Cache d’hôte local
Pour vous assurer que la base de données du site Citrix Virtual Apps and Desktops est toujours disponible, Citrix recommande de commencer par un déploiement SQL Server ayant une tolérance aux pannes en suivant la haute disponibilité des meilleures pratiques de Microsoft. (Pour les fonctionnalités de haute disponibilité prises en charge par SQL Server, consultez Bases de données.) Toutefois, les utilisateurs peuvent ne pas être en mesure de se connecter à leurs applications ou bureaux à cause de problèmes et d’interruptions réseau.
La fonctionnalité Cache d’hôte local permet aux opérations de négociation de connexions sur un site de se poursuivre en cas de panne. Une panne se produit lorsque la connexion entre un Delivery Controller™ et la base de données du site échoue dans un environnement Citrix® local. Le cache de l’hôte local est activé lorsque la base de données du site est inaccessible pendant 90 secondes.
À partir de XenApp et XenDesktop version 7.16, la fonction de location de connexion (fonctionnalité de haute disponibilité dans les versions antérieures) a été supprimée du produit et n’est plus disponible.
Contenu des données
Le cache d’hôte local inclut les informations suivantes, qui constituent un sous-ensemble des informations de la base de données principale :
- Identités des utilisateurs et des groupes auxquels sont attribués des droits sur les ressources publiées à partir du site.
- Identités des utilisateurs qui utilisent actuellement ou ont récemment utilisé des ressources publiées à partir du site.
- Identités des machines VDA (y compris les machines Remote PC Access) configurées sur le site.
- Identités (noms et adresses IP) des machines Citrix Receiver™ utilisées activement pour se connecter aux ressources publiées.
Il contient également des informations sur les connexions actuellement actives qui ont été établies alors que la base de données principale était indisponible :
- Résultats de toute analyse de point de terminaison de machine client réalisée par Citrix Receiver.
- Identités des machines d’infrastructure (telles que les serveurs NetScaler Gateway et StoreFront™) impliquées dans le site.
- Dates/heures et types d’activités récentes des utilisateurs.
Fonctionnement
Le graphique suivant illustre les composants et les chemins de communication du cache d’hôte local en fonctionnement normal.
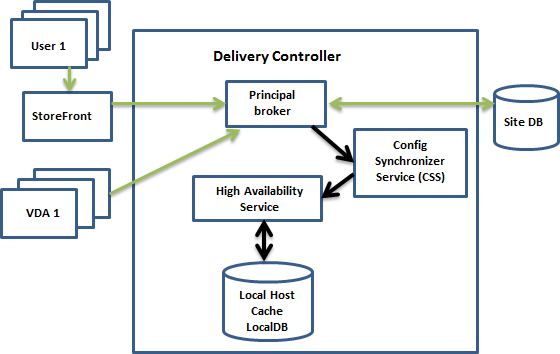
En mode de fonctionnement normal
- Le broker principal (Citrix Broker Service) sur un Controller accepte les demandes de connexion provenant de StoreFront. Le broker communique avec la base de données du site pour connecter les utilisateurs aux VDA qui sont enregistrés auprès du Controller.
- Citrix Config Synchronizer Service (CSS) interroge le broker environ toutes les 5 minutes pour savoir si des modifications ont été apportées. Ces modifications peuvent avoir été initiées par un administrateur (telles que la modification d’une propriété de groupe de mise à disposition) ou être des actions du système (telles que les attributions de machine).
-
Si la configuration a été modifiée depuis la dernière vérification, le service CSS synchronise (copie) les informations sur un broker secondaire sur le Controller. (le broker secondaire est également connu sous le nom de service de haute disponibilité.)
Toutes les données de configuration sont copiées, et pas seulement les éléments qui ont été modifiés depuis la dernière vérification. Le CSS importe les données de configuration dans une base de données Microsoft SQL Server Express LocalDB sur le Controller. Cette base de données est appelée base de données du cache d’hôte local. Le service CSS s’assure que les informations de la base de données du cache d’hôte local du broker secondaire correspondent aux informations de la base de données du site. La base de données du cache d’hôte local est recréée chaque fois que la synchronisation se produit.
