Citrix Virtual Apps and Desktops™ 7 2511
About the release
This Citrix Virtual Apps and Desktops release includes new versions of the Windows Virtual Delivery Agents (VDAs) and new versions of several core components. You can:
-
Install or upgrade a site: Use the ISO for this release to install or upgrade core components and VDAs. Installing or upgrading to the latest version allows you to use the latest features.
-
Install or upgrade VDAs in an existing site: If you already have a deployment and aren’t ready to upgrade your core components, you can still use several of the latest HDX™ features by installing (or upgrading to) a new VDA. Upgrading only the VDAs can be helpful when you want to test enhancements in a non-production environment.
After upgrading your VDAs to this version, you do not need to update the machine catalog’s functional level. For more information, see VDA versions and functional levels.
For installation and upgrade instructions:
- If you are building a new site, follow the sequence in Install and configure.
- If you are upgrading a site, see Upgrade a deployment.
Delivery Controller
Automated LocalDB installation for Delivery Controller upgrades
When you upgrade Delivery Controller, the metainstaller automatically installs a latest supported SQL Server Express LocalDB version. This enhancement streamlines your upgrade process. It ensures compatibility for the Local Host Cache database without manual LocalDB installation. For more information, see Automatic update.
HDX
Devices
WIA Redirection enhancements
Admins no longer need to make any registry changes on the VDA to use WIA redirection. They only need to enable the WIA redirection policy setting in Studio.
USB diagnostics tool enhancements
USB Diagnostics Tool now supports both admins and domain users, with a new Recommendations section to flag configuration issues and suggest optimizations.
Improved keyboard and barcode input reliability for multi-hop sessions
This feature enhances input reliability for non-Windows clients operating in Scancode input mode and ensures key events are processed sequentially by the Windows VDA, eliminating character errors during RDP double-hop sessions and ensuring barcode scanners correctly render numbers instead of special characters.
Multimedia
Optimized overlay clipping for enhanced performance and user experience
The overlay clipping mechanism for multimedia optimization features, such as HDX Microsoft Teams Optimization and UCSDK Optimization, has been re-architected for enhanced performance and visual accuracy.
This enhancement provides a more seamless user experience by resolving visual glitches where application elements, such as menus or notifications, would incorrectly appear behind video content.
The new approach also replaces resource-intensive methods to significantly reduce CPU utilization on the VDA. For more details, see the feature reference for MTOP or feature reference for UCSDK
Single sign-on support for Browser Content Redirection
Browser Content Redirection now offers streamlined user experience with single sign-on support, enabling VDA-side authentication and cookie sharing. This enhancement eliminates redundant logins, boosting productivity by maintaining authentication and cookie persistence across BCR sessions, even after the BCR window is closed. This seamless experience further enhances security by ensuring authentication originates from the VDA, not the client.
For more information, see Browser Content Redirection documentation.
Server-side certificate validation for Browser Content Redirection
Browser Content Redirection is further enhanced with certificate validation support. When accessing a redirected website from the client, the client overlay browser may not trust the certificate from the server or the MitM proxy. In such cases, BCR can now validate the Host or Proxy certificates against the VDAs certificate store.
For more information, see Server-side certificate validation documentation.
Graphics
General HDX Graphics improvements
This release introduces significant improvements to HDX Graphics, which can notably decrease CPU, memory and bandwidth consumption on the VDA. In addition to the performance improvements, customers will also notice higher out-of-the-box image quality on LAN networks.
HDX Screen sharing for Director
HDX Screen sharing is available for shadowing using Citrix Director for Citrix Virtual Apps and Desktops on-premises installations and Citrix Monitor for Citrix Cloud deployments. HDX Screen sharing is the new method for shadowing and provides a native, low latency alternative to the current shadowing. HDX Screen sharing for Director is available for all VDAs, including non-domain joined and Entra ID joined VDAs.
HDX Screen sharing improvements
HDX Screen sharing improvements including configuration policies to control HDX Screen sharing port and timeouts.
Support for the AMD V710 GPUs
Added support for AMD v710 GPUs.
Seamless Applications
Seamless application improvements
Seamless applications now have support for Transparent Windows and dynamic window preview (Windows peek).
Windows Accessibility settings for Seamless applications
Windows Accessibility settings for seamless applications are now on by default for all seamless sessions.
HDX Connectivity
HDX Direct
New events have been added for logging additional HDX Direct status details for external users. For more details, see HDX Direct troubleshooting.
Virtual Delivery Agents (VDAs)
Generate custom script to install or upgrade VDA via command-line
Introducing a new feature for generating custom scripts to install or upgrade VDAs via the command line. Within the VDA installer UI, users can now create custom scripts for unattended installations or upgrades. This enhancement provides step-by-step guidance on configuring, saving, and executing these scripts with parameters such as the installer path and WebSocket token. This feature significantly improves automation and accuracy in deployment processes.
VDA Meta Installer Helper Tool
A new VDA metainstaller helper tool is now available to simplify and streamline VDA installation and troubleshooting. It assists with validating and generating SCCM task sequences, ensuring compatibility with VDA installation requirements. The tool also includes a log analyzer that reviews installation logs, highlights errors or warnings, and provides recommendations for resolution. With a simple MSI installation and easy-to-use interface, it helps IT admins deploy VDAs more efficiently and with fewer issues.
