インサイト
インサイトパネルは、環境におけるセッション障害の根本原因に関する情報を提供します。これらのインサイトを使用して特定のメトリックを深く掘り下げることで、セッション障害のトラブルシューティングと解決を迅速に行うことができます。障害インサイトは、特に管理者がセッションの可用性を向上させるのに役立ちます。セッションの可用性は、ユーザーエクスペリエンスを決定する重要な要素です。 これらのインサイトは、ユーザーエクスペリエンスのプロアクティブな監視を支援するように設計されています。そのため、ダッシュボードで1か月または1週間の期間が選択されていても、インサイトは最大1日間の期間で表示されます。
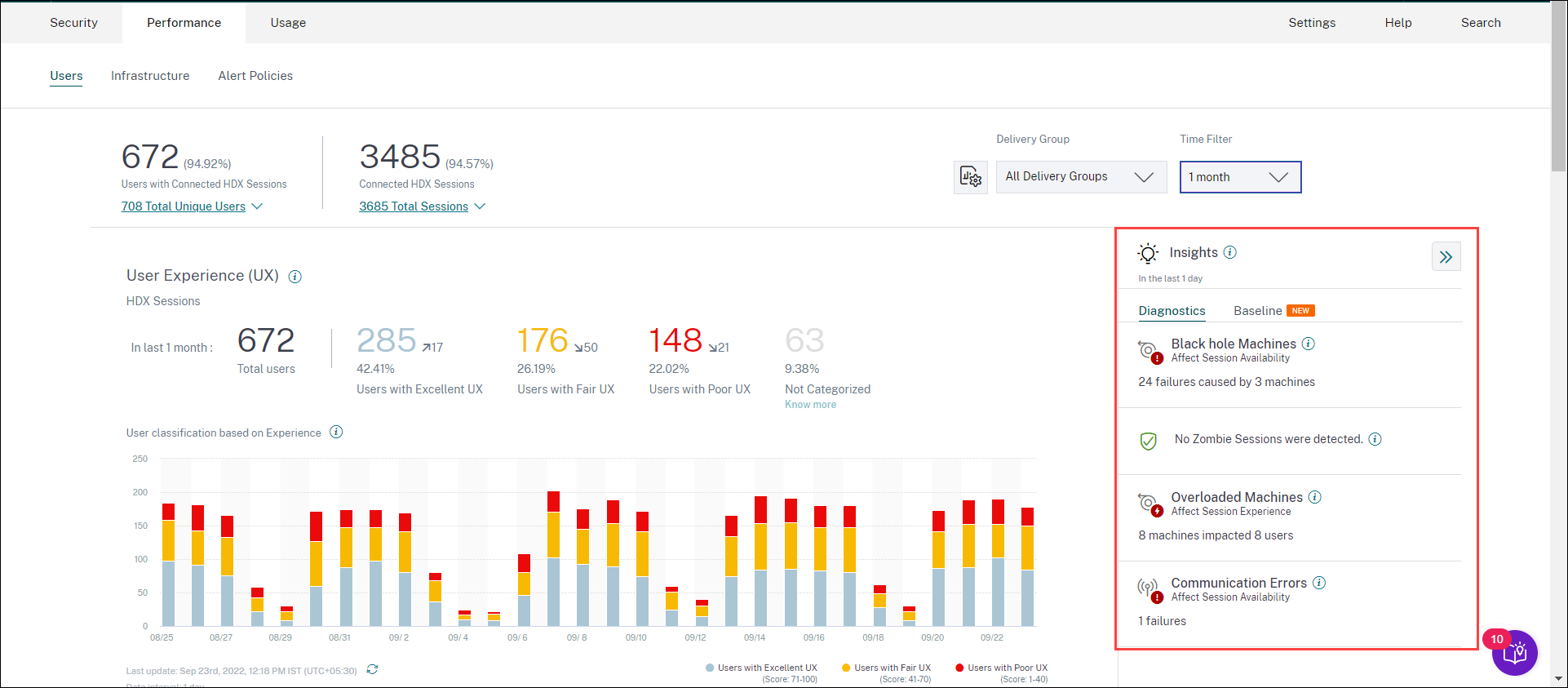
概要ペインからインサイトをクリックすると、インサイトの詳細とセルフサービスビューへのドリルダウンオプションが表示されたインサイトペインが表示されます。
インサイトは2つのカテゴリで表示されます。
-
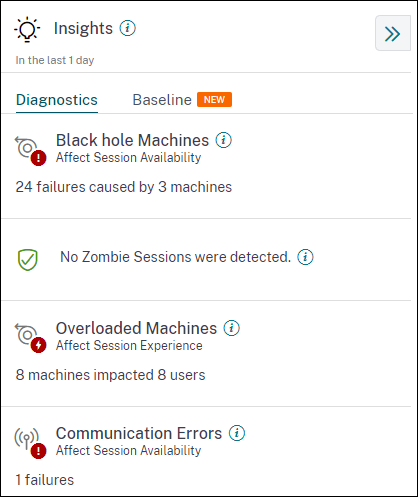
診断インサイト: 診断サブペインには、サイトで発生した障害に関する重要なインサイトが表示されます。このサブペインでは、ブラックホールマシン、ゾンビセッション、過負荷マシン、および通信エラー診断インサイトが利用可能です。 各インサイトを展開すると、失敗したセッションまたはそれらをホストしているマシンへのリンクが表示されます。これにより、失敗したマシンまたはセッションを含むセルフサービスビューに移動します。特定のマシン、セッション、またはコネクタをクリックしてタイムラインの詳細と詳細なメトリックを表示すると、ここからさらにドリルダウンできます。
サイト、デリバリーグループ、シングルまたはマルチOSセッションマシンに関して検出された上位の障害パターンが表示されます。これらのパターンは、特定の一群のユーザーが問題に遭遇しているかどうかを特定するのに役立ちます。分散したコホートのためにシステムがパターンを強調表示できない場合は、自己分析のためにドリルダウンすることをお勧めします。また、問題のトラブルシューティングと解決のために推奨されるアクションも表示されます。