Microsoft SQL Server Express LocalDB (utilisé par la base de données du cache d’hôte local) est installé automatiquement lorsque vous installez un Controller (Vous pouvez interdire cette installation lors de l’installation d’un Controller à partir de la ligne de commandes.) La base de données du cache d’hôte local ne peut pas être partagée sur des Controller. Vous n’avez pas besoin de sauvegarder la base de données du cache d’hôte local. Elle est recréée chaque fois qu’une modification de la configuration est détectée.
- Si aucune modification n’a été apportée depuis la dernière vérification, aucune donnée n’est copiée.
Le graphique suivant illustre les modifications apportées aux chemins de communication si le broker principal perd le contact avec la base de données du site (une panne commence).
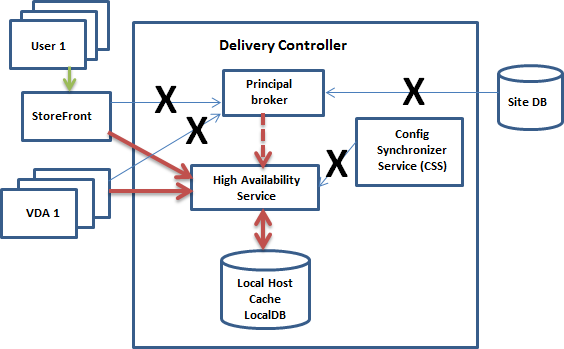
Durant une panne
Lorsqu’une panne commence :
- Le broker secondaire démarre l’écoute et traite les demandes de connexion.
- Lorsque la panne commence, le broker secondaire ne dispose pas des données d’enregistrement de VDA, mais lorsqu’un VDA communique avec lui, un processus d’enregistrement est déclenché. Au cours de ce processus, le broker secondaire obtient également des informations de session sur ce VDA.
- Bien que le broker secondaire gère les connexions, le broker principal continue à surveiller la connexion. Lorsque la connexion est rétablie, le broker principal demande au broker secondaire d’arrêter l’écoute des informations de connexion, et le broker principal reprend les opérations de négociation de connexion. La prochaine fois qu’un VDA communique avec le broker principal, un processus d’enregistrement est déclenché. Le broker secondaire supprime les enregistrements de VDA restants de la panne précédente. Le service CSS reprend la synchronisation des informations lorsqu’il détecte des modifications de la configuration dans le déploiement.
Dans le cas peu probable où une panne démarre pendant une synchronisation, l’importation en cours est annulée et la dernière configuration connue est utilisée.
Le journal d’événements contient des informations sur les synchronisations et les pannes.
Aucun délai n’est imposé pour le fonctionnement en mode panne.
La transition entre le mode normal et le mode panne n’affecte pas les sessions existantes. Elle n’affecte que le lancement de nouvelles sessions.
Vous pouvez également déclencher intentionnellement une panne. Voir Forcer une panne pour savoir quand cela peut être nécessaire et comment procéder.
Sites disposant de plusieurs Controller
Parmi ses différentes tâches, le service CSS fournit régulièrement au broker secondaire des informations sur tous les Controller de la zone (Si votre déploiement ne contient pas plusieurs zones, cette action affecte tous les Controller du site.) Ces informations permettent à chaque broker secondaire de connaître tous les brokers secondaires homologues qui s’exécutent sur d’autres Controller dans la zone.
Les brokers secondaires communiquent entre eux sur un canal distinct. Ces brokers utilisent une liste alphabétique des noms de domaine complet (FQDN) des machines qu’ils exécutent pour déterminer (sélectionner) le broker secondaire qui sera en charge des opérations de négociation dans la zone si une panne se produit. Durant la panne, tous les VDA s’enregistrent auprès du broker secondaire sélectionné. Les brokers secondaires non sélectionnés dans la zone rejettent activement les requêtes de connexion et d’enregistrement de VDA entrantes.
Si un broker secondaire sélectionné échoue lors d’une panne, un autre broker secondaire est sélectionné pour prendre le relais et les VDA s’enregistrent auprès du broker secondaire qui vient d’être sélectionné.
Durant une panne, si un Controller est redémarré :
- Si ce Controller n’est pas le broker sélectionné, le redémarrage n’a aucun impact.
- Si ce Controller est le broker sélectionné, un autre Controller est sélectionné, et par conséquent le VDA s’enregistre. Une fois que le Controller redémarré est sous tension, il reprend automatiquement la négociation des connexions, et le VDA s’enregistre. Dans ce scénario, les performances peuvent être affectées lors des enregistrements.
