Caché de host local
Para que la base de datos del sitio de Citrix Virtual Apps and Desktops esté siempre disponible, Citrix recomienda empezar con una implementación de SQL Server con tolerancia a fallos que resulta de las prácticas recomendadas para la alta disponibilidad de Microsoft (Para conocer las funciones de alta disponibilidad de SQL Server compatibles, consulte Bases de datos). Sin embargo, los problemas y las interrupciones de la red pueden provocar que los usuarios no puedan conectarse a sus aplicaciones o escritorios.
La función Caché de host local permite que las operaciones de intermediación (broker) de las conexiones en un sitio continúen cuando se produce una interrupción. Se produce una interrupción del servicio cuando se interrumpe la conexión entre un Delivery Controller™ y la base de datos del sitio en un entorno local de Citrix®. La función Caché de host local se activa cuando no se puede acceder a la base de datos del sitio durante 90 segundos.
A partir XenApp y XenDesktop 7.16, la Concesión de conexiones (una función de alta disponibilidad en versiones anteriores) se eliminó de XenApp y XenDesktop, y ya no está disponible.
Contenido de datos
La Caché de host local incluye la siguiente información, que es un subconjunto de la información contenida en la base de datos principal:
- Identidades de los usuarios y los grupos que tienen derechos asignados a recursos publicados en el sitio.
- Identidades de los usuarios que actualmente usan, o que han utilizado recientemente, recursos publicados en el sitio.
- Identidades de las máquinas VDA (incluidas las máquinas de acceso con Remote PC) configuradas en el sitio.
- Identidades (nombres y direcciones IP) de las máquinas cliente de Citrix Receiver™ que se usan activamente para conectarse a recursos publicados.
También contiene información para las conexiones actualmente activas que se establecieron mientras la base de datos principal no estaba disponible:
- Resultados de todos los análisis de máquinas de punto final del cliente realizados por Citrix Receiver.
- Identidades de las máquinas de la infraestructura (tales como NetScaler Gateway y servidores de StoreFront™) que intervienen en las operaciones del sitio.
- Fechas, horas y tipos de actividades recientes de los usuarios.
Funcionamiento
En el siguiente gráfico, se muestran los componentes de Caché de host local y las rutas de comunicación que se establecen durante un funcionamiento normal.
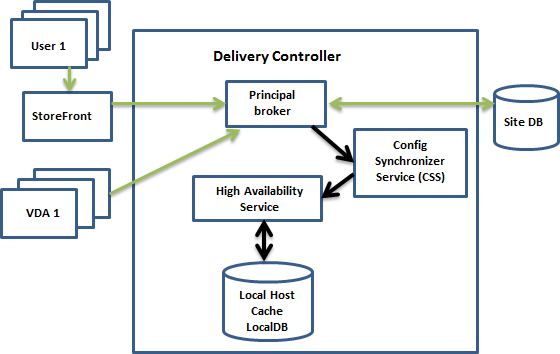
Durante el funcionamiento normal
- El broker principal (conocido también como Citrix Broker Service) en un Controller acepta las solicitudes de conexión provenientes de StoreFront, y se comunica con la base de datos del sitio para conectar usuarios a los agentes VDA que están registrados en el Controller.
- El servicio Citrix Config Synchronizer Service (CSS) se comunica con el broker aproximadamente cada 5 minutos para comprobar si se han hecho cambios. Esos cambios pueden haberse iniciado por la acción de un administrador (si modifica una propiedad del grupo de entrega, por ejemplo) o por acciones del sistema (como las asignaciones de máquinas).
-
Si se ha producido un cambio de configuración desde la comprobación anterior, CSS sincroniza la información (la copia) con un broker secundario presente en el Controller. (El broker secundario también se conoce como servicio de alta disponibilidad.)
Se copian todos los datos de la configuración, no solo los elementos que han cambiado desde la comprobación anterior. El servicio CSS importa los datos de configuración en una base de datos LocalDB de Microsoft SQL Server Express ubicada en el Controller. Esta base de datos se conoce como la base de datos de la Caché de host local. El servicio CSS comprueba que la información de la base de datos de caché de host local coincida con la información presente en la base de datos del sitio. La base de datos de la Caché de host local se crea con cada sincronización.
