
- Defina o “Intervalo de Re-alerta”. Se as condições para o alerta ainda forem atendidas, o alerta será acionado novamente neste intervalo de tempo e, se configurado na política de alerta, uma notificação por e-mail será gerada. Um alerta ignorado não gera uma notificação por e-mail no intervalo de re-alerta.
- Defina o “Escopo”. Por exemplo, defina para um Delivery Group específico.
- Em “Preferências de Notificação”, especifique quem deve ser notificado por e-mail quando o alerta for acionado. Você deve especificar um servidor de e-mail na guia “Configuração do Servidor de E-mail” para definir as “Preferências de Notificação” por e-mail nas “Políticas de Alerta”.
- Clique em “Salvar”.
A criação de uma política com 20 ou mais Delivery Groups definidos no “Escopo” pode levar aproximadamente 30 segundos para concluir a configuração. Um indicador de carregamento é exibido durante esse tempo.
A criação de mais de 50 políticas para até 20 Delivery Groups exclusivos (1000 destinos de Delivery Group no total) pode resultar em um aumento no tempo de resposta (mais de 5 segundos).
Mover uma máquina contendo sessões ativas de um Delivery Group para outro pode acionar alertas errôneos do Delivery Group que são definidos usando parâmetros da máquina.
Condições das políticas de alerta
Encontre abaixo as categorias de alerta, ações recomendadas para mitigar o alerta e condições de política integradas, se definidas. As políticas de alerta integradas são definidas para intervalos de alerta e re-alerta de 60 minutos.
Sessões Conectadas de Pico
- Verifique a exibição “Tendências de Sessão” do Director para sessões conectadas de pico.
- Verifique se há capacidade suficiente para acomodar a carga de sessão.
- Adicione novas máquinas, se necessário.
Sessões Desconectadas de Pico
- Verifique a exibição “Tendências de Sessão” do Director para sessões desconectadas de pico.
- Verifique se há capacidade suficiente para acomodar a carga de sessão.
- Adicione novas máquinas, se necessário.
- Faça logoff de sessões desconectadas, se necessário.
Sessões Concorrentes Totais de Pico
- Verifique a exibição “Tendências de Sessão” no Director para sessões concorrentes de pico.
- Verifique se há capacidade suficiente para acomodar a carga de sessão.
- Adicione novas máquinas, se necessário.
- Faça logoff de sessões desconectadas, se necessário.
CPU
A porcentagem de uso da CPU indica o consumo geral da CPU no VDA, incluindo o dos processos. Você pode obter mais informações sobre a utilização da CPU por processos individuais na página “Detalhes da Máquina” do VDA correspondente.
- Vá para “Detalhes da Máquina” > “Visualizar Utilização Histórica” > “10 Principais Processos”, identifique os processos que consomem CPU. Certifique-se de que a política de monitoramento de processos esteja habilitada para iniciar a coleta de estatísticas de uso de recursos em nível de processo.
- Encerre o processo, se necessário.
- Encerrar o processo causa a perda de dados não salvos.
-
Se tudo estiver funcionando como esperado, adicione recursos de CPU adicionais no futuro.
Nota:
A configuração da política, “Habilitar monitoramento de recursos”, é permitida por padrão para o monitoramento de contadores de desempenho de CPU e memória em máquinas com VDAs. Se essa configuração de política estiver desabilitada, os alertas com condições de CPU e memória não serão acionados. Para obter mais informações, consulte Configurações da política de monitoramento.
Condições da política inteligente:
- Escopo: Delivery Group, escopo de SO de várias sessões
- Valores de limite: Aviso - 80%, Crítico - 90%
Memória
A porcentagem de uso da memória indica o consumo geral da memória no VDA, incluindo o dos processos. Você pode obter mais informações sobre o uso da memória por processos individuais na página “Detalhes da Máquina” do VDA correspondente.