Si vous mettez un Controller hors tension en fonctionnement normal et le remettez sous tension durant une panne, le cache d’hôte local ne peut pas être utilisé sur ce Controller s’il est sélectionné en tant que broker.
Le journal d’événements contient des informations sur les sélections.
Fonctionnalités indisponibles durant une panne et autres différences
Aucun délai n’est imposé pour le fonctionnement en mode panne. Toutefois, Citrix recommande de restaurer la connectivité le plus rapidement possible.
Durant une panne :
- Vous ne pouvez pas utiliser Studio.
-
Vous avez un accès limité au SDK PowerShell.
- Vous devez d’abord :
- Ajoutez une clé de registre
EnableCssTestModeavec une valeur de 1 :New-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer\LHC -Name EnableCssTestMode -PropertyType DWORD -Value 1 - Utilisez le port 89 :
Get-BrokerMachine -AdminAddress localhost:89 | Select MachineName, ControllerDNSName, DesktopGroupName, RegistrationState
- Ajoutez une clé de registre
- Après avoir exécuté ces commandes, vous pouvez accéder à :
- Tous les applets de commande
Get-Broker*.
- Tous les applets de commande
- Vous devez d’abord :
- Les informations d’identification de l’hyperviseur ne peuvent pas être obtenues depuis Host Service. Toutes les machines se trouvent dans un état d’alimentation inconnu et aucune opération d’alimentation ne peut être émise. Toutefois, les machine virtuelle de l’hôte qui sont sous tension peuvent être utilisées pour les demandes de connexion.
- Une machine attribuée peut uniquement être utilisée si l’attribution s’est produite lors d’un fonctionnement normal. De nouvelles attributions ne peuvent pas être effectuées lors d’une panne.
- L’inscription et la configuration automatiques de machines Remote PC Access ne sont pas possibles. Toutefois, les machines qui ont été inscrites et configurées lors du fonctionnement normal peuvent être utilisées.
- Les utilisateurs d’applications et de bureaux hébergés sur le serveur peuvent utiliser plus de sessions que leurs limites de session configurées, si les ressources se trouvent dans des zones différentes.
- Les utilisateurs peuvent lancer des applications et bureaux uniquement à partir de VDA enregistrés dans la zone contenant le broker secondaire actuellement actif/sélectionné. Les lancements entre zones (depuis un broker secondaire dans une zone vers un VDA situé dans une autre zone) ne sont pas pris en charge durant une panne.
- Si une panne de base de données de site se produit avant le début d’un redémarrage programmé pour les VDA d’un groupe de mise à disposition, les redémarrages commencent à la fin de la panne. Cela peut donner des résultats inattendus. Pour plus d’informations, voir Redémarrages programmés retardés en raison d’une panne de la basede données.
- La préférence de zone ne peut pas être configurée. Si elle est configurée, les préférences ne sont pas prises en compte pour le lancement de la session.
- Les restrictions de balises dans lesquelles des balises sont utilisées pour désigner des zones ne sont pas prises en charge pour les lancements de session. Lorsque de telles restrictions de balises sont configurées et que l’option Contrôle avancé de l’état d’un magasin StoreFront est activée, le lancement des sessions peut échouer par intermittence.
Prise en charge des applications et des bureaux
Le mode LHC prend en charge les types de VDA et les modèles de mise à disposition suivants :
| Type de VDA | Modèle de mise à disposition | Disponibilité du VDA pendant les événements LHC |
|---|---|---|
| OS multi-session | Applications et bureaux | Toujours disponible. |
| Système d’exploitation monosession statique (attribué) | Bureaux | Toujours disponible. |
| Système d’exploitation mono-session à alimentation gérée aléatoire (regroupé)
|
Bureaux
|
Non disponible par défaut. Toutes les tentatives de lancement de session sur des VDA à alimentation gérée appartenant à des groupes de mise à disposition échoueront par défaut.