Microsoft SQL Server Express LocalDB (que la base de datos de caché de host local utiliza) se instala automáticamente al instalar un Controller. (Puede prohibir esta instalación al instalar un Controller desde la línea de comandos). La base de datos de caché del host local no se puede compartir entre Controllers. No es necesario realizar una copia de seguridad de la base de datos de la Caché de host local. Se vuelve a crear cada vez que se detecta un cambio de configuración.
- Si no se han producido cambios desde la última comprobación, no se copian los datos.
En el siguiente gráfico, se muestran los cambios que se realizan en las rutas de comunicación si se interrumpe la conexión entre el broker principal y la base de datos del sitio:
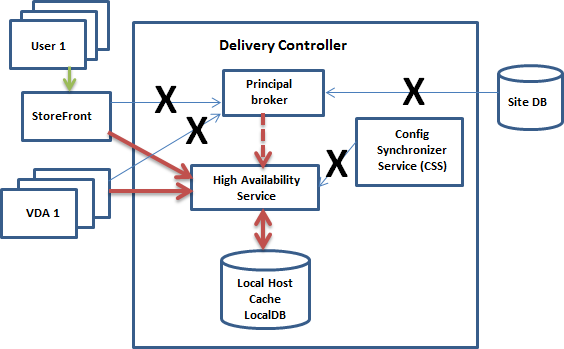
Durante una interrupción del servicio
Al principio de una interrupción del servicio:
- El broker secundario comienza a escuchar y a procesar las solicitudes de conexión.
- Cuando empieza la interrupción, el broker secundario no dispone de datos actuales de registro de agentes VDA, pero, en cuanto un VDA se comunica con él, comienza un proceso de registro. Durante este proceso, el broker secundario también obtiene información de sesión actualizada acerca de ese VDA.
- Mientras el broker secundario gestiona las conexiones, el broker principal sigue supervisando la conexión. Cuando se restaura la conexión, el broker principal indica al secundario que deje de escuchar para obtener la información de conexión. A continuación, el broker principal reanuda la intermediación. La próxima vez que el VDA se comunica con el broker principal, comienza un proceso de registro. El broker secundario elimina los registros de VDA restantes desde la interrupción anterior. El servicio CSS reanuda la sincronización de información cuando detecta que se han producido cambios de configuración en la implementación.
En el caso improbable de que se inicie una interrupción durante una sincronización, la importación de ese momento se descarta y se utiliza la última configuración conocida.
El registro de eventos proporciona información sobre sincronizaciones e interrupciones del servicio.
No hay límites de tiempo impuestos para el funcionamiento en modo de interrupción.
La transición entre el modo normal y el de interrupción no afecta a las sesiones existentes. Afecta solo al inicio de nuevas sesiones.
También puede desencadenar intencionadamente una interrupción. Consulte Forzar una interrupción para obtener más información sobre cómo y por qué hacerlo.
Sitios con varios Controllers
Entre otras de sus tareas, CSS proporciona constantemente al broker secundario información sobre todos los Controllers de la zona. (Si su implementación no contiene varias zonas, esta acción afecta a todos los Controllers del sitio). Con esta información, cada broker secundario sabe cuáles son todos los demás brokers secundarios que se ejecutan en otros Controllers de la zona.
Los brokers secundarios se comunican entre sí por un canal independiente. Estos brokers utilizan una lista alfabética de nombres de dominio completo (FQDN) de las máquinas en las que están ejecutando para determinar (elegir) qué broker secundario intermediará las operaciones de la zona si se produce una interrupción. Durante la interrupción, todos los VDA vuelven a registrarse en el broker secundario que se haya elegido. Los brokers secundarios de la zona que no hayan sido elegidos rechazan las solicitudes entrantes de conexión y de registro que les envíen los agentes VDA.
Si un broker secundario elegido falla durante una interrupción del servicio, se elegirá otro broker secundario para que le releve, y los VDA se registrarán en el broker secundario que acaba de elegirse.
Durante una interrupción, si se reinicia un Controller:
- Si ese Controller no es el broker elegido, el reinicio no tiene repercusión.