- Vá para “Detalhes da Máquina” > “Visualizar Utilização Histórica” > “10 Principais Processos”, identifique os processos que consomem memória. Certifique-se de que a política de monitoramento de processos esteja habilitada para iniciar a coleta de estatísticas de uso de recursos em nível de processo.
- Encerre o processo, se necessário.
- Encerrar o processo causa a perda de dados não salvos.
-
Se tudo estiver funcionando como esperado, adicione memória adicional no futuro.
Nota:
A configuração da política, “Habilitar monitoramento de recursos”, é permitida por padrão para o monitoramento de contadores de desempenho de CPU e memória em máquinas com VDAs. Se essa configuração de política estiver desabilitada, os alertas com condições de CPU e memória não serão acionados. Para obter mais informações, consulte Configurações da política de monitoramento.
Condições da política inteligente:
- Escopo: Delivery Group, escopo de SO de várias sessões
- Valores de limite: Aviso - 80%, Crítico - 90%
Taxa de Falha de Conexão
Porcentagem de falhas de conexão na última hora.
- Calculado com base no total de falhas em relação ao total de tentativas de conexão.
- Verifique a exibição “Tendências de Falhas de Conexão” do Director para eventos registrados no log de configuração.
- Determine se os aplicativos ou desktops estão acessíveis.
Contagem de Falhas de Conexão
Número de falhas de conexão na última hora.
- Verifique a exibição “Tendências de Falhas de Conexão” do Director para eventos registrados no log de configuração.
- Determine se os aplicativos ou desktops estão acessíveis.
ICA® RTT (Média)
Tempo médio de ida e volta (RTT) do ICA.
- Verifique o Citrix ADM para uma análise detalhada do ICA RTT para determinar a causa raiz. Para obter mais informações, consulte a documentação do Citrix ADM.
- Se o Citrix ADM não estiver disponível, verifique a exibição “Detalhes do Usuário” do Director para o ICA RTT e a Latência, e determine se é um problema de rede ou um problema com aplicativos ou desktops.
ICA RTT (Nº de Sessões)
Número de sessões que excedem o limite de tempo de ida e volta (RTT) do ICA.
- Verifique o Citrix ADM para o número de sessões com alto ICA RTT. Para obter mais informações, consulte a documentação do Citrix ADM.
-
Se o Citrix ADM não estiver disponível, trabalhe com a equipe de rede para determinar a causa raiz.
Condições da política inteligente:
- Escopo: Delivery Group, escopo de SO de várias sessões
- Valores de limite: Aviso - 300 ms para 5 ou mais sessões, Crítico - 400 ms para 10 ou mais sessões
ICA RTT (% de Sessões)
Porcentagem de sessões que excedem o tempo médio de ida e volta (RTT) do ICA.
- Verifique o Citrix ADM para o número de sessões com alto ICA RTT. Para obter mais informações, consulte a documentação do Citrix ADM.
- Se o Citrix ADM não estiver disponível, trabalhe com a equipe de rede para determinar a causa raiz.
ICA RTT (Usuário)
Tempo de ida e volta (RTT) do ICA que é aplicado às sessões iniciadas pelo usuário especificado. O alerta é acionado se o ICA RTT for maior que o limite em pelo menos uma sessão.
Máquinas com Falha (SO de Sessão Única)
Número de máquinas de SO de sessão única com falha. As falhas podem ocorrer por várias razões, conforme mostrado nas exibições “Painel” e “Filtros” do Director.
-
Execute os diagnósticos do Citrix Scout para determinar a causa raiz. Para obter mais informações, consulte Solucionar problemas do usuário.
Condições da política inteligente:
- Escopo: Escopo do Delivery Group
- Valores de limite: Aviso - 1, Crítico - 2
Máquinas com Falha (SO de Várias Sessões)
Número de máquinas de SO de várias sessões com falha. As falhas podem ocorrer por várias razões, conforme mostrado nas exibições “Painel” e “Filtros” do Director.
