警报
Performance Analytics 会生成警报,以帮助管理员主动监控环境。当影响用户体验的因素恶化时,会生成警报。
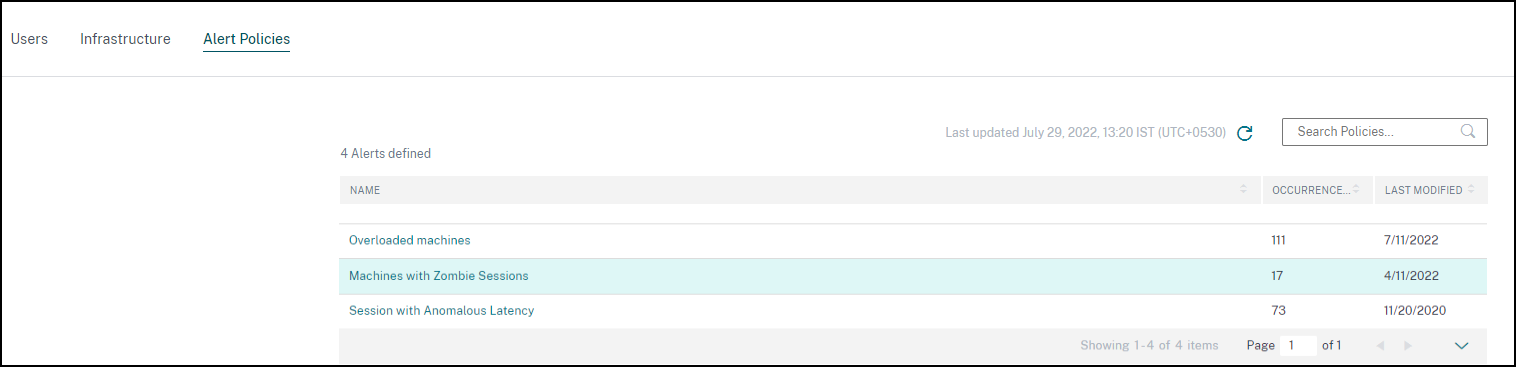
可用策略列在警报策略选项卡中。警报默认启用,可以使用状态切换按钮禁用。可以为没有 Citrix Cloud 帐户管理员访问权限的收件人启用利益相关者的警报电子邮件通知。单击警报名称可编辑邮件收件人列表。有关详细信息,请参阅电子邮件通讯组列表文章。
您必须在 Citrix Cloud 的帐户设置菜单中为所有收件人启用接收电子邮件通知,才能收到警报邮件。有关详细信息,请参阅通知文章。
Webhook 对警报通知的支持
您可以将 Performance Analytics 中的警报通知发布到首选的 Webhook 侦听器,例如 Slack、JIRA。这有助于企业客户自动化从事件检测到关闭的流程,从而轻松地根据 Performance Analytics 警报通知驱动工作流。
有关创建 Webhook 配置文件的信息,请参阅创建 Webhook 配置文件。
要配置基于 Webhook 的警报通知:
-
转到警报策略选项卡。
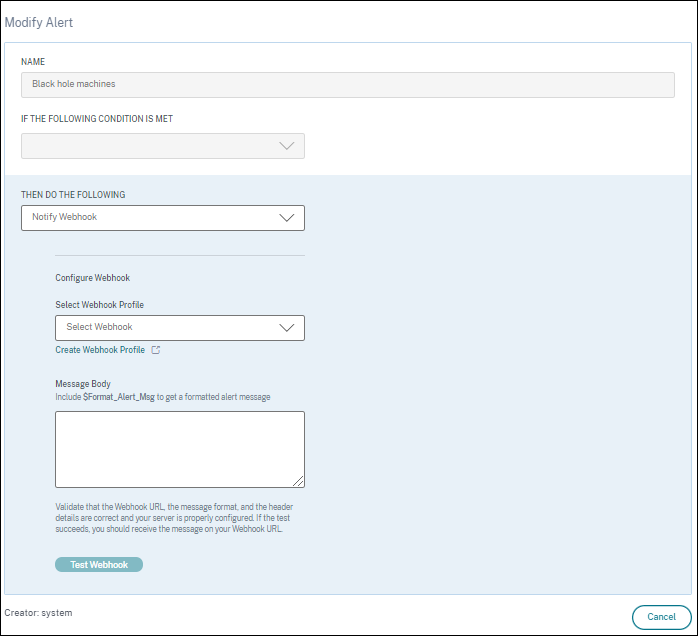
- 单击要使用 Webhook 配置的策略。
- 修改警报页面打开。在然后执行以下操作下拉列表中,根据需要选择通知 Webhook 或电子邮件或通知 Webhook。