Vous pouvez les rendre disponibles pour de nouvelles connexions pendant les événements LHC. Pour plus d’informations, consultez Activer à l’aide de Web Studio et Activer à l’aide de PowerShell. Important :l’activation de l’accès à des machines mono-session regroupées à alimentation gérée peut entraîner la présence de données et de modifications issues des sessions utilisateur précédentes dans les sessions suivantes. |
Remarque :
L’activation de l’accès aux VDA de bureau à alimentation gérée appartenant à des groupes de mise à disposition n’affecte pas le fonctionnement de la propriété
ShutdownDesktopsAfterUseconfigurée pendant les opérations normales. Lorsque l’accès à ces bureaux pendant un événement LHC est activé, les VDA ne redémarrent pas automatiquement une fois l’événement LHC terminé. Les VDA de bureau à alimentation gérée et appartenant à des groupes de mise à disposition mis en pool peuvent conserver les données des sessions précédentes jusqu’au redémarrage du VDA. Un redémarrage du VDA peut se produire lorsqu’un utilisateur ferme sa session pendant des opérations autres que le LHC ou lorsque les administrateurs redémarrent le VDA.
Activer le mode LHC pour les VDA à OS mono-session et alimentation gérée regroupés à l’aide de Web Studio
À l’aide de Web Studio, vous pouvez rendre ces machines disponibles pour de nouvelles connexions pendant les événements LHC, selon le groupe de mise à disposition :
- Pour activer cette fonctionnalité lors de la création de groupes de mise à disposition, consultez Créer des groupes de mise à disposition.
- Pour activer cette fonctionnalité pour un groupe de mise à disposition existant, consulter Gérer les groupes de mise à disposition.
Remarque :
Ce paramètre n’est disponible dans Web Studio que pour les groupes de mise à disposition de bureaux regroupés qui fournissent des VDA à alimentation gérée.
Activer le mode LHC pour les VDA à OS mono-session et alimentation gérée mis en pool à l’aide de PowerShell
Pour activer le mode LHC pour des VDA appartenant à un groupe de mise à disposition spécifique, procédez comme suit :
-
Activez cette fonctionnalité au niveau du site en exécutant cette commande :
Set-BrokerSite -ReuseMachinesWithoutShutdownInOutageAllowed $true -
Activez le mode LHC pour un groupe de mise à disposition en exécutant cette commande avec le nom du groupe de mise à disposition spécifié comme suit :
Set-BrokerDesktopGroup -Name "name" -ReuseMachinesWithoutShutdownInOutage $true
Pour modifier la disponibilité par défaut du mode LHC pour les groupes de mise à disposition mis en pool récemment créés avec des VDA à alimentation gérée, exécutez la commande suivante :
Set-BrokerSite -DefaultReuseMachinesWithoutShutdownInOutage $true
Considérations sur la taille de la RAM
Le service LocalDB peut utiliser environ 1,2 Go de RAM (jusqu’à 1 Go pour le cache de base de données, plus 200 Mo pour l’exécution de SQL Server Express LocalDB). Le broker secondaire peut utiliser jusqu’à 1 Go de RAM si une panne dure longtemps avec un grand nombre d’ouvertures de session (par exemple, 12 heures avec 10 000 utilisateurs). Ces exigences de mémoire s’ajoutent aux exigences de RAM requises normalement pour le Controller, il se peut donc que vous deviez augmenter la quantité totale de capacité RAM.
Si vous utilisez une installation SQL Server Express pour la base de données du site, le serveur aura deux processus sqlserver.exe.
Considérations sur la configuration des sockets et des cœurs d’UC
Une configuration d’UC de Controller, notamment le nombre de cœurs disponibles pour SQL Server Express LocalDB, affecte directement les performances de cache d’hôte local, encore plus que l’allocation de mémoire. Cette charge de l’UC est observée uniquement au cours de la période de panne lorsque la base de données ne peut pas être contactée et que le service de broker secondaire est actif.
Bien que la base de données LocalDB puisse utiliser plusieurs cœurs (jusqu’à 4), elle est limitée à un seul socket. L’ajout de sockets ne permet pas d’améliorer les performances (par exemple, 4 sockets avec 1 cœur chacun). Citrix vous recommande plutôt d’utiliser plusieurs sockets avec plusieurs cœurs. Au cours des tests Citrix, une configuration 2x3 (2 sockets, 3 cœurs) a fourni de meilleures performances que les configurations 4x1 et 6x1.