VDA Meta installer Changes
The Citrix Virtual Apps and Desktops 7 2511 introduces integrated installation of Citrix Device Trust, uberAgent, and Workspace Environment Management agent within the VDA, with flexible command-line options like /components and /exclude to customize installation, upgrade, or uninstallation of components such as Citrix Workspace app, Secure Access Client, and User Personalization Layer, while default behaviors and component selections vary between single-session and multi-session OS VDAs. For more information, see Install VDAs and Install using the command line
New Meta Installer for Single Session Core Service Virtual Delivery Agent
A new lightweight Single-Session VDA Meta Installer is now available for Windows 365 Cloud PC and Remote PC deployments. This installer is built on the existing Remote PC installer and serves as a streamlined version of the full Single-Session VDA, delivering essential VDA components along with Profile Management, deviceTRUST, uberAgent, WEM, Backup and Restore, and the VDA Upgrade Agent. It significantly reduces package size and improves installation reliability for cloud-based workloads. Designed for modern Remote PC scenarios, this installer provides a simplified and high-performance option for deploying Citrix workloads on Windows 365 and Remote PC.
Citrix Always on Tracing
Citrix AOT for all CVAD components
The latest update introduces a major expansion of Always-On Tracing (AOT), making it easier to collect, centralize, and analyze logs across the entire Citrix environment. A new configuration experience in Web Studio lets admins define the log server, control the logging scope, and enable Director access from one place, with all settings automatically propagated through the Site database. Director now includes a dedicated Logs view, giving admins real-time visibility into AOT events with search, time filters, categories, severity filters, and machine-level filtering. AOT coverage has been extended to more Citrix components, including all core components with Mac VDAs, Linux VDAs, FAS, and Session Recording Server and more, enabling true end-to-end tracing across control and data plane workflows.
The AOT Log Server has been enhanced with better ingest performance, support for up to 10,000 components per node, and improved compression using LZ4 for more efficient storage. New sizing guidance and performance baselines help administrators plan capacity and tune storage and IOPS for their environment. Standalone components can now push logs to the log server through simple PowerShell commands, aligning them with the centralized logging model. Learn more and start your deployment here.
Web Studio
Provision workloads in AWS local zones
You can now provision Amazon Workspaces Core Managed Instances and EC2 workloads directly in AWS local zones. This new feature helps you to:
- Provide low-latency access for end-users by deploying Citrix workloads closer to them.
- Improve regional coverage for your Citrix infrastructure in areas not served by full AWS Regions.
You can create a host connection with a hosting unit in a desired local zone and then provision VMs in that local zone.
For more information, see:
- Amazon WorkSpaces Core Managed Instances:
-
AWS EC2:
Cross-account provisioning in AWS EC2 using Web Studio
There are use-cases where the Cloud Connectors would like to be placed in a separate AWS account (shared services account or site components account) with IAM roles that have cross-account access (cross-account IAM role) and MCS-provisioned machine catalogs in separate secondary AWS account (workloads accounts), without the need for additional Cloud Connectors in the separate accounts. Such a deployment model is already supported using PowerShell SDK, and is now also supported using the Web Studio UI.
Backup VM configuration in AWS EC2
Web Studio now enables you to define a list of backup EC2 instance types (“Backup SKUs” that can be On-demand or Spot instances) in AWS environments that Machine Creation Services (MCS) can fall back to in case of capacity-related issues. MCS tries to fall back on the backup EC2 instance types in the order that is provided by you in the list. For more information, see Create a catalog using Studio.
AWS EC2 security group configuration
When you use machine profiles for catalog creation or editing in Web Studio, the security group configuration process has been streamlined. You no longer manually configure security groups, and the dedicated configuration page is skipped, ensuring consistency with the machine profile’s settings. Existing workflows for non-machine profile-based catalogs remain unchanged. Furthermore, the tenancy type selection menu has been relocated from the Security tab to the Virtual Machine tab in the catalog creation wizard. For more information, see Create a catalog using Web Studio.
Share encrypted prepared image across regions in Azure
Azure Compute Gallery (ACG) images can be encrypted with a Disk Encryption Set (DES). With this feature, you can share an encrypted prepared ACG image across multiple regions in the same subscription and tenant using DES. You can thereafter create a machine catalog in the region where the encrypted prepared image is shared. For more information, see Share encrypted prepared images across regions, subscriptions, tenants.
Enable ZRS for MCS machine catalogs in Azure
You can now configure Zone redundant storage (ZRS) for disk configurations in your Azure MCS machine catalogs. This enhancement helps to:
- Improve the resiliency of your VMs against zone-level outages.
- Enable Azure to launch VMs in any available zone, enhancing VM placement flexibility.
- Overcome the limitations of Locally Redundant Storage (LRS) by ensuring VM availability even if the disk’s original zone is unavailable.
You can configure ZRS while creating and editing an existing Azure MCS machine catalog.
For more information, see:
Display NVMe v6 SKUs for ephemeral OSDisk usage
You now have the option to store an ephemeral OS disk on a NVMe Disk using Web Studio. For information see, Azure ephemeral disks.
Support for Image Management with Azure Confidential VMs using Web Studio
You can now use the Images node to prepare and manage images that are compatible with Azure Confidential VMs. You can also use PowerShell commands to achieve this goal. For more information, see Azure confidential VMs.
Option to select between Locally redundant storage type (LRS) or Zone-redundant storage type in Azure
Web Studio now allows you to select between Locally redundant storage (LRS) type and Zone-redundant storage (ZRS) types as a data recovery option during machine catalog creation. You can review the advantages provided by each of these redundancy storage types and select based on your requirements.
Integration with Nutanix Prism Central on AHV
You can now connect Citrix Virtual Apps and Desktops environments to Nutanix AHV clusters through Nutanix Prism Central using a new host connection, Nutanix AHV Prism Central.
The benefits of using Nutanix AHV Prism Central host connection are:
- Supports machine catalogs with both power managed only and MCS provisioned VDAs.
- Enables MCS master VM sharing across AHV clusters using template version.
- Simplifies certificate trust on host connection.