-
Execute os diagnósticos do Citrix Scout para determinar a causa raiz.
Condições da política inteligente:
- Escopo: Delivery Group, escopo de SO de várias sessões
- Valores de limite: Aviso - 1, Crítico - 2
Duração Média de Logon
Duração média de logon para logons que ocorreram na última hora.
- Verifique o Painel do Director para obter métricas atualizadas sobre a duração do logon. Um grande número de usuários fazendo logon em um curto período pode aumentar a duração do logon.
-
Verifique a linha de base e o detalhamento dos logons para identificar a causa. Para obter mais informações, consulte Diagnosticar problemas de logon do usuário
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de múltiplas sessões
- Valores de limite: Aviso - 45 segundos, Crítico - 60 segundos
Duração do Logon (Usuário)
Duração do logon para logons do usuário especificado que ocorreram na última hora.
Índice do Avaliador de Carga
Valor do Índice do Avaliador de Carga nos últimos 5 minutos.
-
Verifique o Director para Máquinas de SO de múltiplas sessões que possam ter um pico de carga (Carga máxima). Visualize tanto o Painel (falhas) quanto o relatório de Tendências do Índice do Avaliador de Carga.
Condições da política inteligente:
- Escopo: Grupo de Entrega, escopo de SO de múltiplas sessões
- Valores de limite: Aviso - 80%, Crítico - 90%
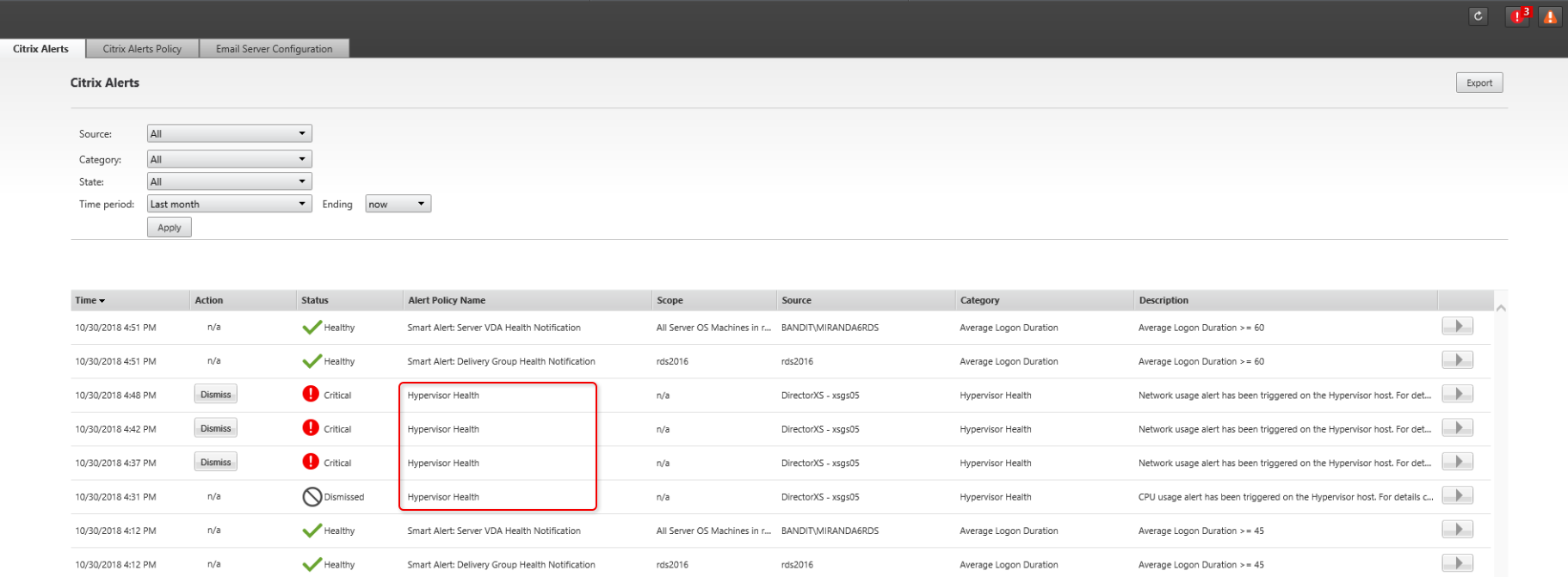
Monitoramento de Alertas do Hypervisor
O Director exibe alertas para monitorar a integridade do hypervisor. Alertas do Citrix Hypervisor™ e VMware vSphere ajudam a monitorar parâmetros e estados do hypervisor. O status da conexão com o hypervisor também é monitorado para fornecer um alerta caso o cluster ou pool de hosts seja reiniciado ou esteja indisponível.