-
ベースラインインサイト: ベースラインインサイトは、主要なパフォーマンスメトリックの履歴ベースラインからの偏差を提供します。これらのインサイトは、主要なメトリックが改善しているか悪化しているかを一目で示します。これにより、インシデントの兆候を迅速に特定し、環境のパフォーマンスを向上させるためのプロアクティブな措置を講じることができます。
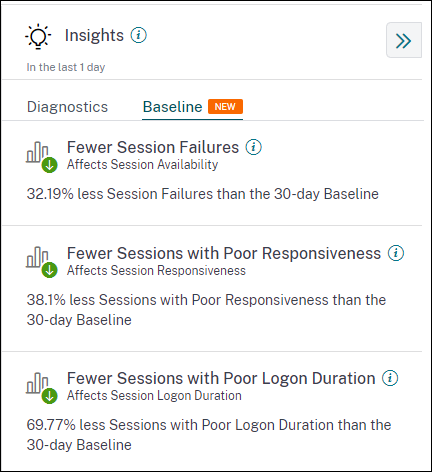
セッション障害、セッション応答性、およびセッションログオン期間のベースラインインサイトは、ベースラインサブペインで利用できます。このペインには、セッション障害、セッション応答性の低下、およびセッションログオン期間の低下を伴うセッションが少ないか多いかが表示されます。 ベースラインは、インサイトが導出されるのと同じ時間間隔で測定された過去30日間のメトリックのP80値に基づいています。P80値は、停止などの外れ値の条件がベースラインを膨らませないようにするために使用されます。 たとえば、現在のタイムスタンプが2022年9月23日午後2時35分で、過去2時間のセッション障害ベースラインインサイトを表示することを選択した場合、ベースラインは過去30日間の午後12時35分から午後2時35分の間隔におけるセッション障害のP80値として計算されます。
注:
- ベースラインインサイトは、新規顧客がオンボーディングされてから7日後に利用可能になります。
- アラートパラメータを更新すると、UXダッシュボード上の対応するインサイトの計算も変更されます。詳細については、「アラート」を参照してください。
診断インサイト: ブラックホールマシン
環境内の一部のマシンは、登録されており正常に見えても、それらに仲介されたセッションを処理しない場合があり、その結果、障害が発生します。4つ以上の連続したセッション要求を処理できなかったマシンは、ブラックホールマシンと呼ばれます。これらの障害の原因は、RDSライセンスの不足、断続的なネットワークの問題、マシンへの瞬間的な負荷など、マシンに影響を与える可能性のあるさまざまな要因に関連しています。