- Eliminates the need to separately install the plug-in on Delivery Controllers.
For more information, see:
- Nutanix virtualization environments
- Nutanix cloud and partner solutions
- Connection to Nutanix
- Connection to Nutanix cloud and partner solutions
- Create a Nutanix catalog
- Manage a Nutanix catalog
Provision Windows and Linux virtual machines on Azure Local
You can now provision and manage MCS machine catalogs and Citrix Provisioning catalogs using MCS for Windows and Linux VMs on Azure Local.
For Windows VMs, you can create and manage hosting connections and units, provision Windows 10/11 single-session and Windows Server multi-session VMs (both persistent and non-persistent). You can also update network, Write-back cache (WBC), or AD service account settings for new VMs after creation. This supports on-premises AD, non-domain joined, and Entra hybrid joined devices.
For Linux VMs, this feature supports Ubuntu, CentOS, Red Hat Enterprise, and SUSE. You can provision catalogs with these OS types, deploy persistent and non-persistent Linux VMs, integrate with on-premises AD or non-domain joined VMs for authentication, manage host units (including storage and network settings), perform configuration changes on newly provisioned VMs within a catalog.
For more information, see:
- Connection to Azure Local
- Create an Azure Local catalog
- Citrix Provisioning document: Create Citrix Provisioning™ catalogs in Citrix Studio
Managing prepared image versions in XenServer
Image management functionality is now generally available for XenServer virtualization environments. You can use Images node to create multiple image versions, and apply or update to multiple machine catalogs. This implementation significantly reduces the storage and time costs, and simplifies the VM deployment and image update process. You can also use PowerShell commands to achieve this goal. For more information, see Create a prepared image machine catalog in XenServer.
Add notes while assigning prepared images
With this feature, you can now add custom notes using Web Studio and PowerShell while creating or updating an MCS catalog with a prepared image. MCS keeps a record of all prepared image assignments. This helps you to:
- Retrieve the image assignments history of all the prepared images assigned to a catalog.
- Quickly roll back a machine catalog to a previously assigned prepared image using the Use previous image assignment for quick rollback action. Simply select a version from the history list for a quick and informed rollback. For information on rolling back, see Update a machine catalog with a different prepared image.
This feature is applicable to both Azure and VMware environments.
For information on creating a catalog with prepared images, see:
For information on updating a catalog with prepared images, see Manage prepared image machine catalogs.
Visualization of provisioning cost insight
You can now view detailed cost information for machine catalogs. The visualization provides an overview of provisioning costs and trends for the last 30 days.
The report breaks down provisioning costs based on individual catalogs, allowing for a clear understanding of how each category contributes to the overall cost. The report:
- displays the total cost incurred over the past 30 days.
- compares the current 30-day total cost with the previous 30-day period.
-
displays cost details of:
- Compute cost
- Storage cost
- Network cost
- Other cost
For more information, see View catalog details.
Re-trust option for untrusted host connection certificates
If a host connection outage occurs due to an untrusted certificate, you can re-trust the certificate for that host connection in Web Studio. For more information, see Test TLS certificate trust.
Custom schedule for holidays
Autoscale now allows you to create custom schedules to turn off unused VMs in a delivery group on specific days, like holidays, to reduce unnecessary resource consumption.
To create custom schedules:
- In Web Studio, go to Delivery Groups. Right-click a delivery group and select Manage Autoscale.
- On the Schedule page, click Create schedule.
For more information, see Create custom holiday schedules using Studio.
Machine hardware view in the Search node
You can now access a dedicated hardware view in the Search node for machines provisioned using Machine Creation Services (MCS). This view gives better visibility into machine hardware details and makes managing MCS-provisioned machines easier. Key benefits include:
- View detailed hardware configurations, including machine size, Operating System, license type, security settings, networking, image and template, and disk settings.
- Easily locate machines using hardware filters and search options.
Currently, Hardware view is available for MCS-provisioned machines in VMware, XenServer, SCVMM/Hyper-V, Nutanix PC, Azure, Azure Arc, Azure Local, AWS EC2, and GCP. OpenShift and Amazon WorkSpaces Core Managed Instances currently show basic hardware information as columns only. For more information, see Monitor MCS-provisioned machines in Search > Hardware view.
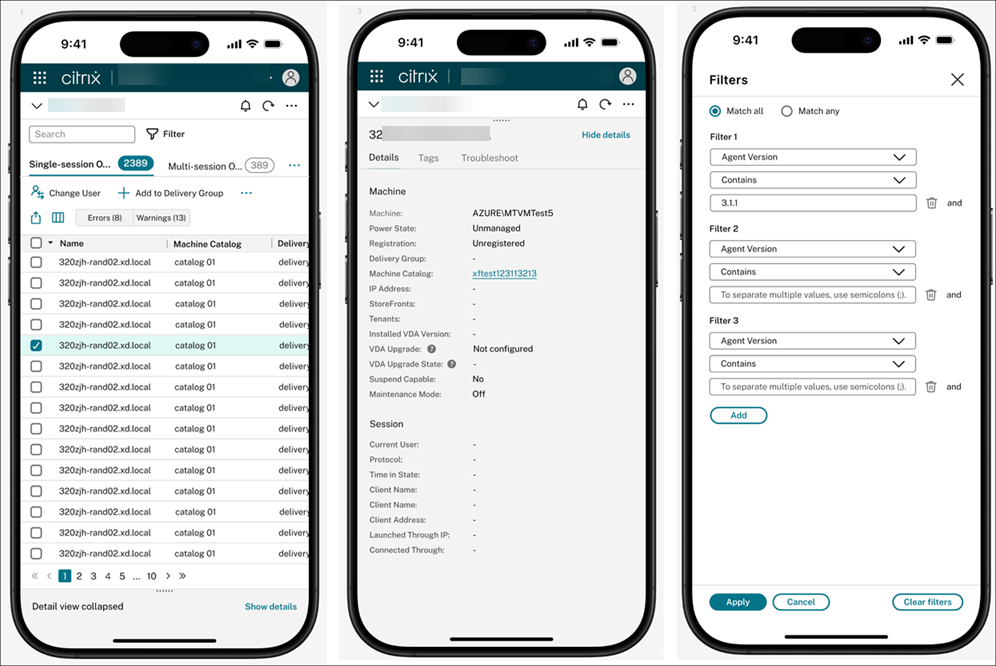
Enhanced mobile experience for critical on-the-go tasks
You can now manage Citrix Virtual Apps and Desktops deployment more easily from your mobile device. The updated experience is optimized for smaller screens, making it easier to access Studio from a mobile device when a desktop isn’t available. Whether you’re responding to an alert or quickly checking a misconfiguration, you can act right away—no need to wait until you’re back at your desk.