Para receber alertas do hypervisor, certifique-se de que uma conexão de hospedagem seja criada no Citrix Studio. Para obter mais informações, consulte Conexões e recursos. Somente essas conexões são monitoradas para alertas do hypervisor. A tabela a seguir descreve os vários parâmetros e estados dos alertas do Hypervisor.
| Alerta | Hypervisores Suportados | Acionado por | Condição | Configuração |
|---|---|---|---|---|
| Uso da CPU | Citrix Hypervisor, VMware vSphere | Hypervisor | O limite de alerta de uso da CPU é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Uso da memória | Citrix Hypervisor, VMware vSphere | Hypervisor | O limite de alerta de uso da memória é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Uso da rede | Citrix Hypervisor, VMware vSphere | Hypervisor | O limite de alerta de uso da rede é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Uso do disco | VMware vSphere | Hypervisor | O limite de alerta de uso do disco é atingido ou excedido | Os limites de alerta devem ser configurados no Hypervisor. |
| Conexão do host ou estado de energia | VMware vSphere | Hypervisor | O Host do Hypervisor foi reiniciado ou está indisponível | Os alertas são pré-construídos no VMware vSphere. Nenhuma configuração adicional é necessária. |
| Conexão do hypervisor indisponível | Citrix Hypervisor, VMware vSphere | Delivery Controller™ | A conexão com o hypervisor (pool ou cluster) foi perdida, desligada ou reiniciada. Este alerta é gerado a cada hora enquanto a conexão estiver indisponível. | Os alertas são pré-construídos com o Delivery Controller. Nenhuma configuração adicional é necessária. |
Nota:
Para obter mais informações sobre como configurar alertas, consulte Alertas do Citrix XenCenter ou verifique a documentação de Alertas do VMware vCenter.
A preferência de notificação por e-mail pode ser configurada em Citrix Alerts Policy > site Policy > Hypervisor Health. As condições de limite para as políticas de alerta do Hypervisor podem ser configuradas, editadas, desabilitadas ou excluídas apenas no hypervisor e não no Director. No entanto, a modificação das preferências de e-mail e o descarte de um alerta podem ser feitos no Director.
Importante:
- Alertas acionados pelo Hypervisor são buscados e exibidos no Director. No entanto, as alterações no ciclo de vida/estado dos alertas do Hypervisor não são refletidas no Director.
- Alertas que estão saudáveis, descartados ou desabilitados no console do Hypervisor continuam a aparecer no Director e devem ser descartados explicitamente.
- Alertas que são descartados no Director não são descartados automaticamente no console do Hypervisor.
Uma nova categoria de Alerta chamada Integridade do Hypervisor foi adicionada para permitir a filtragem apenas dos alertas do hypervisor. Esses alertas são exibidos assim que os limites são atingidos ou excedidos. Os alertas do Hypervisor podem ser:
- Crítico — limite crítico da política de alarme do hypervisor atingido ou excedido
- Aviso — limite de aviso da política de alarme do hypervisor atingido ou excedido
- Descartado — alerta não mais exibido como um alerta ativo
Este recurso requer o Delivery Controller versão 7 1811 ou posterior. Se você estiver usando uma versão mais antiga do Director com sites 7 1811 ou posterior, apenas a contagem de alertas do hypervisor será exibida. Para visualizar os alertas, você deve atualizar o Director.