- 如果已创建 Webhook 配置文件,请从选择 Webhook 配置文件下拉列表中选择正确的 Webhook。
-
在消息正文文本框中,包含
$Format_Alert_Msg字符串以获取带有存储在后端中的模板化字符串的常规警报消息。例如,要将警报消息发送到 Slack,可以使用以下格式:{"text":"$Format_Alert_Msg" }。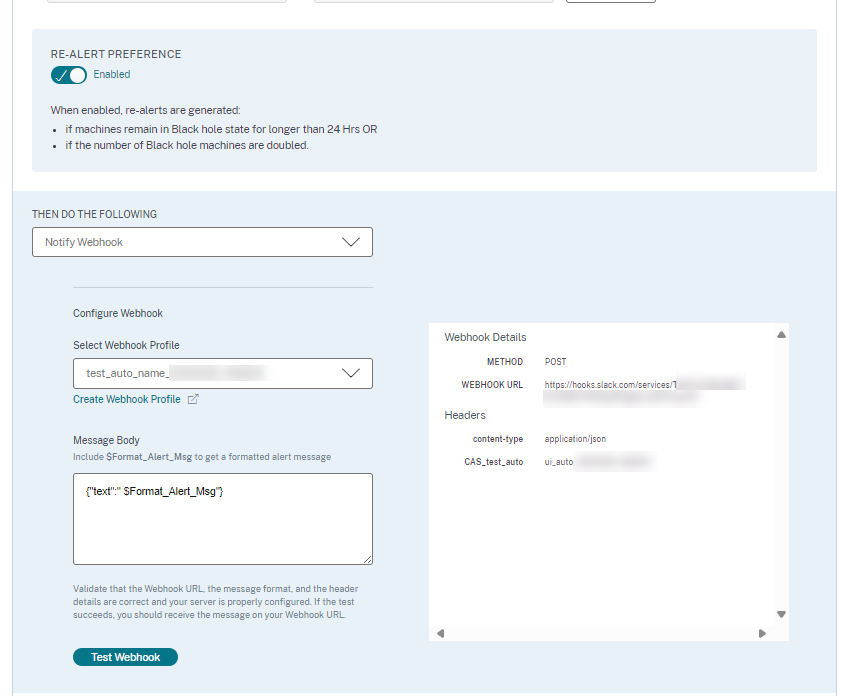
警报邮件中的 CSV 附件
黑洞计算机、过载计算机和僵尸会话警报电子邮件包含 CSV 附件,其中包含有关受影响计算机和会话的信息。 附件包含以下数据:
- 计算机名称
- 站点 ID
- 目录名称
- 交付组名称
- 故障计数(根据适用情况,失败的计算机或会话数)。
警报邮件中的 CSV 附件有助于识别故障计算机和会话,而无需登录 Citrix Analytics for Performance。这有助于建立自动化管道,以创建工单并将其转发给负责快速解决问题的利益相关者。
从接收警报中排除交付组
您现在可以指定要从接收警报通知中排除的交付组。您可以从警报流程中删除未使用的交付组或为测试目的创建的交付组。排除交付组有助于减少警报疲劳并提高警报的相关性。
自定义警报参数
警报策略预置了默认参数值。您可以修改警报参数,使其更符合您的环境。
单击警报策略名称以打开修改警报窗口。修改列出的参数值以适应您的环境。后续警报通知将根据自定义条件生成。
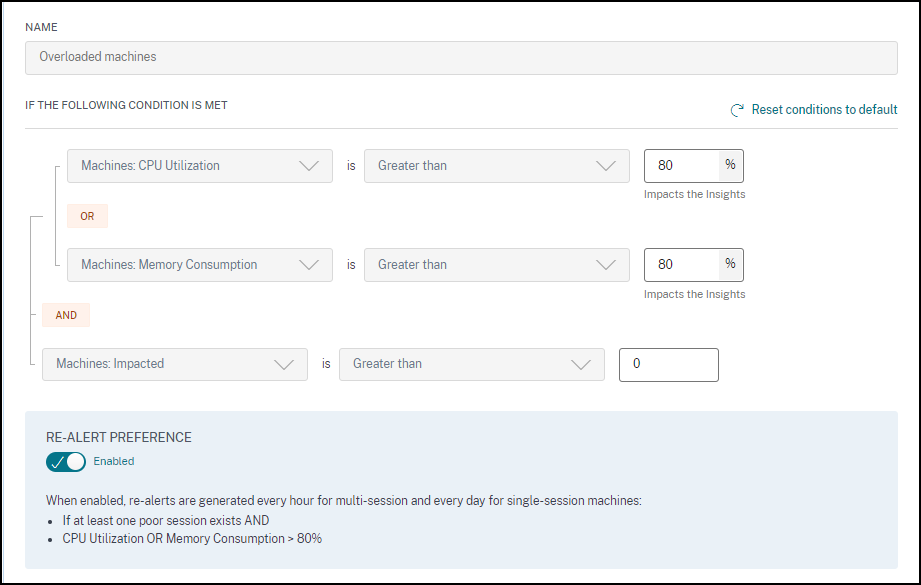