- Si ese Controller es el broker elegido, se elegirá otro Controller, por lo que los VDA deberán volver a registrarse. Después de que el Controller reiniciado se encienda, se hace cargo automáticamente de la intermediación, por lo que los VDA deben volver a registrarse. En este caso, el rendimiento puede verse afectado durante los registros.
Si apaga un Controller durante las operaciones normales y lo enciende durante una interrupción, la función Caché de host local no se puede utilizar en ese Controller si este se elige como broker.
Los registros de eventos proporcionan información sobre las opciones elegidas.
Lo que no está disponible durante una interrupción y otras diferencias
No hay límites de tiempo impuestos para el funcionamiento en modo de interrupción. Sin embargo, Citrix recomienda restaurar la conectividad lo antes posible.
Durante una interrupción:
- No puede utilizar Studio.
-
Tiene acceso limitado al SDK de PowerShell.
- Primero debe:
- Agregar una clave de Registro
EnableCssTestModewith a value of 1:New-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer\LHC -Name EnableCssTestMode -PropertyType DWORD -Value 1 - Usar el puerto 89:
Get-BrokerMachine -AdminAddress localhost:89 | Select MachineName, ControllerDNSName, DesktopGroupName, RegistrationState
- Agregar una clave de Registro
- Después de ejecutar esos comandos, puede acceder a:
- Todos los cmdlets
Get-Broker*.
- Todos los cmdlets
- Primero debe:
- Host Service no puede proporcionar credenciales de hipervisor. Todas las máquinas están en el estado de energía desconocido (unknown) y no se pueden emitir operaciones de administración de energía. No obstante, las máquinas virtuales del host que estén encendidas se pueden utilizar para las solicitudes de conexión.
- Una máquina asignada solo se puede usar si la asignación se dio durante el funcionamiento normal. No se pueden realizar asignaciones nuevas durante una interrupción del servicio.
- No se puede configurar ni inscribir automáticamente las máquinas de acceso con Remote PC. En cambio, las máquinas que se inscribieron y configuraron durante el funcionamiento normal se pueden usar.
- Si los recursos están en zonas diferentes, es posible que los usuarios de aplicaciones y escritorios alojados en servidores superen la cantidad de sesiones indicadas en el límite configurado de sesiones.
- Los usuarios solo pueden iniciar aplicaciones y escritorios desde los VDA registrados en la zona que contiene el broker secundario actualmente activo o elegido. Durante una interrupción, no se admiten inicios entre zonas (desde un broker secundario de una zona a un VDA de otra zona).
- Si se produce una interrupción de la base de datos del sitio antes de que comience un reinicio programado para los agentes VDA de un grupo de entrega, los reinicios comienzan cuando finaliza la interrupción del servicio. Esto puede provocar resultados inesperados. Para obtener más información, consulte Reinicios programados que se retrasan por una interrupción de la base de datos.
- La preferencia de zonas no puede configurarse. Si se configura, no se tienen en cuenta las preferencias para el inicio de sesión.
- Las restricciones por etiquetas en las que se utilizan etiquetas para designar zonas no se admiten para el inicio de sesiones. Cuando se configuran tales restricciones por etiquetas y la opción de comprobación avanzada de estado de un almacén de StoreFront está habilitada, es posible que las sesiones no consigan iniciarse de forma intermitente.
Compatibilidad con aplicaciones y escritorios
LHC admite los siguientes tipos de VDA y modelos de entrega:
| Tipo de VDA | Modelo de entrega | Disponibilidad de los VDA durante los eventos LHC |
|---|---|---|
| SO multisesión | Aplicaciones y escritorios | Siempre disponible. |
| Sistema operativo de sesión única estático (asignado) | Escritorios | Siempre disponible. |
| Sistema operativo de sesión única con administración de energía aleatorio (agrupado)
|
Escritorios
|
No está disponible de forma predeterminada. De forma predeterminada, fallarán todos los intentos de iniciar sesión en los VDA con administración de energía en grupos de entrega agrupados.