Configurar a integração de alertas do SCOM
A integração do SCOM com o Director permite visualizar informações de alerta do SCOM no Painel e em outras visualizações de alto nível no Director.
Os alertas do SCOM são exibidos na tela junto com os alertas do Citrix. Você pode acessar e detalhar os alertas do SCOM na guia SCOM na barra lateral.
Você pode visualizar alertas históricos de até um mês, classificar, filtrar e exportar as informações filtradas para os formatos de relatório CSV, Excel e PDF. Para obter mais informações, consulte Exportar relatórios.
A integração do SCOM usa o PowerShell remoto 3.0 ou posterior para consultar dados do SCOM Management Server e mantém uma conexão de runspace persistente na sessão do Director do usuário. O Director e o servidor SCOM devem ter a mesma versão do PowerShell.
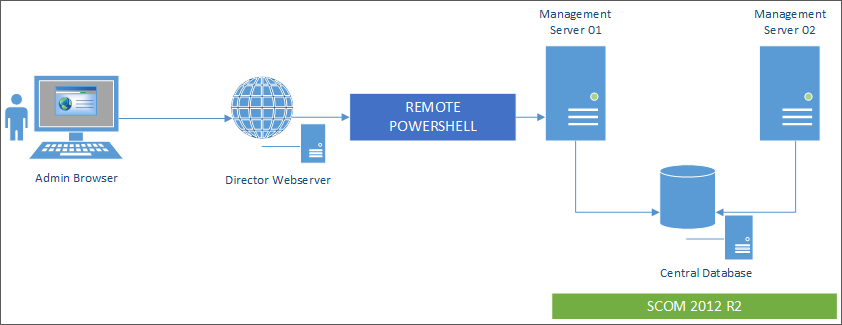
Os requisitos para a integração do SCOM são:
- Windows Server 2012 R2
- System Center 2012 R2 Operations Manager
- PowerShell 3.0 ou posterior (a versão do PowerShell no Director e no servidor SCOM deve ser a mesma)
- CPU Quad Core com 16 GB de RAM (recomendado)
- Um Management Server primário para SCOM deve ser configurado no arquivo web.config do Director. Você pode fazer isso usando a ferramenta DirectorConfig.
A Citrix recomenda que a conta de administrador do Director seja configurada como uma função de Operador SCOM para que as informações completas de alerta possam ser recuperadas no Director. Se isso não for possível, uma conta de administrador SCOM pode ser configurada no arquivo web.config usando a ferramenta DirectorConfig.
A Citrix recomenda ainda que você não configure mais de 10 administradores do Director por SCOM Management Server para garantir o desempenho ideal.
No servidor Director:
-
Digite Enable-PSRemoting para habilitar o PowerShell remoting.
-
Adicione o SCOM Management Server à lista TrustedHosts. Abra um prompt do PowerShell e execute o(s) seguinte(s) comando(s):
-
Obtenha a lista atual de TrustedHosts
Get-Item WSMAN:\localhost\Client\TrustedHosts <!--NeedCopy--> -
Adicione o FQDN do SCOM Management Server à lista de TrustedHosts. <Old Values> representa o conjunto existente de entradas retornadas do cmdlet Get-Item.
Set-Item WSMAN:\localhost\Client\TrustedHosts -Value "\<FQDN SCOM Management Server\>,\<Old Values\>" <!--NeedCopy-->
-
-
Configure o SCOM usando a ferramenta DirectorConfig.
C:\inetpub\wwwroot\Director\tools\DirectorConfig.exe /configscom <!--NeedCopy-->
No servidor SCOM Management:
-
Atribua administradores do Director a uma função de administrador SCOM.