注意: 更新警报参数也会更改 UX 仪表板上相应洞察的计算。
在支持重新警报的警报中,您还可以控制重新警报首选项。如果重新警报首选项设置为已启用,并且重新警报首选项中指定的条件持续存在,则会重新发送警报通知。
自定义警报与您的环境更相关,它们有助于轻松识别异常,并且对于主动监控更可靠。
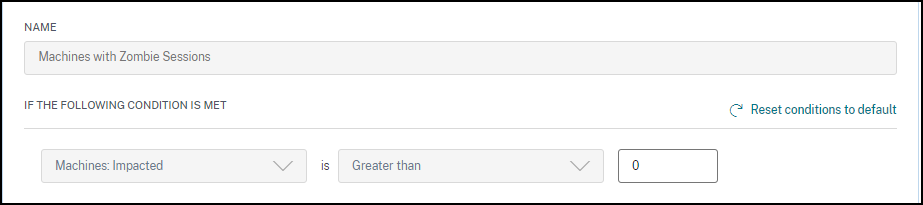
僵尸会话计算机警报
当在 15 分钟间隔内环境中检测到具有僵尸会话的新计算机时,会生成僵尸会话计算机警报邮件。
您可以自定义僵尸会话计算机警报的警报条件。
一封电子邮件警报会发送给管理员,其中包含具有僵尸会话的计算机数量以及因僵尸会话导致的会话失败的详细信息。邮件中的数字是最近 15 分钟间隔的数据。
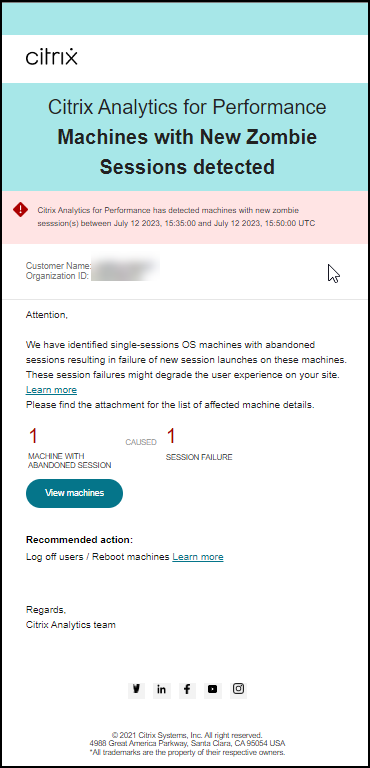
单击邮件中的查看计算机,可在僵尸会话计算机的自助服务视图中查看具有已放弃会话的单会话计算机。该视图反映了邮件中所示的 15 分钟间隔,请使用时间导航器选择更大的时间窗口。
仅当同一已放弃会话在同一计算机上从首次检测起持续超过 24 小时时,才会对同一计算机进行重新警报。此警报的重新警报首选项不能设置为禁用。
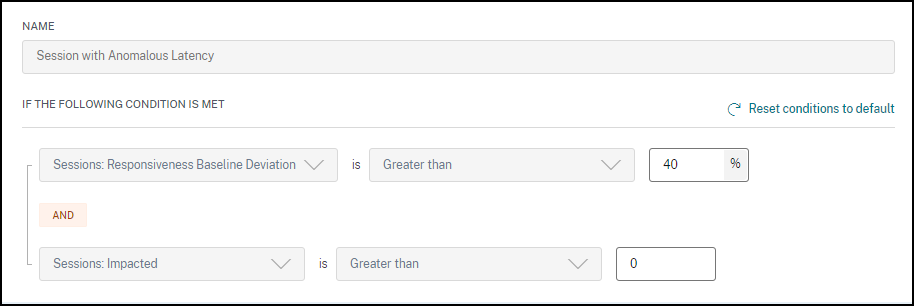
异常延迟会话警报
异常延迟是导致会话体验不佳的主要原因。当会话延迟值出现显著偏差时,异常延迟警报会帮助管理员。主动警报有助于管理员识别会话响应能力差的特定用户。
您可以自定义异常延迟会话警报的警报条件。