Puede hacer que estén disponibles para nuevas conexiones durante los eventos del LHC. Para obtener más información, consulte Habilitar con Web Studio y Habilitar con PowerShell. Importante: Habilitar el acceso a máquinas agrupadas de sesión única con administración de energía puede provocar que los datos y los cambios de las sesiones de usuario anteriores estén presentes en las sesiones posteriores. |
Nota:
Habilitar el acceso a los VDA de escritorio con administración de energía en grupos de entrega agrupados no afecta al funcionamiento de la propiedad
ShutdownDesktopsAfterUseconfigurada durante las operaciones normales. Cuando se habilita el acceso a estos escritorios en el modo LHC, los VDA no se reinician automáticamente una vez finalizado el evento de LHC. Los VDA de escritorio con administración de energía de los grupos de entrega agrupados pueden retener los datos de las sesiones anteriores hasta que se reinicie el VDA. El reinicio del VDA puede producirse cuando un usuario cierra sesión en el VDA durante operaciones ajenas al LHC o cuando los administradores reinician el VDA.
Habilitar LHC para los VDA agrupados de SO de sesión única con administración de energía mediante Web Studio
Con Web Studio, puede hacer que esas máquinas estén disponibles para nuevas conexiones durante los eventos de LHC para los grupos de entrega que seleccione:
- Para habilitar esta función durante la creación de grupos de entrega, consulte Crear grupos de entrega.
- Para habilitar esta función para un grupo de entrega existente, consulte Administrar grupos de entrega.
Nota:
Este parámetro solo está disponible en Web Studio para los grupos de entrega de escritorios agrupados que entregan VDA con administración de energía.
Habilitar LHC para los VDA agrupados de SO de sesión única con administración de energía mediante PowerShell
Para habilitar LHC para los VDA en un grupo de entrega específico, siga estos pasos:
-
Ejecute este comando para habilitar esta función para todo el sitio:
Set-BrokerSite -ReuseMachinesWithoutShutdownInOutageAllowed $true -
Ejecute este comando con un nombre del grupo de entrega especificado para habilitar LHC para ese grupo de entrega:
Set-BrokerDesktopGroup -Name "name" -ReuseMachinesWithoutShutdownInOutage $true
Para cambiar la disponibilidad de LHC predeterminada para los grupos de entrega agrupados recién creados con agentes VDA con administración de energía, ejecute el siguiente comando:
Set-BrokerSite -DefaultReuseMachinesWithoutShutdownInOutage $true
Consideraciones sobre tamaño de RAM
El servicio LocalDB puede usar aproximadamente 1,2 GB de RAM (1 GB máximo para la caché de la base de datos, más 200 MB para ejecutar LocalDB de SQL Server Express). El broker secundario puede usar hasta 1 GB de RAM si la interrupción es duradera y se producen muchos inicios de sesión (por ejemplo, 12 horas con 10 000 usuarios). Estos requisitos de memoria son adicionales a los requisitos de memoria RAM habituales para el Controller. Por lo tanto, es posible que necesite aumentar la cantidad total de RAM.
Si usa una base de datos de SQL Server Express como la base de datos del sitio, el servidor tendrá dos procesos sqlserver.exe.
Consideraciones sobre la configuración de sockets y núcleo de CPU
La configuración de la CPU de un Controller, especialmente la cantidad de núcleos disponibles para la base de datos LocalDB de SQL Server Express, afecta directamente al rendimiento que tendrá la Caché de host local, incluso más que la asignación de memoria. Este consumo de recursos de CPU solo se ha observado durante el período de interrupción cuando la base de datos no está disponible y el broker secundario está activo.
A pesar de que LocalDB pueda usar varios núcleos (hasta 4), está limitada a solamente un socket. Agregar más sockets no mejorará el rendimiento (por ejemplo, tener 4 sockets con 1 núcleo cada uno). En vez de ello, Citrix recomienda usar varios sockets con varios núcleos. En las pruebas llevadas a cabo por Citrix, una configuración de 2x3 (2 sockets, 3 núcleos) proporciona un mejor rendimiento que las configuraciones 4x1 y 6x1.
Consideraciones sobre almacenamiento
LocalDB aumenta de tamaño a medida que los usuarios acceden a los recursos durante una interrupción. Por ejemplo: durante una prueba de inicio y cierre de sesión en la que se ejecutan 10 inicios de sesión por segundo, la base de datos aumentó de tamaño 1 MB cada 2 o 3 minutos. Cuando se reanuda el funcionamiento normal, la base de datos local se vuelve a crear y el espacio se devuelve. No obstante, debe haber suficiente espacio en la unidad donde está instalada LocalDB para permitir el aumento del tamaño de la base de datos durante una interrupción. La caché de host local también incurre en más E/S durante una interrupción: aproximadamente 3 MB de escrituras por segundo, con varios cientos de miles de lecturas.