これらの障害には、容量またはライセンスの可用性による障害は含まれません。環境内にブラックホールマシンが存在すると、セッション障害が増加し、セッションの可用性が低下します。 ブラックホールマシンインサイトは、選択した期間中に環境で識別されたブラックホールマシンの数を示します。
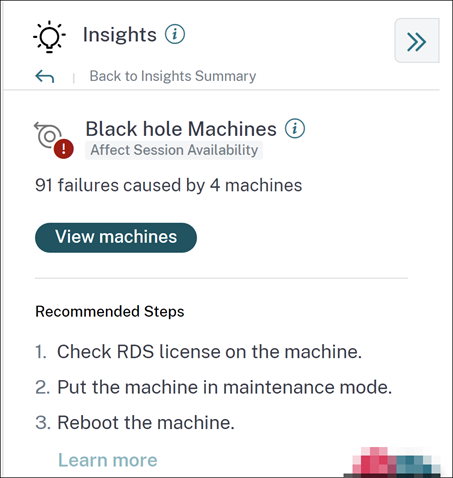
[マシンの表示] をクリックすると、選択した期間中に環境内のすべてのブラックホールマシンを表示するようにフィルタリングされたマシンベースのセルフサービスビューが開きます。ここでは、マシンの個々のパフォーマンスメトリックを分析して、マシンがセッション要求を受け入れない可能性のある理由を特定し、理解することができます。マシンベースのセルフサービスビューで利用可能なパフォーマンスインジケータの詳細については、「マシンのセルフサービス検索」を参照してください。 さらに、マシン名をクリックすると、マシンのリソースパフォーマンスパラメータとセッションパフォーマンスパラメータを同じ期間で関連付けるのに役立つマシン統計ビューが開きます。詳細については、「マシン統計ビュー」の記事を参照してください。
ブラックホールの数を減らすのに役立つ推奨手順は次のとおりです。
- RDSライセンスステータスの確認
- マシンをメンテナンスモードにする
- マシンを再起動する
検出されたパターンセクションには、次の基準に関してブラックホールマシンで検出された上位3つのパターンが表示されます。
- 各デリバリーグループ内のブラックホールマシンの数
- シングルセッションまたはマルチセッションOSを実行しているブラックホールマシンの数
ブラックホールマシンアラートの詳細については、「アラート」の記事を参照してください。
診断インサイト: 通信エラー
通信エラーサブペインには、エンドポイント(ユーザーがセッションを起動する場所)とマシン間の通信エラーによるセッション障害の数が表示されます。これらのエラーは、ファイアウォール設定の誤りやネットワークパス上のその他のエラーが原因で発生する可能性があります。
