Splunk-Architektur mit der Citrix Analytics Add-on-Anwendung
Splunk folgt einer Architektur, die die folgenden drei Ebenen umfasst:
- Erfassung
- Indizierung
- Suche
Splunk unterstützt eine Vielzahl von Datenerfassungsmechanismen, die das einfache Einlesen von Daten in Splunk ermöglichen, sodass diese indiziert und für die Suche verfügbar gemacht werden können. Diese Ebene ist nichts anderes als Ihr Heavy Forwarder oder Universal Forwarder.
Sie müssen die Add-on-Anwendung auf der Heavy-Forwarder-Ebene anstelle der Universal-Forwarder-Ebene installieren. Denn mit wenigen Ausnahmen für gut strukturierte Daten (wie z. B. JSON, CSV, TSV) parst der Universal Forwarder Protokollquellen nicht in Ereignisse, sodass er keine Aktionen ausführen kann, die ein Verständnis des Protokollformats erfordern.
Er wird auch mit einer abgespeckten Version von Python ausgeliefert, was ihn inkompatibel mit modularen Eingabeanwendungen macht, die einen vollständigen Splunk-Stack zum Funktionieren benötigen. Der Heavy Forwarder ist nichts anderes als Ihre Erfassungsebene.
Der Hauptunterschied zwischen einem Universal Forwarder und einem Heavy Forwarder besteht darin, dass der Heavy Forwarder die vollständige Parsing-Pipeline enthält und die gleichen Funktionen wie ein Indexer ausführt, ohne tatsächlich Ereignisse auf die Festplatte zu schreiben und zu indizieren. Dies ermöglicht es dem Heavy Forwarder, einzelne Ereignisse zu verstehen und darauf zu reagieren, wie z. B. das Maskieren von Daten, das Filtern und das Weiterleiten basierend auf Ereignisdaten. Da die Add-on-Anwendung eine vollständige Splunk Enterprise-Installation besitzt, kann sie modulare Eingaben hosten, die einen vollständigen Python-Stack für die ordnungsgemäße Datenerfassung erfordern, oder als Endpunkt für den Splunk HTTP Event Collector (HEC) fungieren.
Sobald die Daten erfasst wurden, werden sie indiziert oder verarbeitet und so gespeichert, dass sie durchsuchbar sind.
Die primäre Methode für Kunden, ihre Daten zu erkunden, ist die Suche. Eine Suche kann als Bericht gespeichert und zur Bereitstellung von Dashboard-Panels verwendet werden. Suchen extrahieren Informationen aus Ihren Daten.
Im Allgemeinen wird die Splunk Add-on-Anwendung in der Erfassungsebene (auf Splunk Enterprise-Ebene) bereitgestellt, während unsere Dashboarding-Anwendung auf der Suchebene (auf Splunk Cloud-Ebene) bereitgestellt wird. In einem einfachen lokalen Setup können Sie alle drei Ebenen auf einem einzigen Splunk-Host haben (bekannt als Einzelserver-Bereitstellung).
Die Erfassungsebene ist eine wesentlich bessere Möglichkeit, die Add-on-Anwendung für Splunk zu nutzen. Es gibt zwei Möglichkeiten, die Add-on-Anwendung zu installieren. Sie können sie entweder auf der Erfassungsebene in der Kundenumgebung installieren oder im Inputs Data Manager unter der Splunk Cloud-Instanz.
Beachten Sie das folgende Diagramm, um die Splunk-Bereitstellungsarchitektur mit unserer Add-on-Anwendung zu verstehen:
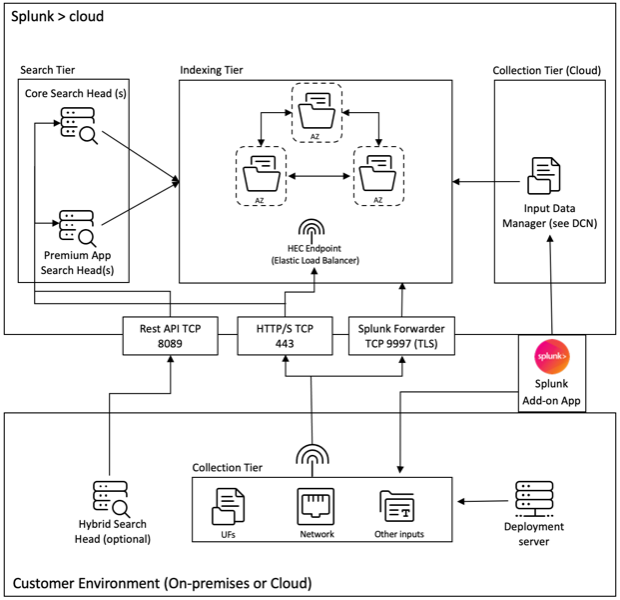
Der im oben genannten Diagramm gezeigte Inputs Data Manager (IDM) ist die von Splunk Cloud verwaltete Implementierung eines Data Collection Node (DCN), der nur skriptbasierte und modulare Eingaben unterstützt. Für Datenerfassungsanforderungen, die darüber hinausgehen, können Sie einen DCN in Ihrer Umgebung mithilfe eines Splunk Heavy Forwarders bereitstellen und verwalten.
Splunk ermöglicht das Sammeln, Indizieren und Durchsuchen von Daten aus verschiedenen Quellen. Eine Möglichkeit, Daten zu sammeln, ist über APIs, die Splunk den Zugriff auf Daten ermöglichen, die in anderen Systemen oder Anwendungen gespeichert sind. Diese APIs können REST, Webdienste, JMS und/oder JDBC als Abfragemechanismus umfassen. Splunk und Drittentwickler bieten eine Reihe von Anwendungen an, die API-Interaktionen über das modulare Eingabe-Framework von Splunk ermöglichen. Diese Anwendungen erfordern typischerweise eine vollständige Splunk Enterprise-Softwareinstallation, um ordnungsgemäß zu funktionieren.
Um die Datenerfassung über APIs zu erleichtern, ist es üblich, einen Heavy Forwarder als DCN bereitzustellen. Heavy Forwarder sind leistungsfähigere Agenten als Universal Forwarder, da sie die vollständige Parsing-Pipeline enthalten und einzelne Ereignisse verstehen und darauf reagieren können. Dies ermöglicht es ihnen, Daten über APIs zu sammeln und zu verarbeiten, bevor sie an eine Splunk-Instanz zur Indizierung weitergeleitet werden.
Um mehr über die übergeordnete Architektur einer Splunk Cloud-Bereitstellung zu erfahren, lesen Sie Splunk Validated Architectures.