Considérations sur le stockage
Lorsque les utilisateurs accèdent à des ressources pendant une panne, la taille de la base de données LocalDB augmente. Par exemple, lors d’un test d’ouverture/fermeture de session avec 10 ouvertures de session par seconde, la base de données a augmenté d’1 Mo toutes les 2-3 minutes. Lorsque le fonctionnement normal reprend, la base de données locale est recréée et l’espace disque est rétabli. Toutefois, le disque sur lequel la base de données LocalDB est installée doit avoir suffisamment d’espace pour permettre à la taille de la base de données d’augmenter durant une panne. Le cache d’hôte local entraîne également des E/S supplémentaires pendant une panne : environ 3 Mo d’écritures par seconde, avec plusieurs centaines de milliers de lectures.
Considérations sur les performances
Durant une panne, un seul broker secondaire gère toutes les connexions ; dans les sites (ou zones) qui équilibrent la charge entre plusieurs Controller en fonctionnement normal, le broker secondaire sélectionné peut être amené à prendre en charge beaucoup plus de requêtes que d’habitude durant une panne. Par conséquent, les demandes d’UC seront plus nombreuses. Chaque broker secondaire du site (zone) doit être en mesure de gérer la charge supplémentaire imposée par la base de données du cache hôte local et tous les VDA concernés, car le broker secondaire sélectionné lors d’une panne peut changer.
Limites de VDI :
- Dans un déploiement VDI à zone unique, jusqu’à 10 000 VDA peuvent être gérés efficacement au cours d’une panne.
- Dans un déploiement VDI multizone, jusqu’à 10 000 VDA par zone peuvent être gérés au cours d’une panne, avec un maximum de 40 000 VDA sur le site. Par exemple, chacun des sites suivants peut être géré de manière efficace durant une panne :
- Un site avec quatre zones, chacune contenant 10 000 VDA.
- Un site avec sept zones, une contenant 10 000 VDA et six contenant 5 000 VDA chacune.
Durant une panne, la gestion de la charge pour l’ensemble du site peut être affectée. Les calculateurs de charge (et plus particulièrement les règles du nombre de sessions) peuvent être dépassés.
Pendant que tous les VDA s’enregistrent avec un broker secondaire, il est possible que ce service ne dispose pas d’informations complètes sur les sessions en cours. Par conséquent, une demande de connexion d’un utilisateur pendant cet intervalle peut entraîner le démarrage d’une nouvelle session, même si la reconnexion à une session existante est possible. Cet intervalle (pendant lequel le nouveau broker secondaire reçoit les informations de session depuis tous les VDA dans le cadre du ré-enregistrement) est inévitable. Les sessions qui sont connectées lorsqu’une panne démarre ne sont pas affectées lors de l’intervalle de transition, mais les nouvelles sessions et les reconnexions de session peuvent l’être.
Cet intervalle se produit lorsque les VDA doivent s’enregistrer :
- Une panne démarre : lors de la migration depuis un broker principal vers un broker secondaire.
- Défaillance du broker secondaire durant une panne : lors de la migration depuis un broker secondaire qui a échoué vers un nouveau broker secondaire.
- Reprise après une panne : lorsque les opérations normales reprennent, et que le broker principal reprend le contrôle.
Vous pouvez réduire cet intervalle en réduisant la valeur de registre HeartbeatPeriodMs de Citrix Broker Protocol (valeur par défaut=600000 ms, c’est-à-dire 10 minutes). Cette valeur de pulsation est le double de l’intervalle que le VDA utilise pour les pings, donc la valeur par défaut entraîne un ping toutes les 5 minutes.
Par exemple, la commande suivante règle la pulsation sur cinq minutes (300000 millisecondes), ce qui entraîne un ping toutes les 2,5 minutes :
New-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer -Name HeartbeatPeriodMs -PropertyType DWORD –Value 300000
Soyez prudent lorsque vous modifiez la valeur de pulsation. L’augmentation de la fréquence entraîne une plus grande charge sur les Controllers pendant le mode normal et le mode panne.
L’intervalle ne peut pas être entièrement éliminé, quelle que soit la rapidité avec laquelle les VDA s’enregistrent.
Le temps nécessaire à la synchronisation entre les brokers secondaires augmente avec le nombre d’objets (VDA, applications, groupes) Par exemple, la synchronisation de 5 000 VDA peut prendre plus de dix minutes.
Différences par rapport aux versions XenApp 6.x
Bien que cette implémentation du cache d’hôte local porte le même nom que la fonctionnalité de cache d’hôte local dans XenApp 6.x et les versions antérieures de XenApp, d’importantes améliorations y ont été apportées. Cette implémentation est plus solide et plus résistante à la corruption des données. Les besoins de maintenance ont été réduits, par exemple le besoin de commandes dsmaint périodiques a été éliminé. Ce cache d’hôte local est une implémentation complètement différente sur le plan technique.