-
Abra o console do SCOM Management e vá para Administração > Segurança > Funções de Usuário.
-
Em Funções de Usuário, você pode criar uma nova Função de Usuário ou modificar uma existente. Existem quatro categorias de funções de operador SCOM que definem a natureza do acesso aos dados do SCOM. Por exemplo, uma função Somente Leitura não vê o painel de Administração e não pode descobrir ou gerenciar regras, máquinas ou contas. Uma função de Operador é uma função de administrador completa.
Nota:
As seguintes operações não estão disponíveis se o administrador do Director for atribuído a uma função que não seja de operador:
- Se houver vários servidores de gerenciamento configurados e o servidor de gerenciamento primário não estiver disponível, o administrador do Director não poderá se conectar ao servidor de gerenciamento secundário. O servidor de gerenciamento primário é o servidor configurado no arquivo web.config do Director, ou seja, o mesmo servidor especificado com a ferramenta DirectorConfig na etapa 3 acima. Os servidores de gerenciamento secundários são servidores de gerenciamento pares do servidor primário.
- Ao filtrar alertas, o administrador do Director não pode pesquisar a origem do alerta. Isso requer uma permissão de nível de operador.
-
Para modificar qualquer Função de Usuário, clique com o botão direito do mouse na função e, em seguida, clique em “Propriedades”.
-
Na caixa de diálogo Propriedades da Função de Usuário, você pode adicionar ou remover administradores do Director da função de usuário especificada.
-
-
Adicione administradores do Director ao grupo Remote Management Users no servidor SCOM Management. Isso permite que os administradores do Director estabeleçam uma conexão remota do PowerShell.
-
Digite Enable-PSRemoting para habilitar o PowerShell remoting.
-
Defina os limites das propriedades do WS-Management:
-
Modifique MaxConcurrentUsers:
Na CLI:
winrm set winrm/config/winrs @{MaxConcurrentUsers = "20"} <!--NeedCopy-->No PS:
Set-Item WSMan:\localhost\Shell\MaxConcurrentUsers 20 <!--NeedCopy--> -
Modifique MaxShellsPerUser:
Na CLI:
winrm set winrm/config/winrs @{MaxShellsPerUser="20"} <!--NeedCopy-->No PS:
Set-Item WSMan:\localhost\Shell\MaxShellsPerUser 20 <!--NeedCopy-->-
Modifique MaxMemoryPerShellMB:
Na CLI:
winrm set winrm/config/winrs @{MaxMemoryPerShellMB="1024"} <!--NeedCopy-->No PS:
Set-Item WSMan:\localhost\Shell\MaxMemoryPerShellMB 1024 <!--NeedCopy--> -
-
Para garantir que a integração do SCOM funcione em ambientes de domínio misto, defina a seguinte entrada de registro.
Caminho: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System
Chave: LocalAccountTokenFilterPolicy
Tipo: DWord
Valor: 1
Cuidado: A edição incorreta do registro pode causar problemas sérios que podem exigir a reinstalação do seu sistema operacional. A Citrix não pode garantir que os problemas resultantes do uso incorreto do Editor do Registro possam ser resolvidos. Use o Editor do Registro por sua conta e risco. Certifique-se de fazer backup do registro antes de editá-lo.
Uma vez configurada a integração do SCOM, você pode ver a mensagem “Não é possível obter os alertas SCOM mais recentes. Visualize os logs de eventos do servidor Director para obter mais informações”. Os logs de eventos do servidor ajudam a identificar e corrigir o problema. As causas podem incluir:
- Perda de conectividade de rede na máquina Director ou SCOM.
- O serviço SCOM não está disponível ou está muito ocupado para responder.
- Autorização falha devido a uma alteração nas permissões para o usuário configurado.
- Um erro no Director ao processar os dados do SCOM.
- Incompatibilidade de versão do PowerShell entre o Director e o servidor SCOM.