Consideraciones sobre rendimiento
Durante una interrupción, un solo broker secundario se encarga de todas las conexiones, por lo que, en los sitios (o las zonas) con carga equilibrada entre varios Controllers durante el funcionamiento normal, es posible que el broker secundario elegido deba gestionar muchas más solicitudes durante una interrupción que en una situación normal. Por lo tanto, la necesidad de CPU será mucho mayor. Todos los brokers secundarios del sitio (zona) deben ser capaces de gestionar la carga adicional impuesta por la base de datos de caché de host local y todos los agentes VDA afectados, ya que el broker secundario elegido durante una interrupción puede cambiar.
Límites de VDI:
- En una implementación de VDI de zona única, se puede controlar hasta 10 000 agentes VDA durante una interrupción.
- En una implementación de VDI de varias zonas, se puede controlar hasta 10 000 agentes VDA por zona durante una interrupción, hasta un máximo de 40 000 agentes VDA en el sitio. Por ejemplo: cada uno de los siguientes sitios puede controlarse de forma eficaz durante una interrupción:
- Un sitio de cuatro zonas, cada zona con 10 000 agentes VDA.
- Un sitio con siete zonas, una zona con 10 000 agentes VDA y seis zonas con 5000 agentes VDA.
Durante una interrupción, la administración de carga dentro del sitio puede verse afectada. Es posible que se superen los patrones de carga (especialmente, las reglas de recuento de sesiones).
Mientras todos los VDA se registran en un broker secundario, este puede no disponer de información completa sobre las sesiones actuales. Por lo tanto, si un usuario solicita conectarse durante ese intervalo, puede que se cree una nueva sesión aunque la reconexión a una sesión existente fuera posible. Este intervalo (mientras el “nuevo” broker secundario obtiene la información de sesión de todos los VDA durante el proceso de rerregistro) no se puede evitar. Las sesiones que están conectadas cuando se inicia una interrupción no se verán afectadas durante ese intervalo de transición, pero las sesiones nuevas y las reconexiones sí pueden verse afectadas.
Este intervalo se da siempre que los VDA deben volver a registrarse:
- Comienza una interrupción: Al migrar desde un broker principal a un broker secundario.
- Fallo de broker secundario durante una interrupción: Al migrar desde un broker secundario en que se produjo el fallo a otro broker secundario que acaba de elegirse.
- Recuperación de una interrupción: Cuando se reanudan las operaciones normales y el broker principal retoma el control.
Puede reducir el intervalo si disminuye el valor de Registro HeartbeatPeriodMs del protocolo del broker de Citrix (el valor predeterminado es 600000 ms, que equivale a 10 minutos). Este valor de latido es el doble del intervalo que usa el VDA para los pings, por lo que el valor predeterminado da como resultado un ping cada 5 minutos.
Por ejemplo: este comando cambia el latido a cinco minutos (300 000 milisegundos), lo que resulta en un ping cada 2 minutos y medio:
New-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer -Name HeartbeatPeriodMs -PropertyType DWORD –Value 300000
Tenga cuidado al cambiar el valor de latido. Aumentar la frecuencia resulta en una mayor carga en los Controllers durante los modos de funcionamiento normal y el de interrupción.
El intervalo no se puede eliminar por completo, independientemente de lo rápido que se registren los VDA.
El tiempo que tarda la sincronización entre brokers secundarios aumenta con la cantidad de objetos (como agentes VDA, aplicaciones, grupos). Por ejemplo: sincronizar 5000 agentes VDA podría llevar 10 minutos o más.
Diferencias con versiones de XenApp 6.x
Aunque esta implementación de Caché de host local comparte el nombre con la funcionalidad Caché de host local de XenApp 6.x y versiones anteriores de XenApp, existen entre ellas diferencias importantes. Esta implementación es más sólida e inmune al daño. Los requisitos de mantenimiento se han minimizado; por ejemplo, se ha eliminado la necesidad de comandos dsmaint periódicos. Técnicamente, esta implementación de Caché de host local es completamente diferente.