Gérer le cache d’hôte local
Pour que le cache d’hôte local fonctionne correctement, la stratégie d’exécution de PowerShell sur chaque Controller doit être définie sur RemoteSigned, Unrestricted ou Bypass.
SQL Server Express LocalDB
Le logiciel de base de données Microsoft SQL Server Express LocalDB que le cache d’hôte local utilise est installée automatiquement lorsque vous installez un Controller ou mettez à niveau un Controller à partir d’une version antérieure à la version 7.9. Seul le broker secondaire communique avec cette base de données. Vous ne pouvez pas utiliser les applets de commande PowerShell pour modifier quoi que ce soit dans cette base de données. La base de données LocalDB ne peut pas être partagée entre les Controllers.
Le logiciel de la base de données SQL Server Express LocalDB est installé que le cache d’hôte local soit activé ou non.
Pour empêcher son installation, installez ou mettez à niveau le Delivery Controller à l’aide de la commande XenDesktopServerSetup.exe et ajoutez l’option /exclude "Local Host Cache Storage (LocalDB)". Cependant, n’oubliez pas que la fonctionnalité de cache d’hôte local ne fonctionnera pas sans la base de données, et vous ne pouvez pas utiliser une autre base de données avec le broker secondaire.
L’installation de cette base de données LocalDB ne détermine pas si vous devez installer SQL Server Express ou non pour l’utiliser en tant que base de données du site.
Pour plus d’informations sur le remplacement d’une version antérieure de SQL Server Express LocalDB par une version plus récente, consultez la section Remplacer SQL Server Express LocalDB.
Paramètres par défaut après l’installation et la mise à niveau du produit
Lors d’une nouvelle installation de Citrix Virtual Apps and Desktops (version 7.16 au minimum), le cache d’hôte local est activé.
Après une mise à niveau (vers la version 7.16 ou ultérieure), le cache d’hôte local est activé s’il y a moins de 10 000 VDA dans le déploiement entier.
Activer/désactiver le cache d’hôte local
-
Pour activer le cache d’hôte local, entrez :
Set-BrokerSite -LocalHostCacheEnabled $truePour déterminer si le cache d’hôte local est activé, entrez
Get-BrokerSite. Vérifiez que la propriétéLocalHostCacheEnabledestTrue. -
Pour désactiver le cache d’hôte local, entrez :
Set-BrokerSite -LocalHostCacheEnabled $false
Rappel : à partir de XenApp and XenDesktop 7.16, la location de connexion (fonctionnalité antérieure au cache d’hôte local à partir de la version 7.6) a été supprimée du produit et n’est plus disponible.
Vérifier que le cache d’hôte local fonctionne
Pour vérifier que le cache d’hôte local est configuré et fonctionne correctement :
- Assurez-vous que les importations de synchronisation se déroulent correctement. Vérifiez les journaux d’événements.
- Assurez-vous que la base de données LocalDB SQL Server Express a été créée sur chaque Delivery Controller. Cela confirme que le broker secondaire peut prendre le relais, si nécessaire.
- Sur le serveur Delivery Controller, accédez à
C:\Windows\ServiceProfiles\NetworkService. - Vérifiez que
HaDatabaseName.mdfetHaDatabaseName_log.ldfsont créés.
- Sur le serveur Delivery Controller, accédez à
- Forcez une panne sur les Delivery Controller. Après avoir vérifié que le cache d’hôte local fonctionne, n’oubliez pas de remettre tous les Controller en mode normal. Cela peut prendre environ 15 minutes.
Journaux d’événements
Les journaux d’événements consignent les synchronisations et les pannes. Dans les journaux de l’observateur d’événements, le mode panne est appelé mode HA.*
Config Synchronizer Service :
Pendant une opération normale, les événements suivants peuvent se produire lorsque le CSS importe les données de configuration dans la base de données Cache hôte local à l’aide du broker Cache hôte local.
- 503 : Citrix Config Sync Service a reçu une configuration mise à jour. Cet événement indique le début du processus de synchronisation.
- 504 : Citrix Config Sync Service a importé une configuration mise à jour. L’importation de la configuration s’est terminée avec succès.