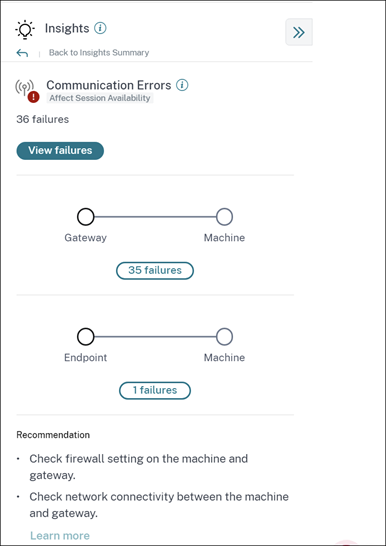
通信エラーの2つのカテゴリは次のとおりです。
- エンドポイントからマシンへ — エンドポイントとマシン間で通信エラーが発生したセッションを一覧表示します。
- ゲートウェイからマシンへ — ゲートウェイとマシン間で通信エラーが発生したセッションを一覧表示します。
さらに、通信エラーサブペインには、エラーを解決するための次の推奨事項が表示されます。
- マシンとゲートウェイのファイアウォール設定を確認します。
- マシンとゲートウェイ間のネットワーク接続を確認します。
障害番号をクリックすると、選択した期間中に環境内で通信エラーにより失敗したすべてのセッションを表示するようにフィルタリングされたセッションベースのセルフサービスビューが開きます。このビューは、失敗した個々のセッションを分析し、考えられる根本原因を特定するのに役立ちます。セッションベースのセルフサービスビューで利用可能なインジケータの詳細については、「セッションのセルフサービス検索」を参照してください。
診断インサイト: ゾンビセッション
ゾンビセッションサブペインには、環境内のゾンビセッションが原因で発生したセッション障害に関する情報が表示されます。ゾンビセッションとは、シングルセッションOSマシン上で放棄されたセッションであり、そのマシン上での新しいセッション起動が失敗する原因となります。このマシン上でセッションを起動しようとすると、容量不足エラーで失敗します。放棄されたセッションが終了するまで、将来のすべてのセッション起動試行は失敗します。ゾンビセッションインサイトは、放棄されたセッションを持つこれらのマシンを特定し、これらの障害をプロアクティブに軽減するのに役立つことを目的としています。
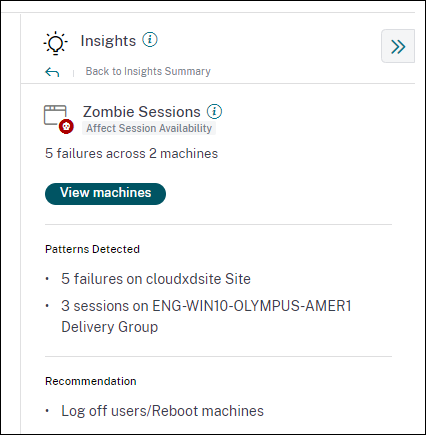
[マシンの表示] をクリックすると、ゾンビセッションを含むマシンのリストでフィルタリングされたセルフサービスビューに移動します。
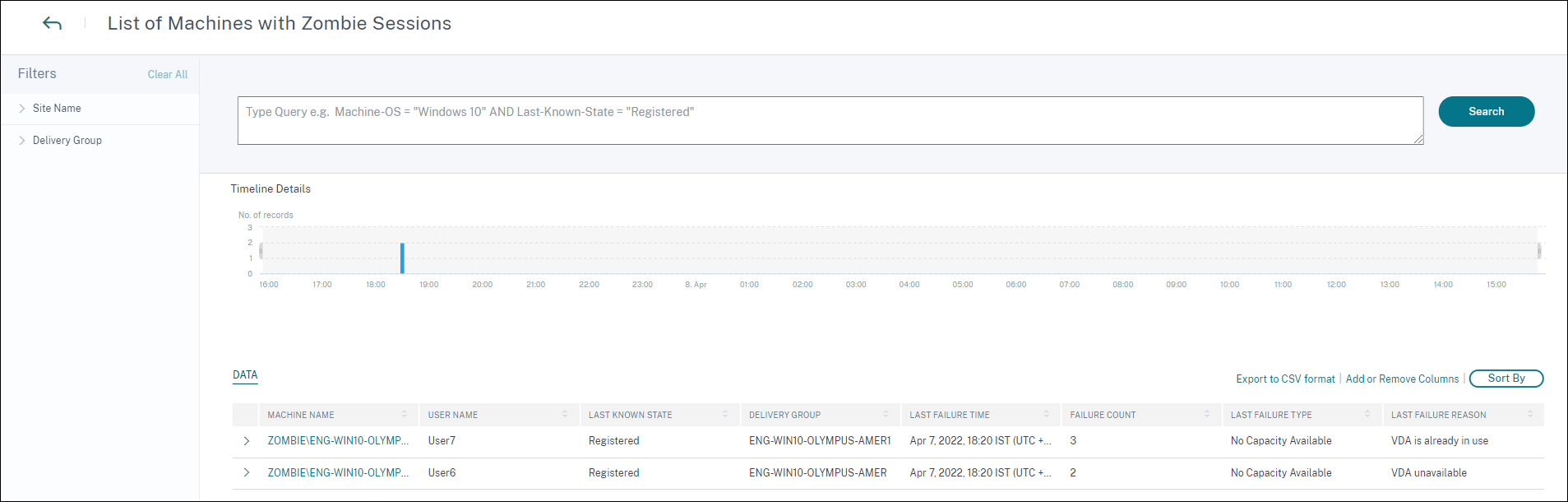