更新参数会更改异常响应会话的基线洞察的计算。
此警报显示会话延迟读数偏离用户 30 天基线值的会话和用户数量。用户特定的基线是使用过去 30 天测量的 P95 ICARTT 值计算的。
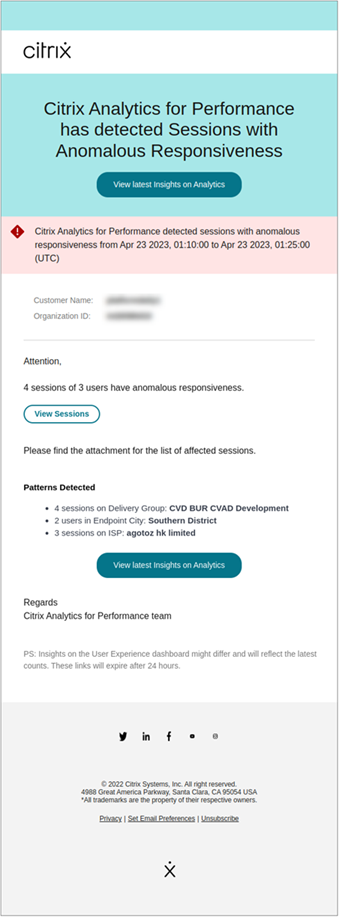
警报邮件显示在指定时间段内面临异常响应的会话和用户数量。单击查看会话可在会话自助服务页面中查看具有异常响应的会话。
检测到的模式部分显示了根据以下标准在具有异常响应的会话中发现的前三个模式:
- 每个交付组中具有异常响应的会话数
- 每个端点城市中具有异常响应的用户数
- 每个 ISP 中具有异常响应的会话数
在 Analytics 上查看最新洞察链接会转到用户体验仪表板,其中显示洞察面板中的最新统计信息。分析特定会话的位置、ICARTT、ISP、带宽和延迟指标,以找出问题的根本原因。有关基于会话的自助服务视图中可用指标的更多信息,请参阅会话自助服务搜索。
过载计算机警报
经历持续 CPU 峰值或高内存使用率(或两者兼有)并持续 5 分钟或更长时间,导致在选定时间间隔内用户体验不佳的计算机被视为过载。
您可以自定义过载计算机警报的警报条件和重新警报首选项。
当在 15 分钟间隔内环境中检测到过载计算机时,会向管理员发送过载计算机警报邮件。
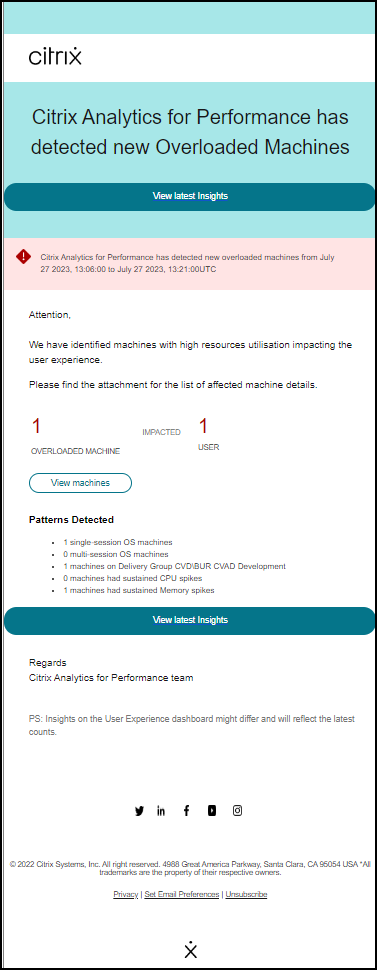
如果计算机仍处于过载状态,则会生成重新警报邮件,
- 对于单会话计算机,每 24 小时一次,