- 505 : Échec d’une importation par Citrix Config Sync Service. L’importation de la configuration n’a pas réussi. Si une configuration précédente réussie est disponible, elle est utilisée en cas de panne. Cependant, elle sera obsolète à partir de la configuration actuelle. Si aucune configuration précédente n’est disponible, le service ne peut pas participer à l’intermédiation de session pendant une panne. Dans ce cas, consultez la section Dépannage et contactez le support Citrix.
- 507 : Citrix Config Sync Service a abandonné une importation car le système est en mode d’arrêt et le broker Cache d’hôte local est utilisé pour la négociation de connexions. Le service a reçu une nouvelle configuration, mais l’importation a été abandonnée en raison d’une panne. Il s’agit du comportement attendu.
- 510 : Aucune donnée de configuration du service de configuration reçue depuis le service de configuration principal.
- 517 : Un problème s’est produit lors de la communication avec le broker principal.
- 518 : Le script Config Sync a été abandonné car le Broker secondaire (High Availability Service) n’est pas en cours d’exécution.
High Availability Service :
Ce service est également connu sous le nom de broker Cache d’hôte local.
- 3502 : une panne s’est produite et le broker Cache d’hôte local effectue des opérations de broker.
- 3503 : une panne a été résolue et le fonctionnement normal est rétabli.
- 3504 : indique le broker Cache d’hôte local qui a été sélectionné, ainsi que les autres brokers Cache d’hôte local impliqués dans la sélection.
- 3507 : fournit une mise à jour de l’état du cache d’hôte local toutes les 2 minutes, ce qui indique que le mode de cache d’hôte local est actif sur le broker sélectionné. Contient un résumé de la panne, notamment sa durée, l’enregistrement du VDA et les informations de session.
- 3508 : annonce que le cache d’hôte local n’est plus actif sur le broker sélectionné et que les opérations normales ont été rétablies. Contient un résumé de la panne, notamment sa durée, le nombre de machines enregistrées lors de l’événement de cache d’hôte local et le nombre de lancements réussis lors de l’événement.
- 3509 : indique que le cache d’hôte local est actif sur le ou les brokers non sélectionnés. Indique la durée de l’interruption toutes les 2 minutes, ainsi que le broker sélectionné.
- 3510 : Annonce que le cache d’hôte local n’est plus actif sur le ou les brokers non sélectionnés. Contient la durée de la panne et indique le broker sélectionné.
Forcer une interruption
Vous pouvez souhaiter délibérément forcer une interruption.
- Si votre réseau s’interrompt et reprend de manière répétée. Forcer une panne jusqu’à la résolution des problèmes réseau empêche le basculement en continu entre les modes de fonctionnement normal et de panne (et les fréquentes rafales d’enregistrements de VDA qui en résultent).
- Pour tester un plan de récupération d’urgence.
- Pour vous assurer que le cache d’hôte local fonctionne correctement.
- Lorsque vous remplacez ou effectuez une maintenance sur le serveur de base de données du site.
Pour forcer une panne, modifiez le registre de chaque serveur contenant un Delivery Controller. Dans HKLM\Software\Citrix\DesktopServer\LHC, créez OutageModeForced en tant que REG_DWORD et définissez-le sur 1. Ce réglage demande au broker de cache d’hôte local d’entrer en mode panne, quel que soit l’état de la base de données Si vous définissez la valeur sur 0, le broker Cache d’hôte local sort du mode d’interruption.
Pour vérifier les événements, surveillez le fichier journal Current_HighAvailabilityService dans C:\ProgramData\Citrix\WorkspaceCloud\Logs\Plugins\HighAvailabilityService.
Dépannage
Plusieurs outils de dépannage sont disponibles lorsque l’importation d’une synchronisation dans la base de données Cache d’hôte local échoue et qu’un événement 505 est signalé.
Traçage CDF : contient les options pour les modules ConfigSyncServer et BrokerLHC. Ces options, ainsi que d’autres modules de broker, sont susceptibles d’identifier le problème.
Rapport : en cas d’échec d’une importation de synchronisation, vous pouvez générer un rapport. Ce rapport s’arrête à l’objet qui a causé l’erreur. Cette fonctionnalité de rapport affecte la vitesse de synchronisation, Citrix vous recommande donc de la désactiver lorsqu’elle n’est pas utilisée.