ここで、障害数は、選択した間隔で発生したセッション障害の数を表します。最後の障害タイプと理由は、ゾンビセッションを含むマシンの根本原因を特定するのに役立ちます。
15分間隔で環境内にゾンビセッションを持つ新しいマシンが検出されると、ゾンビセッションアラートメールが生成されます。詳細については、「ゾンビセッションを持つマシンに関するアラート」の記事を参照してください。
ゾンビセッションの推奨アクション
ゾンビセッションを含むマシンからユーザーをログオフするか、マシンを再起動することができます。
-
Citrix DaaSサイトのMonitorを使用して、ゾンビセッションからユーザーをログオフできます。詳細については、「サイト分析」の記事を参照してください。
-
Performance Analyticsからゾンビセッションを含むマシンを再起動できます。詳細については、「マシンアクション」の記事を参照してください。
診断インサイト: 過負荷マシン
過負荷マシンインサイトは、エクスペリエンスの低下を引き起こす過負荷リソースの可視性を提供します。選択した期間中に、持続的なCPUスパイク、または高いメモリ使用量、あるいはその両方が5分以上続き、ユーザーエクスペリエンスの低下を引き起こしたマシンは、過負荷と見なされます。環境内には、リソース使用量が高いがユーザーエクスペリエンスに影響を与えない他のマシンが存在する可能性があります。これらのマシンは過負荷マシンとして分類されません。
過負荷マシンインサイトは、選択した期間における過負荷マシンの数と影響を受けたユーザーの数を示します。
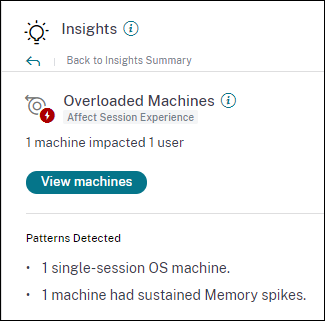
[マシンの表示] をクリックすると、過負荷マシンのマシンセルフサービスページに過負荷マシンが一覧表示されます。過負荷マシンは、選択した間隔でこれらのマシンで発生した持続的なメモリおよびCPUスパイクの数とともに一覧表示されます。
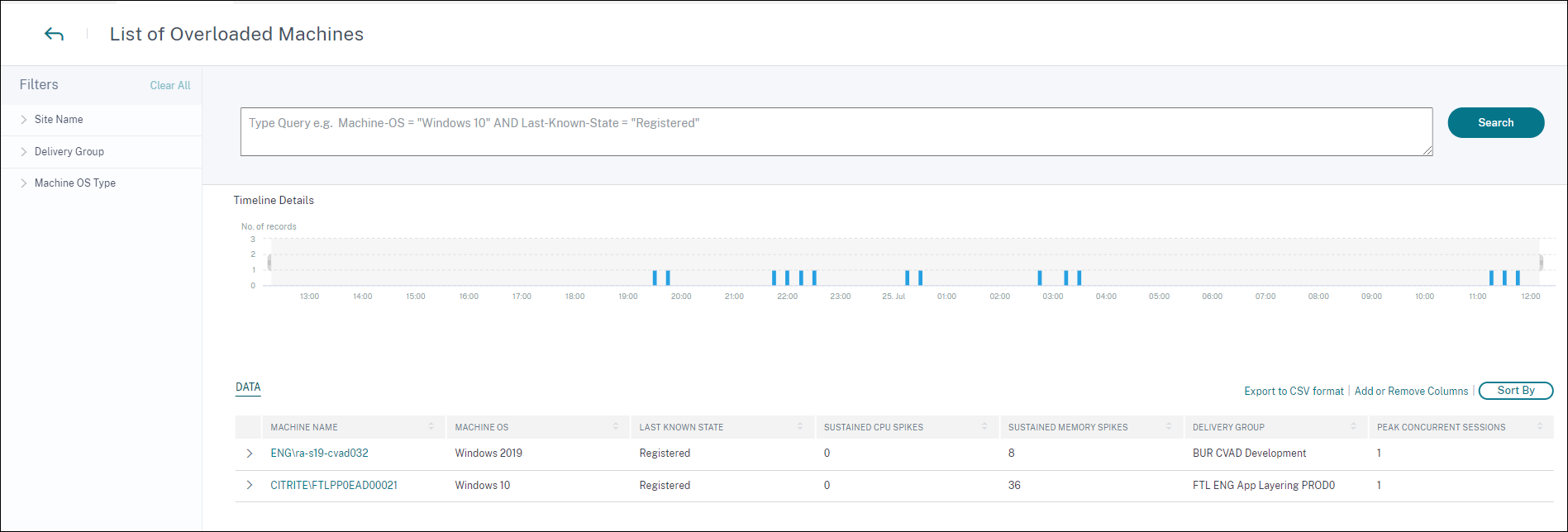
タイムライングラフは、選択した時間間隔で15分間隔でプロットされた過負荷状態になったマシンの数を示します。 特定のマシンをクリックすると、マシン統計ビューが表示されます。