- 对于多会话计算机,如果计算机具有会话分数不佳的新会话,则在第一天最多三次,并在 24 小时后一次。
警报邮件显示导致用户体验不佳的过载计算机数量以及在选定持续时间内受影响的用户数量。
单击查看计算机可在过载计算机的计算机自助服务页面中查看过载计算机。
检测到的模式部分显示了根据以下标准在过载计算机中发现的前三个模式:
- 每个交付组中过载计算机的数量
- 运行单会话或多会话操作系统的过载计算机数量
- 具有持续内存或 CPU 峰值的过载计算机数量
查看最新洞察链接会转到用户体验仪表板,其中显示洞察面板中的最新统计信息。
更新参数会更改过载计算机的诊断洞察的计算。
有关详细信息,请参阅洞察文章。
黑洞计算机警报
Citrix Analytics for Performance 每 15 分钟扫描一次黑洞计算机,并发出警报,以使管理员能够主动缓解用户因黑洞计算机而面临的会话失败。未能连续处理四次或更多会话请求的计算机被称为黑洞计算机。通过黑洞故障警报,管理员无需登录 Performance Analytics 即可了解因黑洞计算机而发生的会话失败。
您可以自定义黑洞计算机警报的警报条件和重新警报首选项。
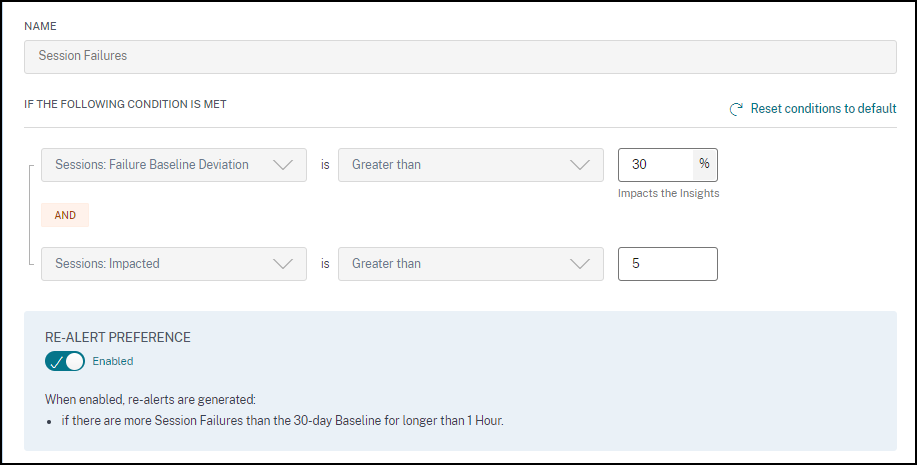
计算机的详细信息以及由其导致的会话失败将通过警报邮件发送给管理员。必须启用黑洞计算机警报策略才能接收这些邮件。