The mobile interface offers improved accessibility and is designed for touch-friendly interactions. Layouts and functionality might differ slightly from the desktop experience to better suit mobile workflows.
With a responsive layout and streamlined navigation, you can:
- Monitor your deployment’s health at a glance
- View details for machine catalogs and delivery groups
- Take key actions, such as restarting machines or disabling delivery groups
Estimate Azure VM costs during catalog creation
When creating a machine catalog, you can now estimate the monthly cost of Azure virtual machines, including VM size and disk costs. You can also refine the estimate by adjusting settings such as daily power-on hours, workdays, savings plans, reserved instances, and shutdown storage. This feature helps you plan deployments more efficiently and optimize costs early on.
For more information, see View monthly estimate details on the Summary page.
Site diagnostic tests for configuration health checks
You can now run site diagnostic tests from the Site details widget in Home. This feature helps you quickly assess the health of your Citrix Virtual Apps and Desktops environment and identify common configuration issues. Whether you’re troubleshooting performance problems or preparing for an upgrade, these tests provide fast, actionable insights. Typical issues detected include:
- Delivery Controller communication failures
- Database connectivity or configuration errors
This feature is especially useful during upgrades, helping ensure your site is stable and ready before and after deployment. For more information, see Site details.
Improved restart UI for clearer control and customization
We’ve enhanced the restart schedule UI to make restart modes clearer and more customizable. You can now easily distinguish between graceful restart and forced restart, and configure custom restart durations to suit your needs. To help you make informed choices, we’ve also added tooltips that explain key options—such as how forced restart can forcibly restart machines, even if sessions are unresponsive.
For more information, see Create a restart schedule.
New login page settings
The Settings node in Web Studio now includes two options to enhance the Web Studio login experience:
- Login page notice: Display a custom message to share important information with administrators.
- Show connected Delivery Controller: Display the FQDN of the connected Delivery Controller for added visibility and transparency.
For more information, see Settings.
Customize your Studio view with My preferences settings
A new My preferences tab is now available under the Settings node. Settings on this tab let you tailor your Studio interface to suit your preferences. These settings apply only to your account and don’t affect other administrators. You can configure the following options:
- Date and time: Set your default time zone, date format, and time format. These settings are used throughout Studio for time-related displays, such as scheduled restarts and autoscaling.
- Folder view: Choose whether to show or hide the folder view in the Machine Catalogs, Delivery Groups, and Applications nodes.
- Tab order in Search: Customize the tab order within the Search node.
For more information, see Settings.
Enhanced SQL Server connection settings
You can now configure three security settings for SQL Server connections: Encryption, Trust Server Certificate, and Host Name In Certificate. These settings offer greater flexibility and help enhance the security of database connections based on the requirements of your production environment. We’ve updated the following UIs to support this enhancement:
- Citrix Site Manager: Lets you configure these options when creating a site or changing database settings.
- Settings page in Web Studio: Lets you configure these options when changing database settings.
For more information, see Set up databases and Change database locations.
Web Studio installation flexibility
You can now install Web Studio on any IIS website with site ID = 1, regardless of the site name. This enhancement lets you host Web Studio under a custom IIS site instead of being limited to the Default Web Site.
If IIS isn’t installed when you run the installer, it’s automatically set up and Web Studio is deployed under the Default Web Site. If IIS is already installed, you can pre-create a site with your preferred name and path, as long as its site ID is 1.
For more information, see Install Web Studio.
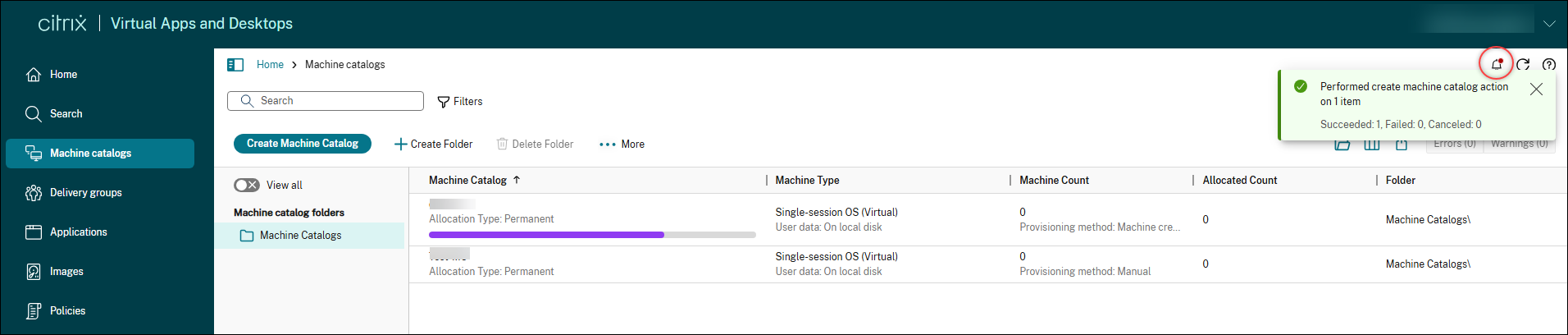
In-session notifications and background operations
Web Studio now includes a notification center that gives you real-time visibility into background operations and reports on operation results. When you start a time-consuming operation, a notification appears in the upper-right corner to let you know it’s in progress. Operations that previously blocked the UI now run in the background, so you can continue working without interruption. Once the operation completes, a real-time status notification appears, and the result is also saved in the notification center. The notification center maintains a 48-hour history, making it easy to track recent activity.