検出されたパターンセクションには、次の基準に関して過負荷マシンで検出された上位3つのパターンが表示されます。
- 各デリバリーグループ内の過負荷マシンの数
- シングルセッションまたはマルチセッションOSを実行している過負荷マシンの数
- 持続的なメモリまたはCPUスパイクを伴う過負荷マシンの数
過負荷マシンアラートの詳細については、「アラート」の記事を参照してください。
ベースラインインサイト: セッション障害
このインサイトは、セッション障害数の30日間ベースライン値からの偏差を示します。ベースライン値は、過去30日間の同じ時間枠で測定されたセッション障害数のP80値として計算されます。
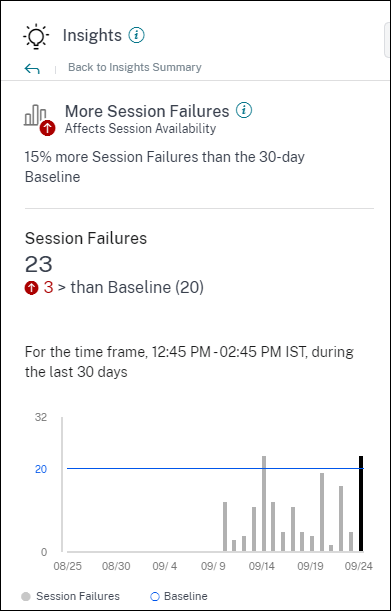
セッション障害ベースラインインサイトを展開すると、次の情報が表示されます。
- ベースライン値と比較した現在のセッション障害数の変化率
- 現在のセッション障害数
- ベースライン値に対するセッション障害数の増減
- 過去30日間にわたってプロットされたベースライン値とセッション障害数を示すグラフ
ベースラインインサイト: セッション応答性
このインサイトは、応答性の低いセッション数の30日間ベースライン値からの偏差を示します。ベースライン値は、過去30日間の同じ時間枠で測定された応答性の低いセッション数のP80値として計算されます。
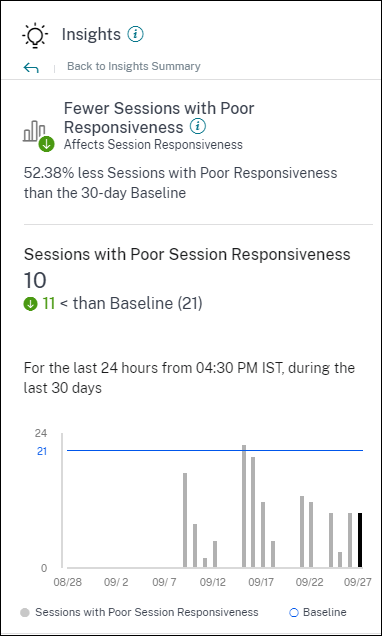
セッション応答性ベースラインインサイトを展開すると、次の情報が表示されます。
- ベースライン値と比較した現在の応答性の低いセッション数の変化率
- 現在の応答性の低いセッション数
- ベースライン値に対する応答性の低いセッション数の増減
- 過去30日間にわたってプロットされたベースライン値と応答性の低いセッション数を示すグラフ
ベースラインインサイト: セッションログオン期間
ログオン期間が短いセッションベースラインインサイトは、ログオン期間が短いセッション数の30日間ベースライン値からの偏差を示します。ベースライン値は、過去30日間の同じ時間枠で測定されたログオン期間が短いセッション数のP80値として計算されます。
