-
-
带有 Citrix Analytics 附加应用程序的 Splunk 体系结构
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Splunk 架构与 Citrix Analytics 附加应用程序
Splunk 遵循包含以下三个层的架构:
- 收集
- 索引
- 搜索
Splunk 支持广泛的数据收集机制,有助于轻松将数据引入 Splunk,以便对其进行索引并使其可用于搜索。此层即为您的重型转发器或通用转发器。
您必须将附加应用程序安装在重型转发器层,而不是通用转发器层。因为,除了少数结构化数据(例如 json、csv、tsv)例外情况外,通用转发器不会将日志源解析为事件,因此它无法执行任何需要理解日志格式的操作。
它还附带一个精简版 Python,这使其与任何需要完整 Splunk 堆栈才能运行的模块化输入应用程序不兼容。重型转发器即为您的收集层。
通用转发器和重型转发器之间的主要区别在于,重型转发器包含完整的解析管道,执行与索引器相同的功能,而无需实际在磁盘上写入和索引事件。这使重型转发器能够理解并根据事件数据对单个事件执行操作,例如数据屏蔽、过滤和路由。由于附加应用程序具有完整的 Splunk Enterprise 安装,它可以托管需要完整 Python 堆栈才能进行正确数据收集的模块化输入,或者充当 Splunk HTTP 事件收集器 (HEC) 的端点。
数据收集后,它会被索引或处理并以可搜索的方式存储。
客户探索其数据的主要方式是通过搜索。搜索可以保存为报告,并用于为仪表板面板提供支持。搜索是从数据中提取信息。
通常,Splunk 附加应用程序部署在收集层(Splunk Enterprise 级别),而我们的仪表板应用程序部署在搜索层(Splunk Cloud 级别)。在简单的本地部署中,您可以在单个 Splunk 主机上拥有所有这三个层(称为单服务器部署)。
收集层是使用 Splunk 附加应用程序的更好方式。有两种安装附加应用程序的方式。您可以将其安装在客户环境下的收集层,或者将其安装在 Splunk Cloud 实例下的输入数据管理器中。
请参阅下图,了解 Splunk 部署架构与我们的附加应用程序:
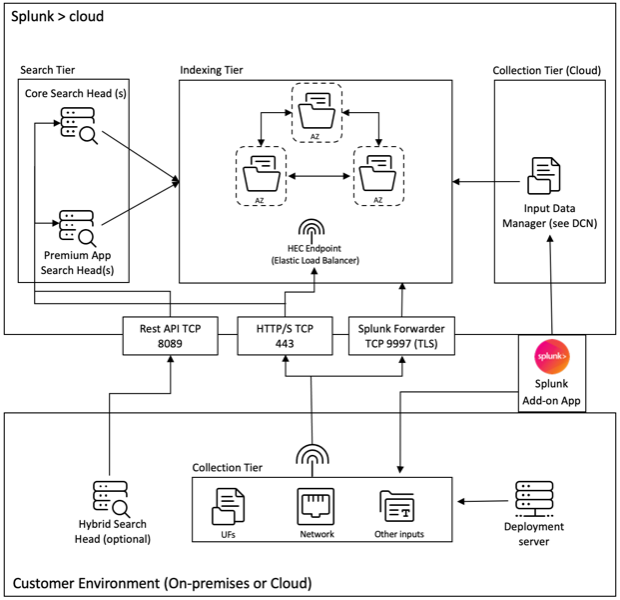
上述图中所示的输入数据管理器 (IDM) 是 Splunk Cloud 管理的数据收集节点 (DCN) 实现,仅支持脚本化和模块化输入。对于超出此范围的数据收集需求,您可以使用 Splunk 重型转发器在您的环境中部署和管理 DCN。
Splunk 允许从各种来源收集、索引和搜索数据。一种数据收集方式是通过 API,这允许 Splunk 访问存储在其他系统或应用程序中的数据。这些 API 可以包括 REST、Web 服务、JMS 和/或 JDBC 作为查询机制。Splunk 和任何第三方开发人员提供一系列应用程序,通过 Splunk 模块化输入框架实现 API 交互。这些应用程序通常需要完整的 Splunk Enterprise 软件安装才能正常运行。
为了方便通过 API 收集数据,通常将重型转发器部署为 DCN。重型转发器比通用转发器更强大的代理,因为它们包含完整的解析管道,并且能够理解并对单个事件执行操作。这使它们能够通过 API 收集数据并在将其转发到 Splunk 实例进行索引之前对其进行处理。
要了解有关 Splunk Cloud 部署高级架构的更多信息,请参阅 Splunk 验证架构。
共享
共享
在本文中
This Preview product documentation is Citrix Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Citrix Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Citrix product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.