Studio always-on mode
Web Studio now introduces always-on mode to enhance resiliency and reduce downtime during infrastructure failures. In this read-only mode, you can securely view and monitor your Citrix Virtual Apps and Desktops environment even during service disruptions, helping maintain operational continuity. Always-on mode is available on all MANAGE nodes, except Quick Deploy. For more information, see this blog post.
Support for assigning Citrix Group Policies to Microsoft Entra ID users
You can now assign Citrix Group Policies to Microsoft Entra ID users from multiple IDPs in Studio. This enhancement gives you more flexibility when applying policies to specific user groups and simplifies deployments using Citrix Virtual Apps and Desktops with Windows 365.
Customize desktop icons across platforms
Web Studio now allows you to customize desktop icons for any desktop of your choice. Previously, all desktops used the default icon, and you couldn’t change it in Studio. You can now:
- Upload icons and use them for desktops or apps
- Change the icon for individual desktops
- Select from built-in icons for the desktops of your choice
For more information, see Create delivery groups and Manage delivery groups.
Support for more granular control over access policies in delivery groups
Previously, you could apply access policies to specific users only using PowerShell or REST APIs. Now, you can achieve this goal directly in Studio. This enhancement gives you more flexibility in defining different access conditions for various users or user groups, achieving more granular access control. For more information, see Configure user scope for an access policy.
Additionally, we’ve improved compatibility between Studio and the PowerShell or REST API approach. Previously, if you configured access policies with user scopes using PowerShell or REST APIs, the Users and Access Policies pages in Studio were blocked. Studio now fully supports these scenarios, offering clear information or UI guidance where necessary.
Support for exercising access control over apps at the delivery group level
Previously, within Studio, you could only exercise access control over apps at the individual app level, not at the delivery group level. Now, you can perform access control over apps at the delivery group level. Currently, this ability is limited to controlling access to all apps within a delivery group.
For more information, see Restrict application access to specific users.
Enhanced user assignment default for improved security
We’ve updated the default behavior when assigning users within a delivery group. Restricted control is now the default, ensuring better security and more granular access control. The alternative option, Allow any authenticated users to use resources, is now clearly marked as Not recommended, and must be used only for specific scenarios like shared or pooled desktops for broad access, kiosk environments, or testing purposes. This change helps reduce risk while giving you flexibility when needed.
For more information, see Configure user scope for an access policy.
Forward Always-on Tracing (AOT) logs to your log server
With Web Studio, you can now forward AOT logs from Citrix components to a designated log server. This feature enables centralized troubleshooting and advanced monitoring of your Citrix environment. For more information, see Settings.
Improved application package management
In Web Studio, you can now choose to automatically remove packages that are no longer present in the source location when checking for updates. This new Remove absent packages option in the Preferences field helps you easily clean up the application packages UI by removing outdated entries from the Packages tab. In addition, several tabs and sections in the App packages node have been renamed to better align with the wider suite of package types now supported in Studio:
- Add Source is now Create discovery profile
- Check for package updates is now Check for updates
- Remove source is now Delete profile
For more information, see Manage app packages.
Support for discovering and assigning Elastic App layers
You can now discover and publish Elastic App layers using the App packages node in Web Studio. With this feature, you can:
- Discover and enumerate a library of Elastic App layers authored using Citrix App Layering.
- Create assignment policies to deliver apps elastically to users on non-persistent machine catalogs.
- Deliver portable Elastic App layers to any non-persistent Windows machine, regardless of whether the image was published from an App Layering appliance.
For more information, see Elastic App applications.
Support for discovering and assigning Numecent Cloudpaging apps
You can now discover and publish Numecent Cloudpaging apps using the App packages node in Web Studio.
For more information, see Cloudpaging applications.
Support for controlling the visibility of packaged applications
With Web Studio, you can now control the visibility of a packaged application—on a desktop, on Citrix Workspace > Apps, or both. To change visibility for a specific packaged app, go to the Applications node, select the application, and choose Properties > Delivery. By default, packaged applications are delivered only on Citrix Workspace > Apps.
For more information, see Change application properties.
Support for automatically using Azure Temporary Disk for write-back cache disk
When you edit an MCS-provisioned catalog in Studio, the catalog now automatically uses Azure Temporary Disk for the write-back cache (WBC) disk if the required criteria are met. As a result, new VMs added to the catalog uses Azure Temporary Disk for the WBC disk. Previously, if a catalog didn’t qualify at creation, Azure Temp Disk wasn’t used for WBC disk—even if the catalog was later updated to meet the criteria. Benefits:
- Reduce costs. Temp Disks don’t incur storage costs when the VM is powered off.
- Improve flexibility. Use Temp Disks for WBC without recreating the catalog. An MCS-provisioned catalog automatically uses Azure Temp Disk for WBC disk when the catalog meets all the following criteria:
- MCSIO is enabled.