单击“查看计算机”链接会将您带到计算机自助服务视图,其中显示 15 分钟间隔内的黑洞计算机列表。此外,时间线视图显示过去 24 小时内识别出的黑洞计算机。 如果同一黑洞计算机导致的会话失败数量在 24 小时内翻倍,并且重新警报首选项设置为已启用,则会重新向管理员发出警报。
查看最新洞察链接会转到用户体验仪表板,其中显示洞察面板中的最新统计信息。
检测到的模式部分显示了根据以下标准在黑洞计算机中发现的前三个模式:
- 每个交付组中黑洞计算机的数量
- 运行单会话或多会话操作系统的黑洞计算机数量
更新参数会更改黑洞计算机的诊断洞察的计算。有关详细信息,请参阅洞察文章。
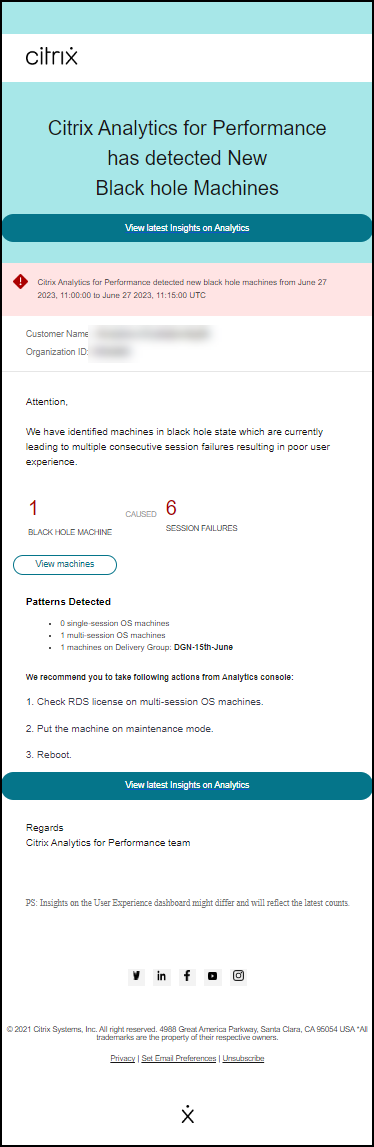
会话失败警报
当未能启动的会话数量超过 30 天基线值 30% 或更多,并且总会话数量的 5% 以上失败时,会生成会话失败警报。基线值是根据过去 30 天同一时间段内测量的会话失败计数的 P80 值计算的。
您可以自定义会话失败警报的警报条件和重新警报首选项。
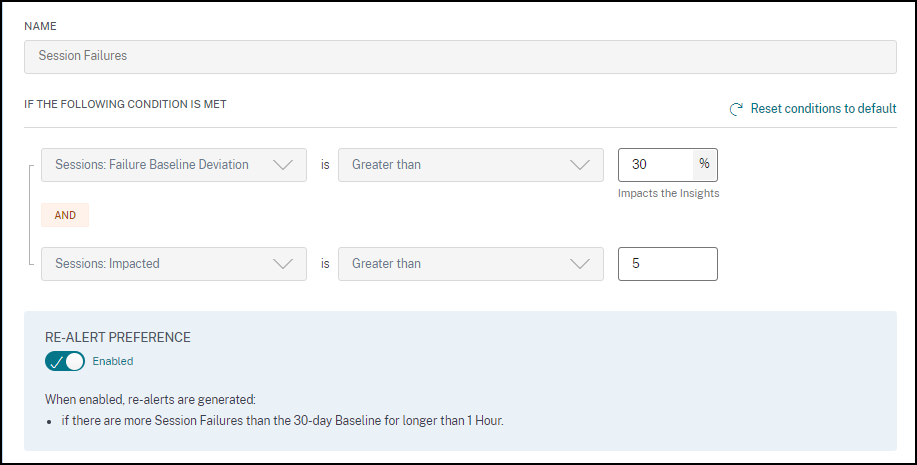
会话失败警报通知会发送给所有已配置的管理员。
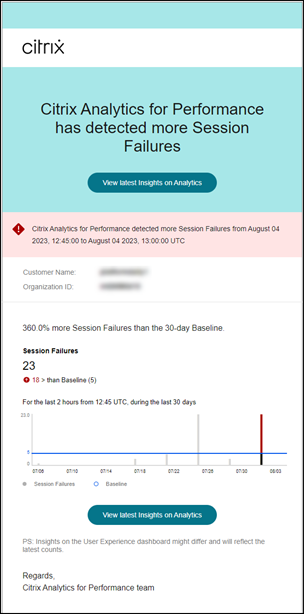
会话失败警报邮件显示以下信息:
- 当前会话失败计数与基线值相比的百分比变化
- 当前会话失败数量
- 相对于基线值的会话失败数量增加
- 显示基线值和过去 30 天会话失败计数趋势的图表。
查看最新洞察链接会转到用户体验仪表板,其中显示基线洞察面板中的最新统计信息。
更新参数会更改会话失败的基线洞察的计算。有关详细信息,请参阅洞察文章。
