This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
監視
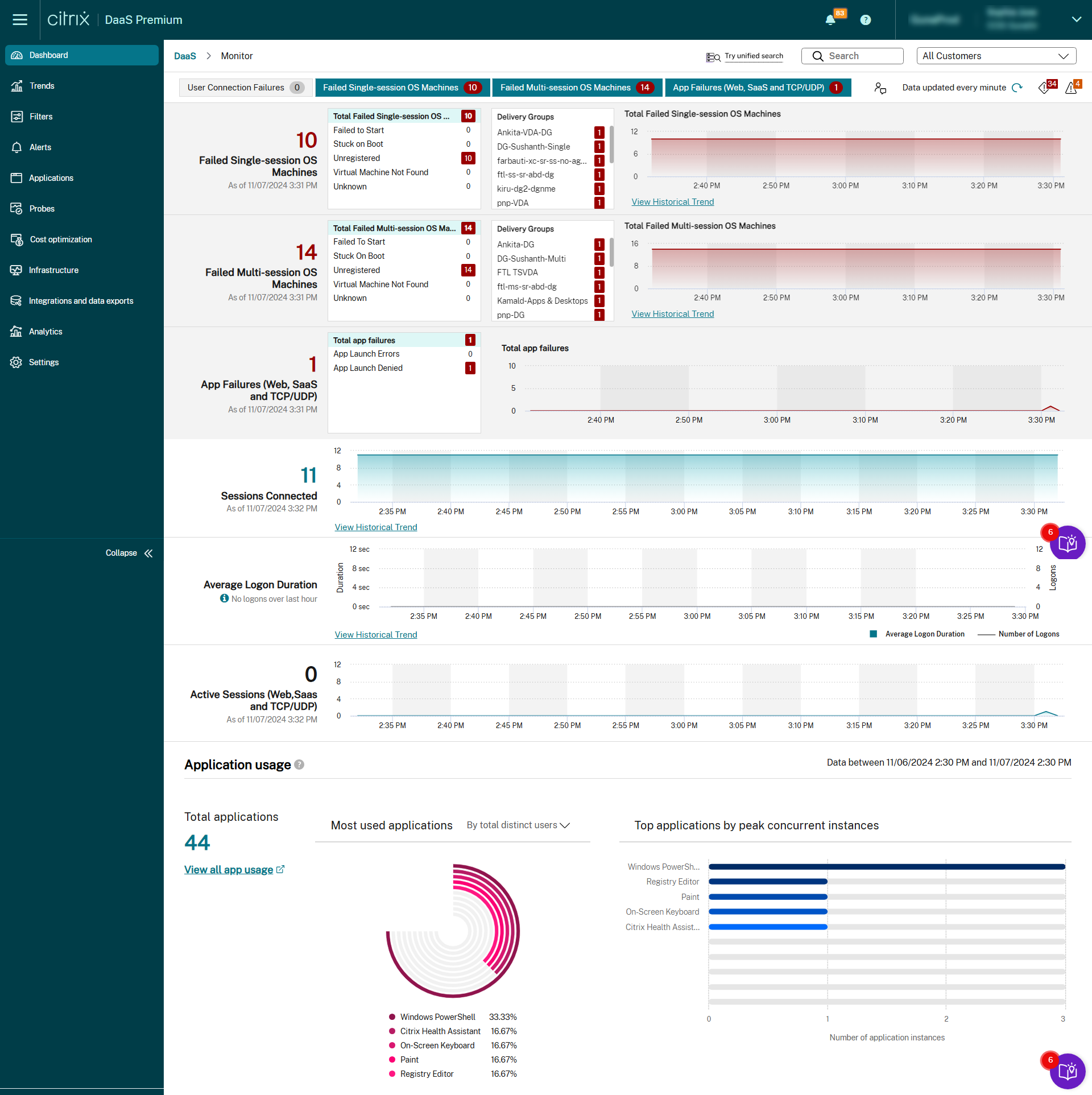
管理者およびヘルプデスクのスタッフは、監視およびトラブルシューティングコンソールである [監視] からCitrix DaaS(旧称Citrix Virtual Apps and Desktopsサービス)を監視できます。 Monitorノードから移動するダッシュボードでは、監視、トラブルシューティング、利用者をサポートするタスクを実行できます。
注
Monitorは、Directorコンソールとして使用でき、Citrix Virtual Apps and Desktopsの最新リリースおよびLTSR環境で、監視およびトラブルシューティング機能を提供します。
[監視] にアクセスするには、Citrix Cloudにサインインします。 左上のメニューで、[マイサービス]>[DaaS]を選択します。 [監視] をクリックします。
注
Citrix Monitorの表示に推奨される最適な画面解像度は1440 × 1024です。
[監視]は以下の機能を提供します:
- Broker Agentからのリアルタイムデータ。AnalyticsおよびPerformance Managerの機能が統合されたコンソールを使用します。
- Analyticsには、ヘルスおよびキャパシティのチェック機能と履歴傾向が含まれており、Citrix DaaS環境のネットワークによるボトルネックを検出できます。
- 監視データベースに格納される履歴データ。構成ログデータベースへのアクセスで使用されます。
- Citrix DaaS環境の仮想アプリケーションやデスクトップを使用するエンドユーザーのユーザーエクスペリエンスを視覚化できます。
- [監視]では、Citrix DaaSのリアルタイムおよび履歴ヘルス監視を提供するトラブルシューティングダッシュボードが使用されます。 この機能により、リアルタイムで問題を確認して、エンドユーザーがどのような問題に直面しているのかを判断できるようになります。
共有
共有
この記事の概要
This Preview product documentation is Citrix Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Citrix Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Citrix product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.