- The WBC disk is non-persistent.
- The VM size includes a Temp Disk large enough for the WBC disk.
- No drive letter is specified for the WBC disk.
For more information, see Create a Microsoft Azure catalog.
Citrix Director
Machine Diagnostic Insights
A new Machine Diagnostic Insights panel is now available in Citrix Director to help you proactively identify and troubleshoot session failures and performance issues. This feature introduces real-time insights refreshed every 15 minutes, highlighting problematic machines across the site.
Director integration with Citrix Virtual Apps and Desktops centralized log server for AOT
Director is integrated with Always On Tracing (AOT) as a foundational diagnostic capability. This enables continuous, low-overhead capture and analysis of critical VDA and session events.
Key capabilities include:
- View AOT logs: Access logs for various Citrix Virtual Apps and Desktops components, such as DDC, VDA, and StoreFront.
- Filter and search AOT logs: Retrieve AOT logs from specific time periods, with support for searching and filtering by Category, Log class, and Host name.
- Seamless integration with Director/Monitor: Easily transition from “Machine Filters,” “Session Launch Failure Diagnostics,” and “Activity Manager” in Director/Monitor to granular AOT log data for specific VDAs or sessions.
Multi-select support for key entities using “IN” operator
This enhancement introduces the ability to select multiple values for key filter fields such as users, machines, and delivery groups, utilizing an “IN” operator.
Multi-Select Support for delivery groups
The delivery group drop-downs in the Sessions and Logon Performance pages under the Trends tab are enhanced with:
- Search for Delivery Group names using text input
- Multi-select up to 15 Delivery Groups for comprehensive analysis
This enhancement improves usability and allows for more efficient monitoring and comparison across multiple delivery groups simultaneously.
Enhanced workload rightsizing
The enhanced workload rightsizing page helps you analyze the usage and sizing aspects of your delivery groups. Hereby, delivery groups can be analyzed based on machine or user activity. The machine-based analysis enables you to: Categorize virtual desktops based on usage to identify machines with no or low activity and reduce spending on unused resources. Analyze resource utilization on virtual desktops to identify machines that needs to be right-sized to reduce cost or improve user experience.
The user-based analysis enables you to:
- Categorize the users based on their activity. Consider removing the access entitlement of users with no activity for IT hygiene reasons. Users with low usage could be moved to shared resources for a more efficient use of resources.
- Analyze the resource consumption of users to identify cohorts with higher or lower than average resource consumption, to distribute users more effectively.
This analysis is ideal for scenarios with virtual desktops statically assigned to users, such as Windows 365 Enterprise or Frontline dedicated. You can also analyze delivery groups with randomly assigned virtual desktops or multi-session machines, though the analysis shows averages because users roam between these machines.
Note:
The classic rightsizing analysis, accessible through the All Workloads button at the top of the page, will be deprecated in an upcoming release.
Improved handling of vertical and horizontal load balancing alerts
Previously, when you set UseVerticalScalingForRdsLaunches to true and configured the “Maximum number of sessions” policy in Studio, machines moved to the “Maximum capacity” state. The Director triggered alerts for “Maximum capacity” whether the limit was reached due to vertical or horizontal load balancing. There was no way to distinguish between vertical and horizontal load balancing when encountering specific errors, such as “Max Load Reached.” This caused unnecessary alerts for expected behavior in vertical scaling scenarios, wasting your time and creating confusion.
Now, when vertical load balancing is active and a machine reaches its session limit, it moves to a new state: “Maximum capacity for vertical scaling.” The Director no longer generates alerts for this new state. Alerts only trigger for “Maximum capacity” in horizontal scaling scenarios. You can view the new state in the Filters and Custom reports pages, making it easier to distinguish between expected and exceptional conditions. This enhancement helps you avoid unnecessary alerts and focus on real issues, streamlining monitoring and troubleshooting. It applies when you configure UseVerticalScalingForRdsLaunches using Set-BrokerSite and set the “Maximum number of sessions” policy in Studio.
Map view of successful session launches
The Map view in Citrix Director provides administrators with a comprehensive geographical visualization of successful session launches across their Citrix environment. This feature visually maps user connections on a global scale, helping IT teams quickly identify regional performance patterns, troubleshoot geographical connectivity issues, and optimize the end-user experience based on location data. The map displays color-coded connection points that indicate logon performance across different geographical locations.
Extending Microsoft Teams Optimization (Slimcore) details to Citrix Workspace App for Mac
We are extending the visibility of Microsoft Teams Slimcore optimization to Mac endpoints running Citrix Workspace app (CWA) version 2508 and later. Previously limited to Windows endpoints, administrators using Director can now view and leverage this optimization for their Mac users, ensuring consistent performance insights across your environment.
Note:
The CWA Mac version must be at least 2508.
Session Failure Insights
Previously, you faced challenges understanding session failure reasons. You lacked detailed diagnostic insights into why user sessions failed. Now, with this feature, you receive comprehensive session failure diagnostic insights. You can detect error patterns and quickly identify top failure reasons. The system highlights failures impacting specific delivery groups or machines. You also gain visibility into blocked user connections. This improves your ability to troubleshoot and resolve session issues faster. This enhancement applies to your Monitor and Director services.
Session topology is now available for disconnected and ended sessions
The Session Topology view in Citrix Director now supports disconnected and ended sessions, displaying the topology of the last known state for comprehensive post-session analysis.
Extended Time Periods and Custom Date Range Added to Cost Savings
You can now view 90 days of cost savings data for power-managed machines, up from the previous limit of 45 days. We’ve also added a custom date picker, giving administrators more control and flexibility to scan and analyze savings over specific, extended time ranges.