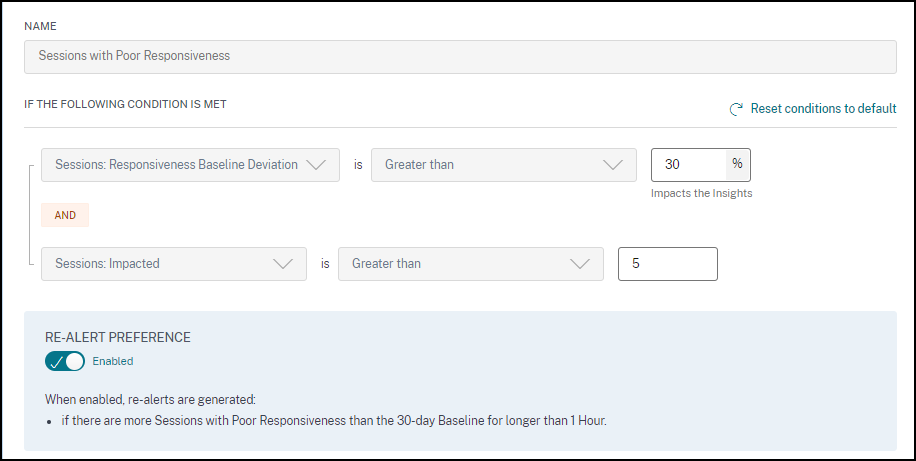
响应能力差的会话警报
当响应能力差的会话数量比 30 天基线值增加 30% 或更多,并且此增加影响超过 5% 的会话时,会生成响应能力差的会话警报。基线值是根据过去 30 天同一时间段内测量的响应能力差的会话数量的 P80 值计算的。
您可以自定义响应能力差的会话警报的警报条件和重新警报首选项。
响应能力差的会话警报通知会发送给已配置的管理员。
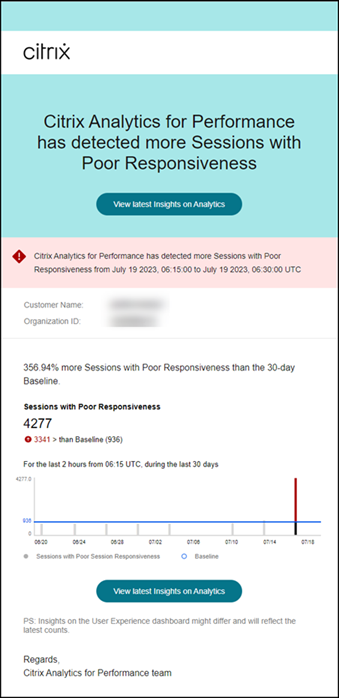
警报邮件包含以下信息:
- 当前响应能力差的会话数量值与基线值相比的百分比变化
- 当前响应能力差的会话数量
- 相对于基线值的响应能力差的会话的增加或减少
- 显示基线值和过去 30 天响应能力差的会话数量趋势的图表。
查看最新洞察链接会转到用户体验仪表板,其中显示洞察面板中的最新统计信息。
更新参数会更改响应能力差的会话的基线洞察的计算。有关详细信息,请参阅洞察文章。
登录持续时间差的会话警报
当登录持续时间差的会话数量比 30 天基线值增加 30% 或更多,并且此增加影响超过 5% 的会话时,会生成登录持续时间差的会话警报。基线值是根据过去 30 天同一时间段内测量的登录持续时间差的会话数量的 P80 值计算的。
您可以自定义登录持续时间差的会话警报的警报条件和重新警报首选项。
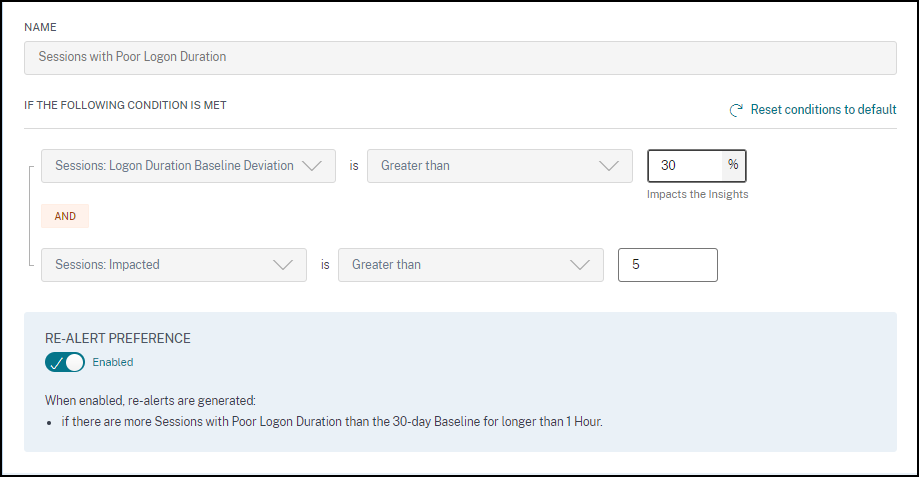
登录持续时间差的会话警报通知会发送给已配置的管理员。