Pour activer et générer un rapport de traçage CSS, entrez la commande suivante :
New-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer\LHC -Name EnableCssTraceMode -PropertyType DWORD -Value 1
Le rapport HTML est publié sous C:\Windows\ServiceProfiles\NetworkService\AppData\Local\Temp\CitrixBrokerConfigSyncReport.html.
Une fois le rapport généré, entrez la commande suivante pour désactiver la fonctionnalité de rapport :
Set-ItemProperty -Path HKLM:\SOFTWARE\Citrix\DesktopServer\LHC -Name EnableCssTraceMode -Value 0
Exporter la configuration du broker : fournit la configuration exacte à des fins de débogage.
Export-BrokerConfiguration | Out-File <file-pathname>
Par exemple, Export-BrokerConfiguration | Out-File C:\\BrokerConfig.xml.
Commandes PowerShell du cache d’hôte local
Vous pouvez gérer le cache d’hôte local (LHC ou Local Host Cache) sur vos Delivery Controller à l’aide des commandes PowerShell.
Le module PowerShell se trouve à l’emplacement suivant sur les Delivery Controller :
C:\Program Files\Citrix\Broker\Service\ControlScripts
Important :
Exécutez ce module uniquement sur les Delivery Controller.
Importer le module PowerShell
Pour importer le module, exécutez la commande suivante sur votre Delivery Controller.
cd C:\Program Files\Citrix\Broker\Service\ControlScripts
Import-Module .\HighAvailabilityServiceControl.psm1
Commandes PowerShell pour gérer le cache d’hôte local (LHC)
Les commandes suivantes vous aident à activer et à gérer le mode LHC sur les Delivery Controller.
| Applets de commande | Fonction |
|---|---|
Enable-LhcForcedOutageMode |
Permet de placer le broker en mode LHC. Les fichiers de base de données LHC doivent avoir été créés avec succès par le service ConfigSync pour que Enable-LhcForcedOutageMode fonctionne correctement. Cette applet de commande force uniquement le LHC sur le Delivery Controller sur lequel il a été exécuté. Pour que le LHC soit actif, cette commande doit être exécutée sur tous les Delivery Controller de la zone. |
Disable-LhcForcedOutageMode |
Permet de faire sortir le broker du mode LHC. Cet applet de commande désactive uniquement le mode LHC sur le Delivery Controller sur lequel il a été exécuté. Disable-LhcForcedOutageMode doit être exécuté sur tous les Delivery Controller de la zone. |
Set-LhcConfigSyncIntervalOverride |
Permet de définir l’intervalle auquel Citrix Config Synchronizer Service (CSS) vérifie les modifications de configuration sur le site. L’intervalle de temps peut aller de 60 secondes (une minute) à 3 600 secondes (une heure). Ce paramètre s’applique uniquement au Delivery Controller sur lequel il a été exécuté. Pour des raisons de cohérence entre les Delivery Controller, pensez à exécuter cette applet de commande sur chaque Delivery Controller. Par exemple : Set-LHCConfigSyncIntervalOverride -Sseconds 1200
|
Clear-LhcConfigSyncIntervalOverride |
Pemet de définir l’intervalle auquel Citrix Config Synchronizer Service (CSS) vérifie les modifications de configuration sur le site, à la valeur par défaut de 300 secondes (cinq minutes). Ce paramètre s’applique uniquement au Delivery Controller sur lequel il a été exécuté. Pour des raisons de cohérence entre les Delivery Controller, pensez à exécuter cette applet de commande sur chaque Delivery Controller. |
Enable-LhcHighAvailabilitySDK |
Permet l’accès à tous les applets de commande Get-Broker* au sein du Delivery Controller sur lequel il a été exécuté. |
Disable-LhcHighAvailabilitySDK |
Permet de désactiver l’accès aux applets de commande du broker dans le Delivery Controller sur lequel il a été exécuté. |
Remarque :
- Utilisez le port 89 lors de l’exécution des applets de commande
Get-Broker*sur le Delivery Controller. Par exemple :
Get-BrokerMachine -AdminAddress localhost:89- Lorsqu’il n’est pas en mode LHC, le broker LHC du Delivery Controller ne contient que les informations de configuration.
- En mode LHC, le broker LHC du Delivery Controller sélectionné contient les informations suivantes :
- États des ressources
- Détails de la session
- Enregistrements de VDA
- Informations de configuration