Administrar la Caché de host local
Para que la “Caché de host local” funcione correctamente, la directiva de ejecución de PowerShell en cada Controller debe establecerse en RemoteSigned, Unrestricted o Bypass.
LocalDB de SQL Server Express
El software de la base de datos LocalDB de Microsoft SQL Server Express que usa la Caché de host local se instala automáticamente al instalar un Controller o actualizarlo desde una versión anterior a 7.9. Solo el broker secundario se comunica con esta base de datos. No puede usar cmdlets de PowerShell para realizar ningún cambio en esta base de datos. La LocalDB no se puede compartir entre los Controllers.
La base de datos LocalDB de SQL Server Express se instala independientemente de si la Caché de host local está habilitada.
Para impedir la instalación, instale o actualice el Controller con el comando XenDesktopServerSetup.exe e incluya la opción /exclude "Local Host Cache Storage (LocalDB)". No obstante, tenga en cuenta que la funcionalidad Caché de host local no funcionará sin la base de datos, y no se puede usar otra base de datos con el broker secundario.
Instalar esta base de datos LocalDB no influye en si instala SQL Server Express para usarla como la base de datos del sitio.
Para obtener información sobre cómo reemplazar una versión anterior de SQL Server Express LocalDB por una versión más reciente, consulte Reemplazar SQL Server Express LocalDB.
Parámetros predeterminados después de la instalación y la actualización de los productos
La Caché de host local se habilita durante una nueva instalación de Citrix Virtual Apps and Desktops (7.16 como versión mínima).
Después de una actualización (a la versión 7.16 o posterior), la Caché de host local se habilita si hay menos de 10 000 agentes VDA en toda la implementación.
Habilitar o inhabilitar la Caché de host local
-
Para habilitar la Caché de host local, escriba:
Set-BrokerSite -LocalHostCacheEnabled $truePara saber si la Caché de host local está habilitada, escriba
Get-BrokerSite. Compruebe que la propiedadLocalHostCacheEnabledesTrue. -
Para inhabilitar la Caché de host local, escriba:
Set-BrokerSite -LocalHostCacheEnabled $false
Recuerde: A partir de XenApp y XenDesktop 7.16, la concesión de conexiones (la función que precedió a la Caché de host local desde la versión 7.6) se ha eliminado del producto y ya no está disponible.
Verificar que la Caché de host local está funcionando
Para verificar que la Caché de host local está configurada y funciona correctamente:
- Compruebe que las importaciones de sincronización se completan correctamente. Verifique los registros de eventos.
- Asegúrese de que la base de datos LocalDB de SQL Server Express se ha creado en cada Delivery Controller. Esto garantiza que el broker secundario pueda hacerse cargo, si fuera necesario.
- En el servidor de Delivery Controller, vaya a
C:\Windows\ServiceProfiles\NetworkService. - Verifique que se hayan creado
HaDatabaseName.mdfyHaDatabaseName_log.ldf.
- En el servidor de Delivery Controller, vaya a
- Fuerce una interrupción en los Delivery Controllers. Una vez que haya verificado que la Caché de host local funciona, recuerde volver a colocar todos los Controllers de nuevo en el modo normal. Esto puede tardar aproximadamente 15 minutos.
Registros de eventos
Los registros de eventos indican cuándo tienen lugar las sincronizaciones y las interrupciones. En los registros del visor de eventos, el modo de interrupción se conoce como modo de alta disponibilidad (HA).*
Config Synchronizer Service:
Durante las operaciones normales, pueden producirse los siguientes eventos cuando el servicio CSS importa los datos de configuración en la base de datos de la Caché de host local a través del broker correspondiente.
- 503: Citrix Config Sync Service recibió una configuración actualizada. Este evento indica el inicio del proceso de sincronización.
- 504: Citrix Config Sync Service importó una configuración actualizada. La importación de la configuración se completó correctamente.