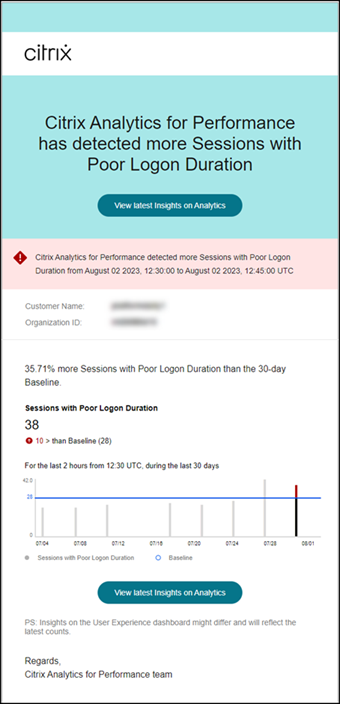
登录持续时间差的会话警报邮件显示以下信息:
- 当前登录持续时间差的会话数量值与基线值相比的百分比变化
- 当前登录持续时间差的会话数量
- 相对于基线值的登录持续时间差的会话的增加或减少
- 显示基线值和过去 30 天登录持续时间差的会话数量趋势的图表
查看最新洞察链接会转到用户体验仪表板,其中显示基线洞察面板中的最新统计信息。
有关详细信息,请参阅洞察文章。
异常会话断开警报
当会话断开连接计数比 30 天基线值增加 30% 或更多,并且此增加影响超过 5% 的会话时,会生成异常会话断开连接警报。基线值是根据过去 30 天同一时间段内测量的会话断开连接数量的 P80 值计算的。
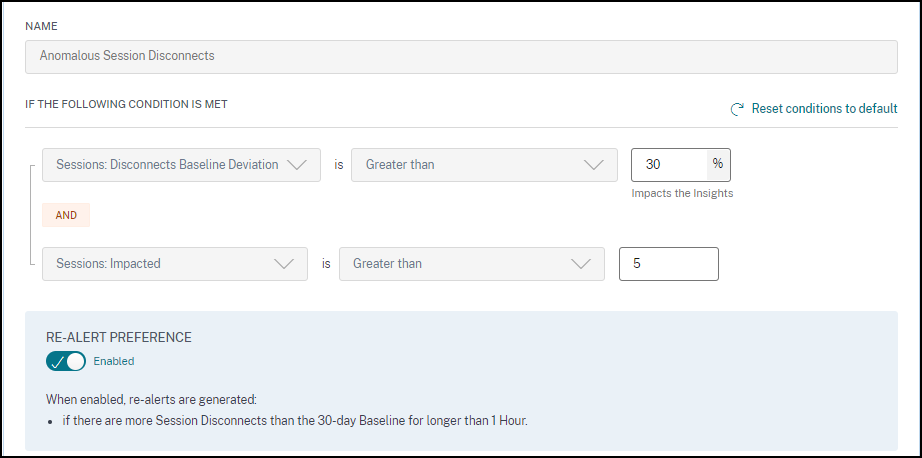
您可以自定义异常会话断开连接警报的警报条件和重新警报首选项。
异常会话断开连接警报通知会发送给已配置的管理员。
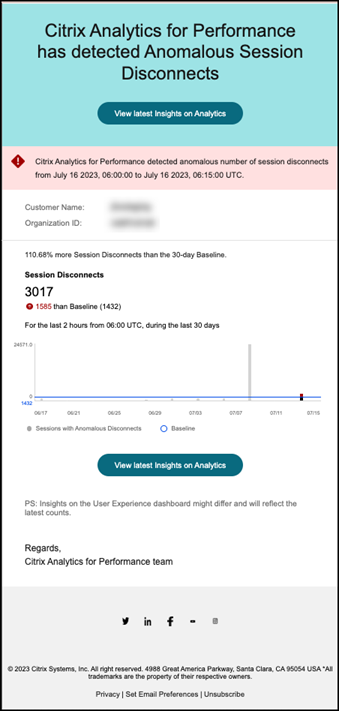
异常会话断开连接警报邮件显示以下信息:
- 当前会话断开连接计数与基线值相比的百分比变化
- 当前会话断开连接数量
- 相对于基线值的会话断开连接增加
- 显示基线值和过去 30 天会话断开连接数量趋势的图表。
查看最新洞察链接会转到用户体验仪表板,其中显示基线洞察面板中的最新统计信息。
更新参数会更改异常会话断开连接的基线洞察的计算。有关详细信息,请参阅洞察文章。