View users blocked by session launch failures
Administrators now have visibility into users blocked by session launch failures. This new summary is available within the Filters under the Connections view, enabling improved prioritization and analysis of failures.
Visibility into Session Reconnect durations across users
The Session Reconnect Duration feature extends the existing Session Logon Duration functionality in Citrix Director to include metrics related to session reconnects. This enhancement provides administrators with visibility into reconnect performance trends, enabling better troubleshooting and optimization of user experience.
Ability to see the Unified Communication app metrics across user sessions
The Sessions view now includes several new display columns that provide detailed insights into Unified Communications (UC) application usage for a user session. These columns are: All UC apps name, UC app name, UC app optimization state, UC app plugin manager name, UC app plugin manager version, UC app plugin installed, UC app plugin version, UC app version, UC app plugin manager, UC app virtual channel state, and UC app virtual channel allow list. These attributes can be selected via the “Choose Columns” option to be shown in the main session table view.For more information, see Unified Communication app metrics
Enhanced delivery group selection in Trends
The Delivery Group drop-down is enhanced in the Sessions and Logon Performance pages under the Trends tab. You can now:
- Search for Delivery Group names using text input
- Multi-select up to 15 Delivery Groups for comprehensive analysis
This enhancement improves usability and allows for more efficient monitoring and comparison across multiple delivery groups simultaneously.
Remote Assistance with HDX Screen Share for Single-Session OS
Director now supports remote assistance leveraging native HDX screen sharing technology. This feature provides a secure, high-performance method for IT administrators and helpdesk teams to provide remote support to end users in single-session environments, complementing or replacing existing remote assistance methods.
Machine Creation Services™ (MCS)
Support for creating MCS machine catalogs in Amazon Workspaces Core Managed Instances
MCS has now integrated with Amazon Workspaces Core Managed Instances to provision persistent and non-persistent MCS machine catalogs in the customer’s AWS account.
With this feature:
- You can create a host connection to Amazon WorkSpaces Core Managed Instances.
- Create a prepared image and use the prepared image and machine profile to create a persistent or non-persistent MCS machine catalog.
- Share a single prepared image across different availability zones within the same or different AWS regions. Currently, you can share prepared image across different AWS regions using only PowerShell command.
Support for VMware vVols in MCS
You can now use VMware vVols with MCS on vSphere environments. Previously, creating MCS catalogs on vVols resulted in PBM errors. This update resolves that issue. This integration provides granular control over your MCS virtual machine storage. For information, see Storage Profile (vSAN).
Support for using AWS EC2 Spot instances
With this feature, you can create an MCS machine catalog of Spot instances (persistent request only) in AWS virtualization environment using machine profile workflow.
Compared to On-demand instances, Spot instances offer cost savings of up to 90%. However, Spot instances might be interrupted by Amazon EC2 if capacity becomes unavailable, making them suitable for non-critical applications and desktops only.
Additionally, with this feature, you can use Spot instances as backup SKUs.
For more information, see Create a catalog using AWS Spot instance.
Support for Azure Arc onboarding across all on-premises hypervisor
Azure Arc enables organizations to manage resources such as VMs hosted anywhere as if they are running in Azure. With Azure Arc, you can use Azure services such as Azure Monitor for comprehensive visibility and proactive management of the resources.
With this feature, you can now enable Azure Arc Onboarding for an MCS machine catalog using PowerShell commands. Once onboarded, the VMs can be managed from the Azure portal to perform operations such as power management, add or remove extensions, assign policies, and enable Azure Monitor on the Arc-enabled VMs through built-in Azure policy.
Currently, this feature is applicable to all Citrix on-premises hypervisors VMware, Nutanix, and SCVMM.
For more information, see Onboard VMs to Azure Arc.
Support for provisioning data disk on Azure
You can now create and assign a persistent data disk to an MCS created persistent or non-persistent VM of an MCS machine catalog in Azure. The data disk is used for storage of persistent data like event logs, security traces, and application data.
The data disk must be provisioned from the master image. The properties such as storage type, encryption settings, zones are derived from custom properties or from the OS disk template if the properties are not specified in the custom properties. For information on creating an MCS machine catalog with a data disk, see Provision data disk.
MCS maintains unique machine GUID
MCS provisioned Windows VMs on VDA version 2511 or later now retain a unique MachineGuid that remains consistent across reboots and image updates. This enhancement addresses issues where multiple VMs shared the same MachineGuid, impacting licensing and application registration.
Use WinHttp (netsh) proxy server settings for hosting connection
This feature allows hosting connections to use the WinHttp (netsh) proxy server settings configured on the DDC to be used with the hosting connection. For more information, see Use WinHttp (netsh) proxy server settings for hosting connection
Azure: Support cross-family backup VM sizes for hibernated VMs
MCS on Azure now supports using cross-family VM sizes for backup configurations in hibernation-enabled machine catalogs, improving resiliency. This feature removes the prior restriction that blocked cross-family fallback to prevent blue screen errors upon resume. When an allocation failure occurs while resuming a hibernated VM, MCS automatically handles the size change, ensuring you still get a working VM. Note that switching the VM size requires clearing the hibernated state, resulting in the loss of the VM’s memory state (RAM data). This functionality is available for both persistent and non-persistent MCS catalogs. For more information, see Configure backup VM sizes.
Azure: Clone MCS catalogs
You can now use the Copy-ProvScheme PowerShell command to clone an existing persistent and non-persistent MCS machine catalog in the Azure virtualization environment. This feature creates a new provisioning scheme by copying the details of an existing scheme, including associated configurations, network mappings, and security groups. This helps you to:
- Split an existing single catalog into multiple catalogs to apply different catalog-level policies and configurations.