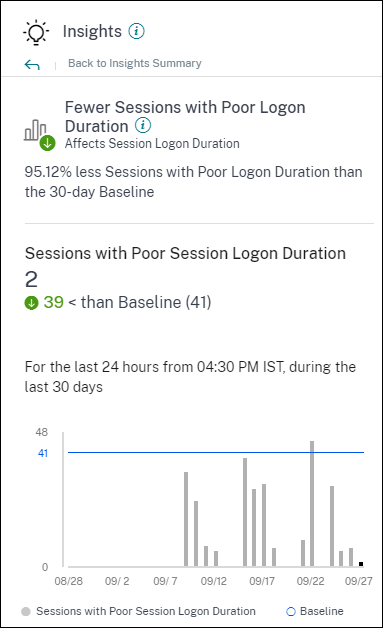
セッションログオン期間ベースラインインサイトを展開すると、次の情報が表示されます。
- ベースライン値と比較した現在のログオン期間が短いセッション数の変化率
- 現在のログオン期間が短いセッション数
- ベースライン値に対するログオン期間が短いセッション数の増減
- 過去30日間にわたってプロットされたベースライン値とログオン期間が短いセッション数を示すグラフ
ベースラインインサイト: 異常な応答性のセッション
このインサイトは、応答性が30日間のユーザー固有の応答性ベースライン値よりも高いセッションとユーザーの数を示します。ベースライン値は、過去30日間の同じ時間枠で測定されたP95 ICARTT値を使用して計算されます。
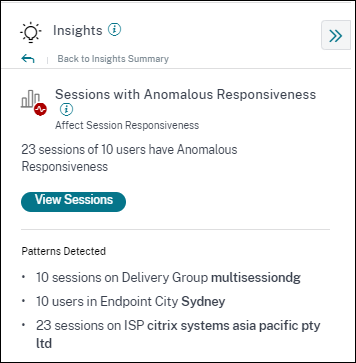
このインサイトを展開すると、次のデータが表示されます。
- [セッションの表示] リンクをクリックすると、選択した期間中に異常な応答性を持つセッションを一覧表示するセルフサービスビューに移動します。
- デリバリーグループ、エンドポイント都市、ISPに関して検出された上位のパターンが表示され、特定の一群のユーザーが問題に遭遇しているかどうかを特定するのに役立ちます。
ベースラインインサイト: 異常なセッション切断
異常なセッション切断ベースラインインサイトは、セッション切断数の30日間ベースライン値からの偏差を示します。ベースライン値は、過去30日間の同じ時間枠で測定されたセッション切断数のP80値として計算されます。
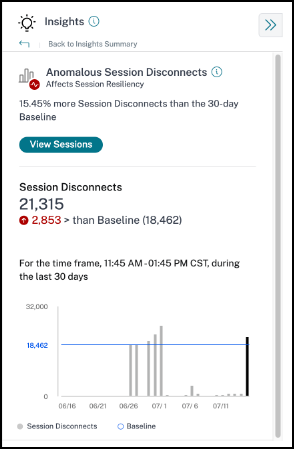
セッション切断ベースラインインサイトを展開すると、次の情報が表示されます。
- ベースライン値と比較した現在のセッション切断数の変化率
- 現在のセッション切断数
- ベースライン値に対するセッション切断数の増減
- 過去30日間にわたってプロットされたベースライン値とセッション切断数を示すグラフ