- 505: Falló una importación de Citrix Config Sync Service. La importación de la configuración no se completó correctamente. Si hay una configuración previa disponible, se utiliza si ocurre una interrupción. Sin embargo, estará desactualizada frente a la configuración actual. Si no hay ninguna configuración previa disponible, el servicio no puede participar en la intermediación de sesiones durante una interrupción. En este caso, consulte la sección Solucionar problemas y póngase en contacto con la asistencia de Citrix.
- 507: Citrix Config Sync Service abandonó una importación porque el sistema está en modo de interrupción del servicio y el broker de la Caché de host local se está utilizando para la intermediación. El servicio recibió una nueva configuración, pero la importación fue abandonada debido a una interrupción. Este es el comportamiento esperado.
- 510: No se recibieron datos de configuración del servicio de configuración procedentes del servicio de configuración principal.
- 517: Hubo un problema de comunicación con el broker principal.
- 518: Se ha abortado el script de Config Sync porque el Broker secundario (High Availability Service) no se está ejecutando.
High Availability Service (Servicio de alta disponibilidad):
Este servicio también se conoce como broker de la Caché de host local.
- 3502: Se ha producido una interrupción y el broker de caché de host local está llevando a cabo operaciones de intermediación.
- 3503: Se ha resuelto una interrupción y se ha reanudado el funcionamiento normal.
- 3504: Indica el broker de la Caché de host local elegido, además de otros brokers de caché de host local que hayan participado en la elección.
- 3507: Proporciona una actualización de estado de la memoria caché de host local cada 2 minutos, lo que indica que el modo de caché de host local está activo en el intermediario elegido. Contiene un resumen de la interrupción del servicio, que incluye la duración de la interrupción, el registro de VDA e información de la sesión.
- 3508: Anuncia que la memoria caché de host local ya no está activa en el intermediario elegido y que se han restablecido las operaciones normales. Contiene un resumen de la interrupción del servicio, que incluye la duración de la interrupción, la cantidad de máquinas que se registraron durante el evento de caché de host local y la cantidad de inicios correctos durante dicho evento.
- 3509: Notifica que la memoria caché de host local está activa en los intermediarios no elegidos. Contiene una duración de interrupción del servicio cada 2 minutos e indica el intermediario elegido.
- 3510: Anuncia que la memoria caché de host local ya no está activa en los intermediarios no elegidos. Contiene la duración de la interrupción del servicio e indica el intermediario elegido.
Forzar una interrupción del servicio
Puede que quiera forzar deliberadamente una interrupción.
- Si la red tiene altibajos repetidos. Forzar una interrupción hasta que se resuelvan los problemas de red impide una transición continua entre los modos normal y de interrupción (con las avalanchas de registros de VDA que ello conlleva).
- Para probar un plan de recuperación ante desastres.
- Para comprobar que la Caché de host local funciona correctamente.
- Al cambiar o mantener el servidor de la base de datos del sitio.
Para forzar una interrupción, modifique el Registro de cada servidor que contiene un Delivery Controller. En HKLM\Software\Citrix\DesktopServer\LHC, cree y establezca OutageModeForced como REG_DWORD en 1. Este parámetro indica al broker de la caché de host local que entre en el modo de interrupción, independientemente del estado de la base de datos. Establecer este valor en 0 saca al broker de la Caché de host local del modo de interrupción del servicio.
Para verificar eventos, supervise el archivo de registros Current_HighAvailabilityService en C:\ProgramData\Citrix\WorkspaceCloud\Logs\Plugins\HighAvailabilityService.
Solucionar problemas
Existen varias herramientas de solución de problemas disponibles cuando falla una importación de sincronización a la base de datos de la Caché de host local y se publica un evento 505.
Rastreo CDF: Contiene opciones para los módulos ConfigSyncServer y BrokerLHC. Esas opciones, junto con otros módulos de broker, identificarán probablemente el problema.
Informe: Si falla una importación de sincronización, puede generar un informe. Este informe se detiene en el objeto que causa el error. Esta funcionalidad de informe afecta a la velocidad de sincronización, por lo que Citrix recomienda inhabilitarla cuando no se use.
Para habilitar y generar un informe de seguimiento de CSS, escriba el siguiente comando:
New-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer\LHC -Name EnableCssTraceMode -PropertyType DWORD -Value 1
El informe HTML se publica en C:\Windows\ServiceProfiles\NetworkService\AppData\Local\Temp\CitrixBrokerConfigSyncReport.html.