- Isolate specific virtual machines within a large catalog for quick testing or to treat them separately based on functional roles.
For more information, see Clone an MCS catalog.
Autoscale™
Intelligent Autoscale
Intelligent Autoscale is a data driven Autoscale feature with minimum administrative settings that allows you to configure the performance target of a Delivery Group. The performance target value ranges from 1 to 99 and the value specifies a target balance between user experience and cost:
- A low value prioritizes cost savings.
- A high value prioritizes user experience.
The performance target, combined with historical usage data, calculates an optimal buffer capacity (the number of VMs to be powered on) for each 30-minute block of a day. Therefore, 48 optimal buffer capacities are computed at the start of each day.
The optimal buffer capacity replaces peak/off-peak buffer capacity and pool size to manage available machines.
For more information, see Intelligent Autoscale schedules plug-in.
Autoscale holiday plugin
With this feature, you can deviate from the standard Autoscale settings related to the power management of VMs and allow VMs to be powered off on specified holiday dates. For example, for weekdays you want most of the VMs to be powered on and by default, on bank holidays, the weekday schedule is applied. To manage such scenarios, use the Autoscale holiday plugin to power off the VMs on specified holiday dates. For more information, see Autoscale holiday plug-in.
Identify machine draining status and reasons
The Get-BrokerMachineV2 PowerShell cmdlet now provides two new properties: IsDraining confirms if a machine is draining and DrainingReason specifies the exact cause. This helps you troubleshoot and manage machine availability effectively. Guest OS draining reasons are applicable only to multi-session machines.
Example: You notice that a multi-session machine, VDA-01, is not accepting new user sessions. You suspect it’s in a draining state. Run Get-BrokerMachineV2 -MachineName "VDA-01" | Select-Object Name, IsDraining, DrainingReason. The output shows IsDraining as True and DrainingReason as AutoscaleScaleDown. This confirms Autoscale initiated the draining state for shutdown. You quickly understand the machine’s status.
For more information, see Drain state.
Exclude draining machines from autoscale calculations
You can now exclude machines undergoing draining due to reboot schedules from Autoscale capacity calculations. This prevents over-provisioning, helping you optimize resource usage. To activate this behavior, set the ExcludeNaturalRebootDrainingFromAutoscale property to True on your multi-session delivery groups.
This feature applies only to:
- Multi-session OS delivery groups.
- Reboot schedules configured with Graceful restart for Cloud or Re-start all machines after draining session for on-premises deployments.
For example, consider a delivery group with 10 active sessions. Two machines are draining for a scheduled reboot. Previously, Autoscale might count these two draining machines as available, potentially leading to over-provisioning of new machines. With this feature, Autoscale recognizes and ignores the draining machines. It only counts the truly available capacity. This ensures your Autoscale policy accurately provisions resources, preventing unnecessary infrastructure costs.
For more information, see Exclude draining machines from autoscale calculations
Citrix Virtual Desktop Assistant application
Enhanced Citrix Virtual Desktop Assistant application
The Citrix Virtual Desktop Assistant application is now enhanced to have the following new features:
- Workstation VDAs: The app is now installed by default. It monitors CPU and memory usage unless launched explicitly to ensure minimal resource usage.
- Server VDAs: App available in the Citrix Virtual Apps and Desktops ISO for convenient installation
- Optimize tile: Redesigned to clearly show memory reclamation details for better resource insights
- Keyboard page: View and manage keyboard settings and sync status.
- USB page: Monitor real-time USB device redirection status.
For more information, see Citrix Virtual Desktop Assistant application.
App Protection
App Protection support for Policy Tampering Detection
Starting with Citrix Virtual Apps and Desktops version 2511, Policy Tampering Detection feature is enabled by default. For more information see Policy Tampering Detection.
Note:
From Citrix Virtual Apps and Desktops version 2511, Session Launches fails if you enable App Protection using the
Default.icafile. Instead enable the policies on the Delivery Group from Delivery Controller using Web Studio or PowerShell. See Configure Anti-keylogging and Anti-screen capture.
Preview features
HDX graphics super resolution for NVIDIA client GPUs
HDX graphics super resolution now also supports compatible client GPUs from NVIDIA.
Enable canary deployment with merge groups
You can now use merge groups to implement a canary deployment model for your application and desktop resources. This feature allows you to publish multiple versions of the same resource while presenting them as a single icon to end users.
Merge groups let you direct specific user groups to different implementation versions of the same resource. You can designate a percentage of users (like 5%) to test a new version while keeping others on the stable version. If issues occur with the new version, you can easily failover users to the stable version without disrupting their experience. This feature supports both high-availability and disaster recovery scenarios without requiring re-enumeration or configuration changes.
For more information, see Enable canary deployment with merge groups.
Profile Management
For information about new features, see the What’s new article in its own document.
Linux VDA
For information about new features, see the What’s new article in its own document.
Session Recording
For information about new features, see the What’s new article in its own document.
Citrix Provisioning™
For information about new features, see the What’s new article in its own document.
Citrix Virtual Delivery Agent for macOS
For information about new features, see the What’s new article in its own document.
Workspace Environment Management™
For information about new features, see the What’s new article in its own document.
Federated Authentication Service
For information about new features, see the What’s new article in its own document.
In this article
- About the release
- Delivery Controller
- HDX
- Virtual Delivery Agents (VDAs)
- Citrix Always on Tracing
- Web Studio
- Citrix Director
- Machine Creation Services™ (MCS)
- Autoscale™
- Citrix Virtual Desktop Assistant application
- App Protection
- Preview features
- Profile Management
- Linux VDA
- Session Recording
- Citrix Provisioning™
- Citrix Virtual Delivery Agent for macOS
- Workspace Environment Management™
- Federated Authentication Service