Una vez generado el informe, introduzca el siguiente comando para inhabilitar la funcionalidad de informes:
Set-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer\LHC -Name EnableCssTraceMode -Value 0
Exportar la configuración de broker: Proporciona la configuración exacta con fines de depuración.
Export-BrokerConfiguration | Out-File <file-pathname>
Por ejemplo, Export-BrokerConfiguration | Out-File C:\\BrokerConfig.xml.
Comandos de PowerShell para la memoria caché de host local
Puede administrar la caché de host local (LHC) en sus Delivery Controllers mediante comandos de PowerShell.
El módulo de PowerShell se encuentra en esta ubicación de los Delivery Controllers:
C:\Program Files\Citrix\Broker\Service\ControlScripts
Importante:
Ejecute este módulo solo en los Delivery Controllers.
Importar módulo de PowerShell
Para importar el módulo, ejecute lo siguiente en su Delivery Controller.
cd C:\Program Files\Citrix\Broker\Service\ControlScripts
Import-Module .\HighAvailabilityServiceControl.psm1
Comandos de PowerShell para administrar la LHC
Estos comandos le ayudan a activar y administrar el modo LHC en los Delivery Controllers.
| Cmdlets | Función |
|---|---|
Enable-LhcForcedOutageMode |
Ponga al intermediario en modo LHC. Los archivos de base de datos de LHC debe haberlos creado correctamente el ConfigSync Service para que Enable-LhcForcedOutageMode funcione correctamente. Este cmdlet solo fuerza a la LHC del Delivery Controller en que se ejecutó. Para que la LHC se active, este comando debe ejecutarse en todos los Delivery Controllers de la zona. |
Disable-LhcForcedOutageMode |
Saque al intermediario del modo LHC. Este cmdlet solo inhabilita el modo LHC en el Delivery Controller en el que se ejecutó. Disable-LhcForcedOutageMode debe ejecutarse en todos los Delivery Controllers de la zona. |
Set-LhcConfigSyncIntervalOverride |
Establece el intervalo en que Citrix Config Synchronizer Service (CSS) comprueba cambios de configuración en el sitio. El intervalo de tiempo puede oscilar entre 60 segundos (un minuto) y 3600 segundos (una hora). Este parámetro solo se aplica al Delivery Controller en el que se ejecutó. Para mantener la coherencia entre los Delivery Controllers, considere la posibilidad de ejecutar este cmdlet en cada Delivery Controller. Por ejemplo: Set-LhcConfigSyncIntervalOverride -Seconds 1200
|
Clear-LhcConfigSyncIntervalOverride |
Establece el intervalo en que Citrix Config Synchronizer Service (CSS) comprueba cambios de configuración en el sitio en función del valor predeterminado de 300 segundos (cinco minutos). Este parámetro solo se aplica al Delivery Controller en el que se ejecutó. Para mantener la coherencia entre los Delivery Controllers, considere la posibilidad de ejecutar este cmdlet en cada Delivery Controller. |
Enable-LhcHighAvailabilitySDK |
Habilita el acceso a todos los cmdlets Get-Broker* del Delivery Controller en que se ejecutó. |
Disable-LhcHighAvailabilitySDK |
Inhabilita el acceso a los cmdlets del intermediario del Delivery Controller en que se ejecutó. |
Nota:
- Use el puerto 89 al ejecutar los cmdlets
Get-Broker*en el Delivery Controller. Por ejemplo:
Get-BrokerMachine -AdminAddress localhost:89- Cuando no está en modo LHC, el intermediario de la LHC del Delivery Controller solo contiene información de configuración.
- Durante el modo LHC, el agente de la LHC del Delivery Controller elegido contiene esta información:
- Estados de los recursos
- Detalles de la sesión
- Registros de VDA
- Información de configuración
En este artículo
- Contenido de datos
- Funcionamiento
- Lo que no está disponible durante una interrupción y otras diferencias
- Compatibilidad con aplicaciones y escritorios
- Administrar la Caché de host local
- Verificar que la Caché de host local está funcionando
- Registros de eventos
- Forzar una interrupción del servicio
- Solucionar problemas